Деревья в SQL. Часть 1
Coding
Дерево - специальный вид направленного графа. Графы - структуры данных, состоящие из узлов связанных дугами. Кажая дуга показывает однонаправленную связь между двумя узлами. В организационной диаграмме, узлы - сотрудники, а каждая дуга описывает подчинения. В перечне материалов, узлы - модули (в конечном счете, показываемые до индивидуальных частей), и дуги описывают отношение "сделан из".
Вершина дерева называется корнем. В организационной диаграмме, это самый большой начальник; в перечне материалов, это собранная деталь. Двоичное дерево - это дерево, в котором узел может иметь не более двух потомков; В общем случае, n-мерное дерево - то, в котором узел может иметь не больше чем n узлов - потомков.
Узлы дерева, которые не имеют поддеревьев, называются листьями. В перечне материалов, это - минимальные части, на которые может быть разобрана деталь. Потомки, или дети, родительского узла - все узлы в поддереве, имееющего родительский узел коренем.
Деревья часто изображаются как диаграммы.

Другой путь представления деревьев состоит в том, чтобы показывать их как вложенные множеств ;
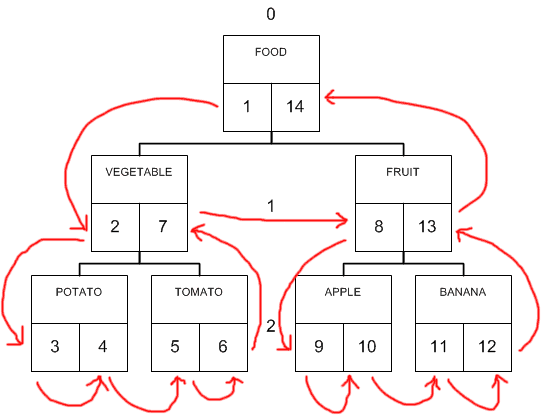
Это основа для используемого мной представления деревьев в SQL в виде вложенных множеств.
В SQL, любые отношения явно явно описываются данными.. Типичный способ представления деревьев состоит в том, чтобы поместить матрицу смежности в таблицу.
Т.е. один столбец - родительский узел, и другой столбец в той же самой строке - дочерний узел (пара представляет собой дугу в графе). Например, рассмотрим организационную диаграмму компании с шестью сотрудниками:
CREATE TABLE Personnel( emp CHAR(20) PRIMARY KEY, boss CHAR(20) REFERENCES Personnel(emp), salary DECIMAL(6,2) NOT NULL ); Personnel: emp boss salary ========================== 'Jerry' NULL 1000.00 'Bert' 'Jerry' 900.00 'Chuck' 'Jerry' 900.00 'Donna' 'Chuck' 800.00 'Eddie' 'Chuck' 700.00 'Fred' 'Chuck' 600.00
Эта модель имеет преимущества и недостатки. ПЕРВИЧНЫЙ КЛЮЧ - emp, но столбец boss - функционально зависит от него, следовательно мы имеем проблемы с нормализацией.
REFERENCES не даст вам возможность указать начальником, того кто не является сотрудником. Однако, что произойдет, когда 'Jerry' изменяет имя на 'Geraldo', чтобы получить телевизионное ток-шоу? Вы также должны сделать каскадные изменения в строках 'Bert' и 'Chuck'.
Другой недостаток этой модели - то трудно вывести путь. Чтобы найти имя босса для каждого служащего, используется самообъединяющийся запрос, типа:
SELECT B1.emp, 'bosses', E1.emp FROM Personnel AS B1, Personnel AS E1 WHERE B1.emp = E1.boss;
Но кое-что здесь отсутствует. Этот запрос дает Вам только непосредственных начальников персонала. Босс Вашего босса также имеет власть по отношению к Вам, и так далее вверх по дереву.
Чтобы вывести два уровня в дереве, Вам необходимо написать более сложный запрос самообъединения, типа:
SELECT B1.emp, 'bosses', E2.emp FROM Personnel AS B1, Personnel AS E1, Personnel AS E2 WHERE B1.emp = E1.boss AND E1.emp = E2.boss;
Чтобы идти более чем на два уровня глубже в дереве, просто расширяют образец:
SELECT B1.emp, 'bosses', E3.emp FROM Personnel AS B1, Personnel AS E1, Personnel AS E2, Personnel AS E3 WHERE B1.emp = E1.boss AND E1.emp = E2.boss AND E2.emp = E3.boss;
К сожалению, Вы понятия не имеете насколько глубоко дерево, так что Вы должны продолжать расширять этот запрос, пока Вы не получите в результате пустое множество.
Листья не имеют потомков. В этой модели, их довольно просто найти: Это сотрудники, не являющиеся боссом кому либо еще в компании:
SELECT *
FROM Personnel AS E1
WHERE NOT EXISTS(
SELECT *
FROM Personnel AS E2
WHERE E1.emp = E2.boss);
У корня дерева boss - NULL:
SELECT * FROM Personnel WHERE boss IS NULL;
Реальные проблемы возникают при попытке вычислить значения вверх и вниз по дереву. Как упражнение, напишите запрос, суммирующий жалованье каждого служащего и его/ее подчиненных; результат:
Total Salaries emp boss salary ========================== 'Jerry' NULL 4900.00 'Bert' 'Jerry' 900.00 'Chuck' 'Jerry' 3000.00 'Donna' 'Chuck' 800.00 'Eddie' 'Chuck' 700.00 'Fred' 'Chuck' 600.00
Множественная модель деревьев.
