🌳 Деревья: от теории к практике
@iksergeyruВ соответствии с моделью, каждый узел дерева хранит своих потомков и какие-то полезные данные. Опишем это кодом:

У каждого узла может быть множество дочерних узлов Children, полезные данные Value.
Для удобства опишем модель дерева.
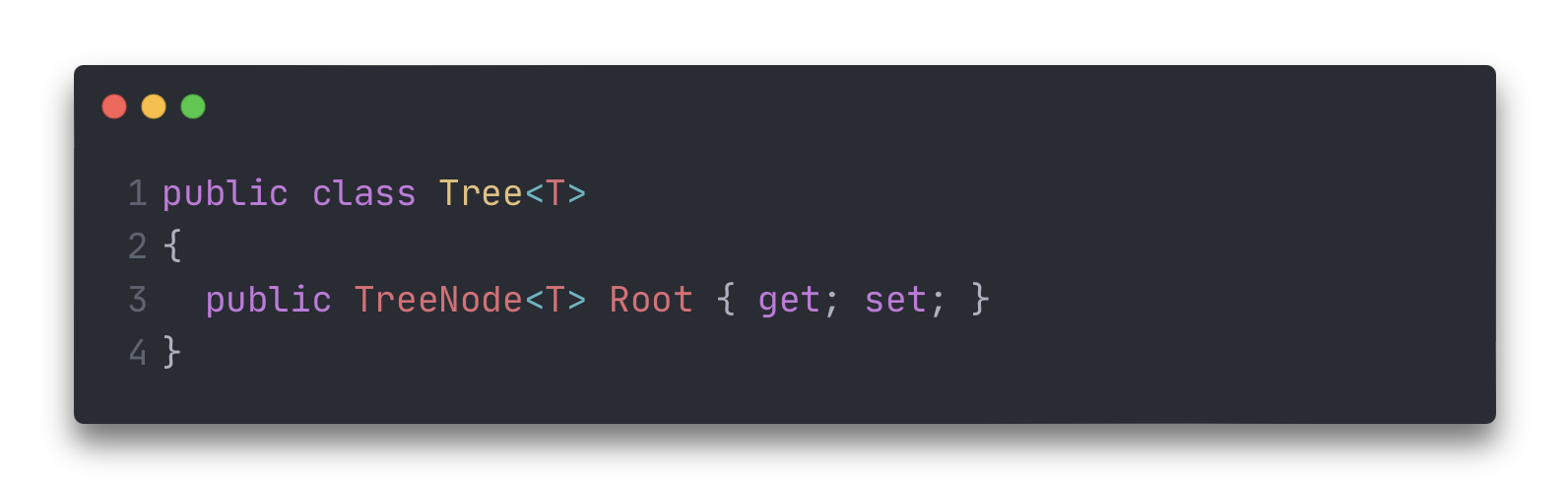
В дальнейшем именно этот класс будет обзаводиться новым функционалом.
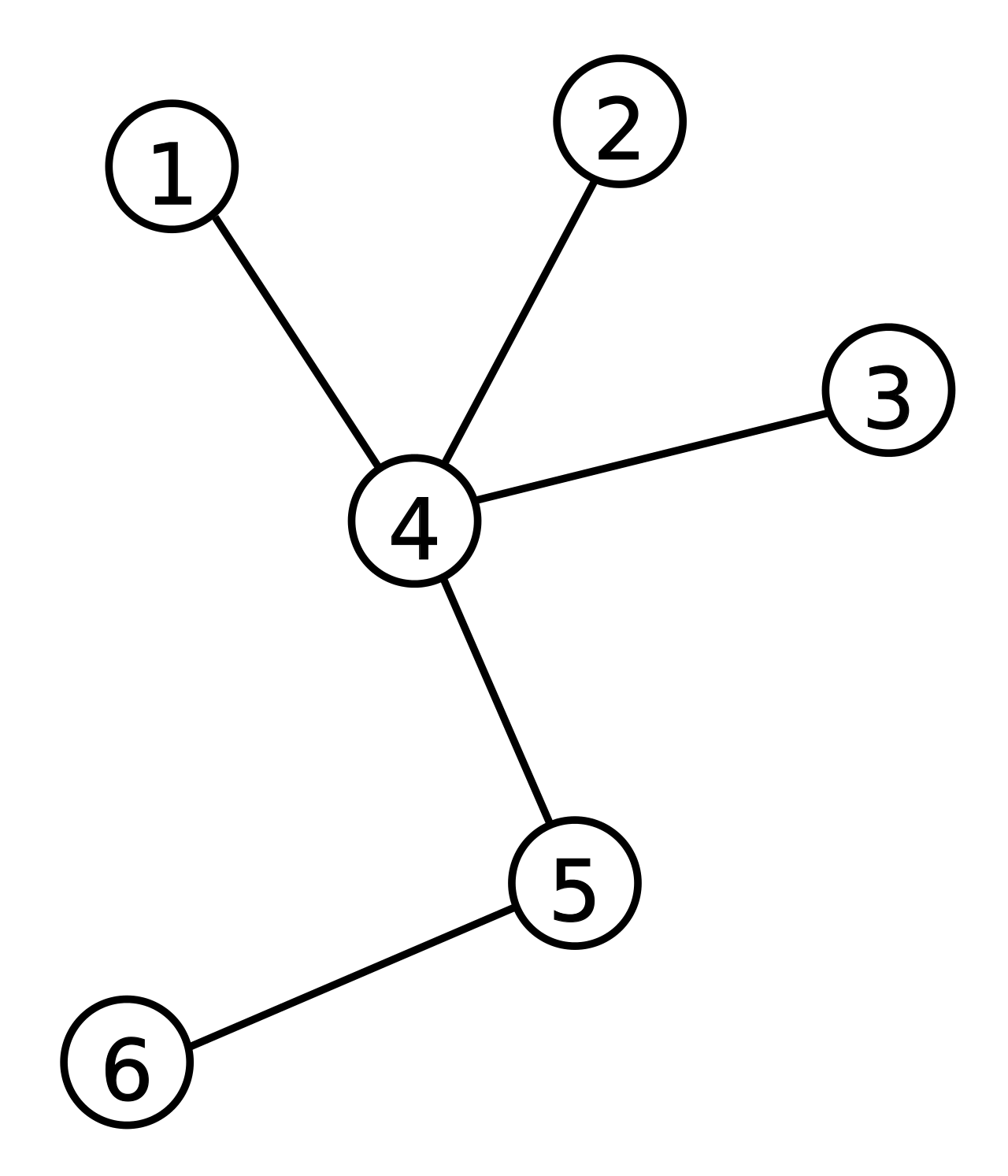
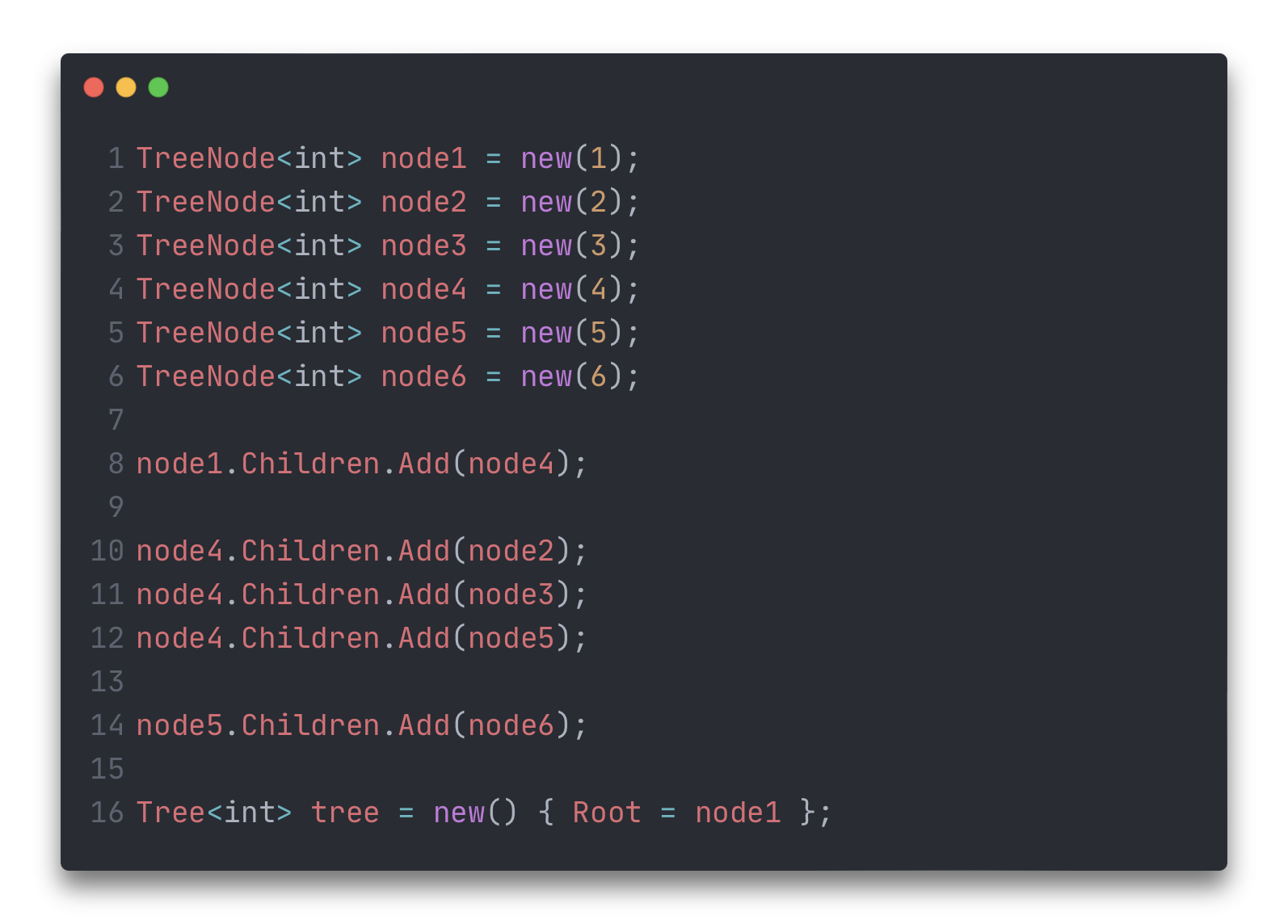
"Соберем" дерево, представленное на рисунке 1. В качестве "корня" можно выбрать любой узел. Для определённости пусть это будет узел 1.