Другой путь представления деревьев состоит в том, чтобы показать их как вложенные множества. Это более подходящая модель, т.к. SQL - язык, ориентированный на множества.
Корень дерева - множество, содержащее все другие множества, и отношения предок-потомок описываются принадлежностью множества потомков множеству предка.
Имеются несколько способов преобразования организационной диаграммы во вложенные наборы.
Один путь состоит в том, чтобы вообразить, что Вы перемещаете подчиненные "овалы" внутри их родителей, использующих линии края как веревки.
Корень - самый большой овал и содержит все другие узлы. Листья - самые внутренние овалы, ничего внутри не содержащие, и вложение соответствует иерархическим отношениям.
Это - естественное представление модели "перечень материалов", потому что заключительный блок сделан физически из вложенных составляющих, и разбирается на отдельные части.
Другой подход состоит в том, чтобы представить небольшой червь, ползающий по "узлам и дугам" дерева. Червь начинает сверху, с кореня, и делает полную поездку вокруг дерева.
Но теперь давайте представим более сильный червь со счетчиком, который начинается с единицы. Когда червь прибывает в узел, он помещает число в ячейку со стороны, которую он посетил и увеличивает счетчик. Каждый узел получит два номера, один для правой стороны и один для левой стороны.
Это дает предсказуемые результаты, которые Вы можете использовать для формирования запросов. Таблица Personnel имеет следующий вид, с левыми и правыми номерами в виде:
CREATE TABLE Personnel( emp CHAR(10) PRIMARY KEY, salary DECIMAL(6,2) NOT NULL, left INTEGER NOT NULL, right INTEGER NOT NULL); Personnel emp salary left right ============================== 'Jerry' 1000.00 1 12 'Bert' 900.00 2 3 'Chuck' 900.00 4 11 'Donna' 800.00 5 6 'Eddie' 700.00 7 8 'Fred' 600.00 9 10
Корень всегда имеет 1 в левом столбце и удвоенное число узлов (2*n) в правом столбце. Это просто понять: червь должен посетить каждый узел дважды, один раз с левой стороны и один раз с правой стороны, так что заключительный количество должено быть удвоенное число узлов во всем дереве.
В модели вложенных множеств, разность между левыми и правыми значениями листьев - всегда 1. Представте червя, поворачивающегся вокруг листа, пока он ползет по дереву. Поэтому, Вы можете найти все листья следующим простым запросом:
SELECT * FROM Personnel WHERE (right - left) = 1;
Вы можете использовать такую уловку, для ускорения запросов: постройте уникальный индекс по левому столбцу, затем перепишите запрос, чтобы воспользоваться преимуществом индекса:
SELECT * FROM Personnel WHERE left = (right - 1);
Причина увеличения производительности в том, что SQL может использовать индекс по левому столбцеу, когда он не испорльзуется в выражении. Не используйте (left - right) = 1, потому что это дает воспользоваться преимуществами индекса.
В модели вложенных - имножеств, пути показываются как вложенные множества, которые представлены номерами вложенных множеств и предикатами BETWEEN. Например, чтобы определить всех боссов определенного сотрудника необходимо написать:
SELECT :myworker, B1.emp, (right - left) AS height FROM Personnel AS B1, Personnel AS E1 WHERE E1.left BETWEEN B1.left AND B1.right AND E1.right BETWEEN B1.left AND B1.right AND E1.emp = :myworker;
Чем больше height, тем дальше по иерархии босс от служащего. Модель вложенных множеств использует факт, что каждое содержащее другие множество является большим в размере (где размер = (right - left)) чем множества, в нем содержащиеся. Очевидно, корень будет всегда иметь самый большой размер.
Уровень, число дуг между двумя данными узлами, довольно просто вычислить. Например, чтобы найти уровни между заданным рабочим и менеджером, Вы могли бы использовть:
SELECT E1.emp, B1.emp, COUNT(*) - 1 AS levels FROM Personnel AS B1, Personnel AS E1 WHERE E1.left BETWEEN B1.left AND B1.right AND E1.right BETWEEN B1.left AND B1.right AND E1.node = :myworker AND B1.node = :mymanager;
(COUNT(*) - 1) используется для того, чтобы удалить двойной индекс узла непосредственно как нахождение на другом уровне, потому что узел - нулевые уровни, удаленные из себя.
Вы можете построить другие запросы из этого шаблона. Например, чтобы найти общих боссов двух служащих, объединяют пути и находят узлы который имеют (COUNT(*) > 1). Чтобы найти самых близких общих предков двух узлов, объединяют пути, находят узлы, которые имеют (COUNT(*) > 1), и выбирают с наименьшей глубиной.
Подписывайтесь на канал и делитесь им с друзьями