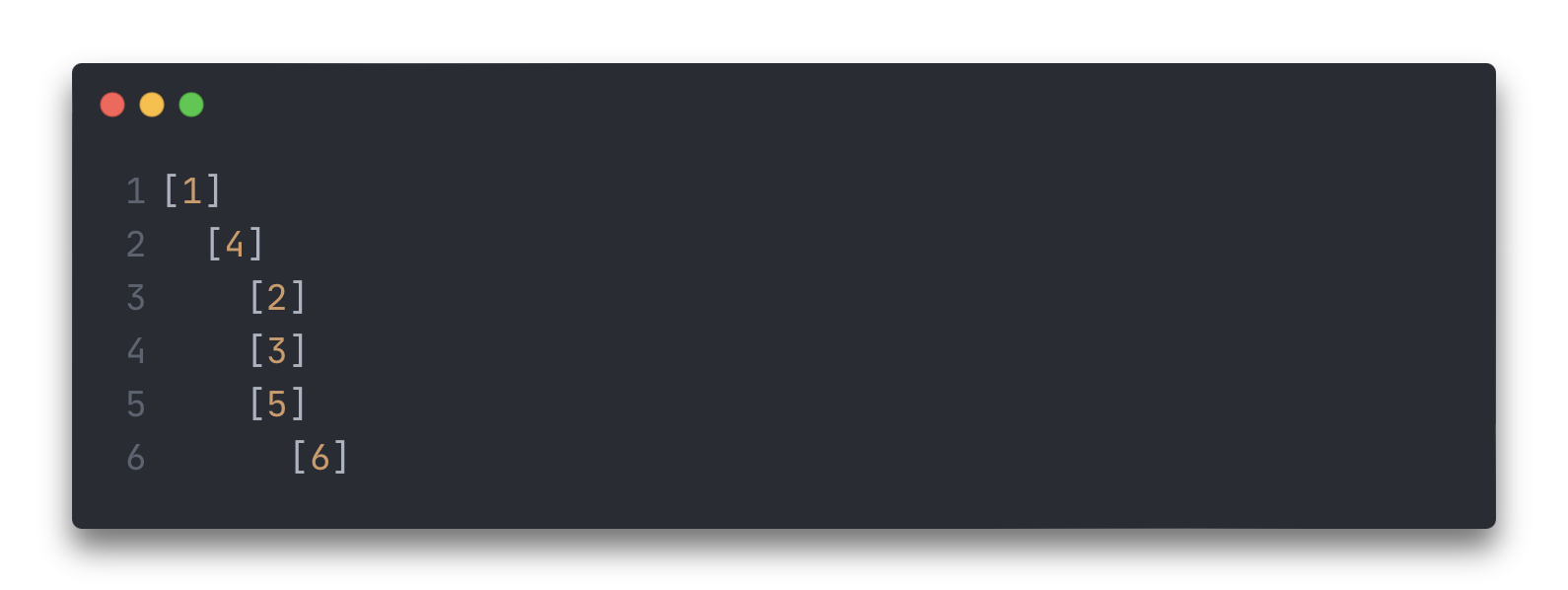
Для проверки опишем метод печати. Сделаем вывод так, чтобы можно было наблюдать иерархическую структуру.
[1]
[4]
[2]
[3]
[5]
[6]
Для этого добавим в класс Tree<T> два метода:

В клиентском коде добавим вызов метода Print()

Добавим в класс Tree<T> переопределение метода ToString() для более компактной печати.
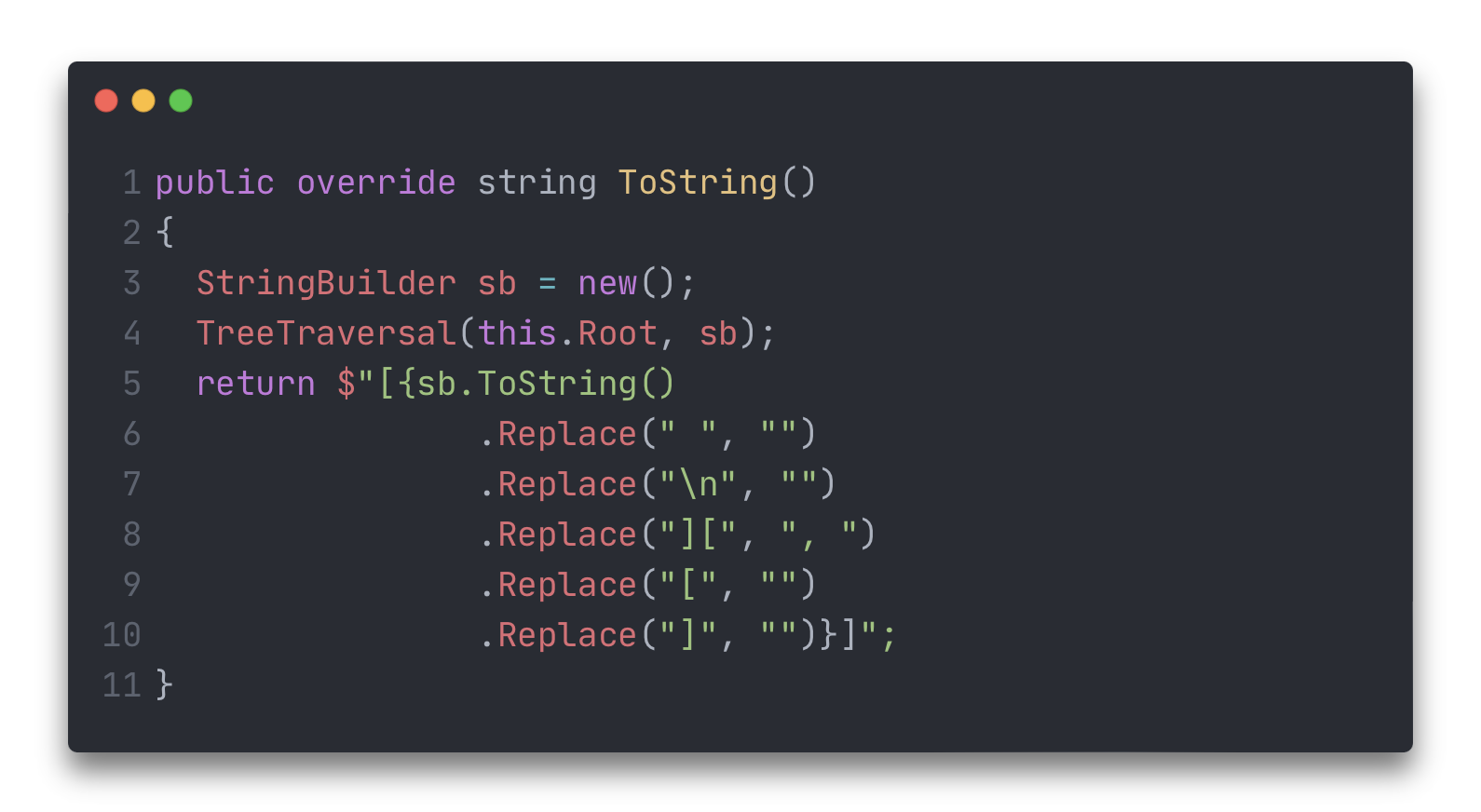
Теперь быструю печать можно вызвать Console.WriteLine(tree);, а в терминале получить [1, 4, 2, 3, 5, 6].
Бинарные деревья
С представлением обычных деревьев, думаю, всё понятно. Есть деревья у которых не более двух потомков. Такие деревья называются "Двоичными деревьями" или "Бинарными деревьями".
Описать модель узла бинарного дерева можно так:

Главное отличие в дальнейшей работе с таким деревом заключается лишь в количестве потомков – их не любое количество, а всегда два. Один условно "левый" и второй – условно "правый".

Учитывая только два возможных потомка, для такого дерева существует несколько общепринятых вариантов обхода:
- Pre-order (прямой обход или корень-левый-правый)
- In-order (центрированный обход или левый-корень-правый)
- Post-order (обратный обход или левый-правый-корень)
Помимо них на практике встречаются такие варианты обхода:
- Reverse pre-order (корень-правый-левый)
- Reverse post-order (правый-левый-корень)
- Reverse in-order (правый-корень-левый)

Замечание: для получения любого из оставшихся пяти способов обхода достаточно переставлять строки 13-15.
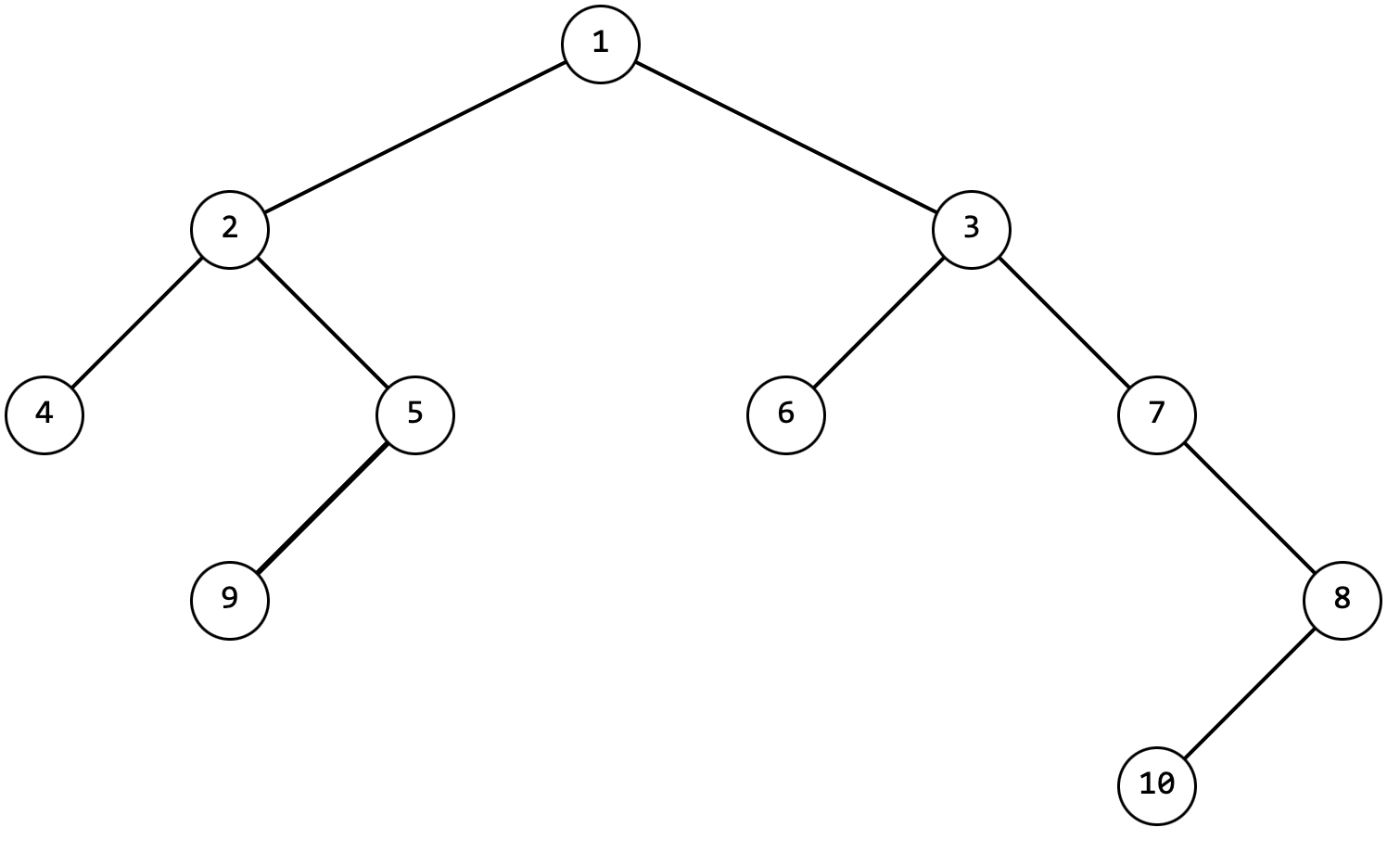
Иногда бинарные деревья представляют "скобочной" записью
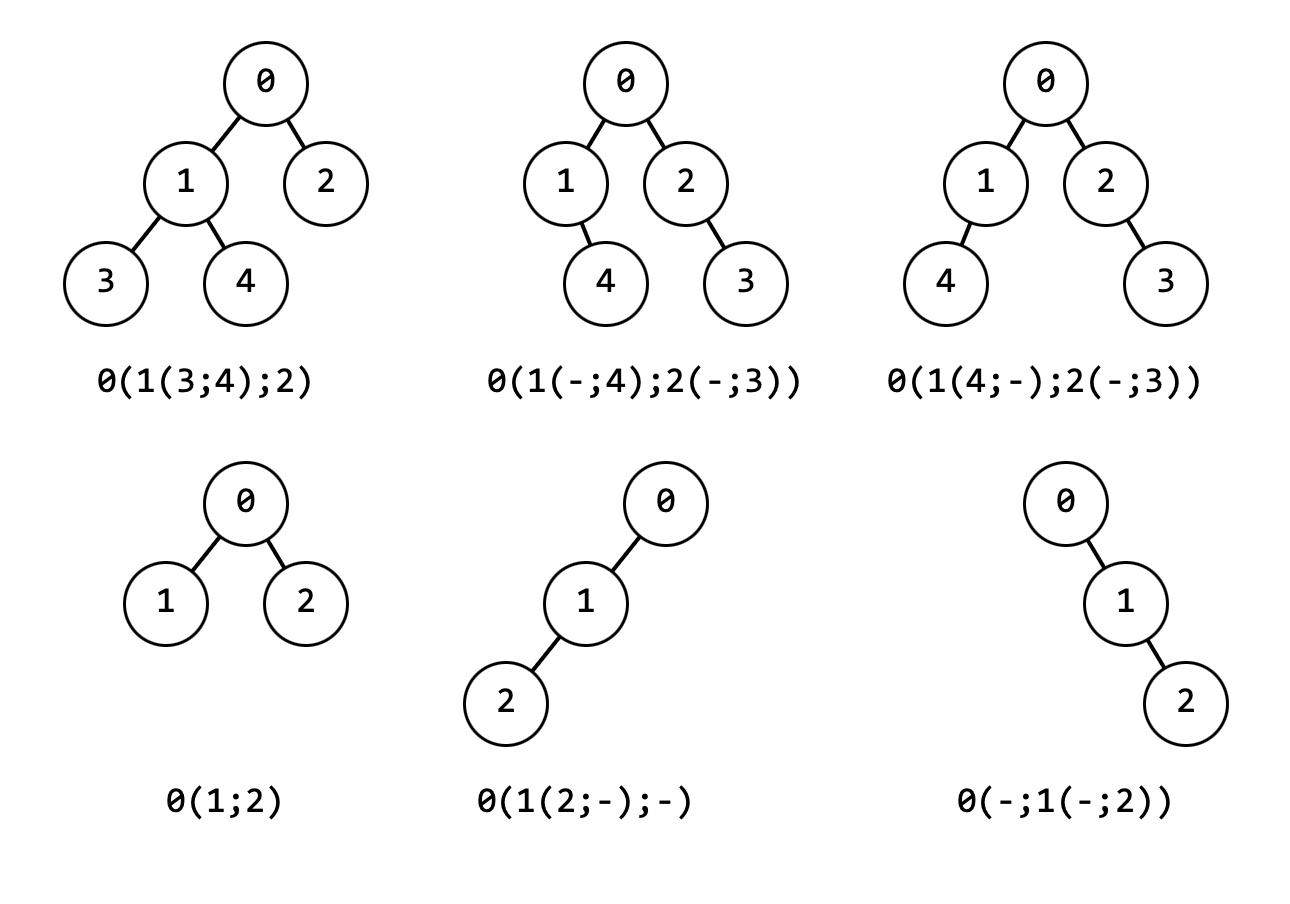
В основу такого представления ложится прямой обход, с добавлением скобок
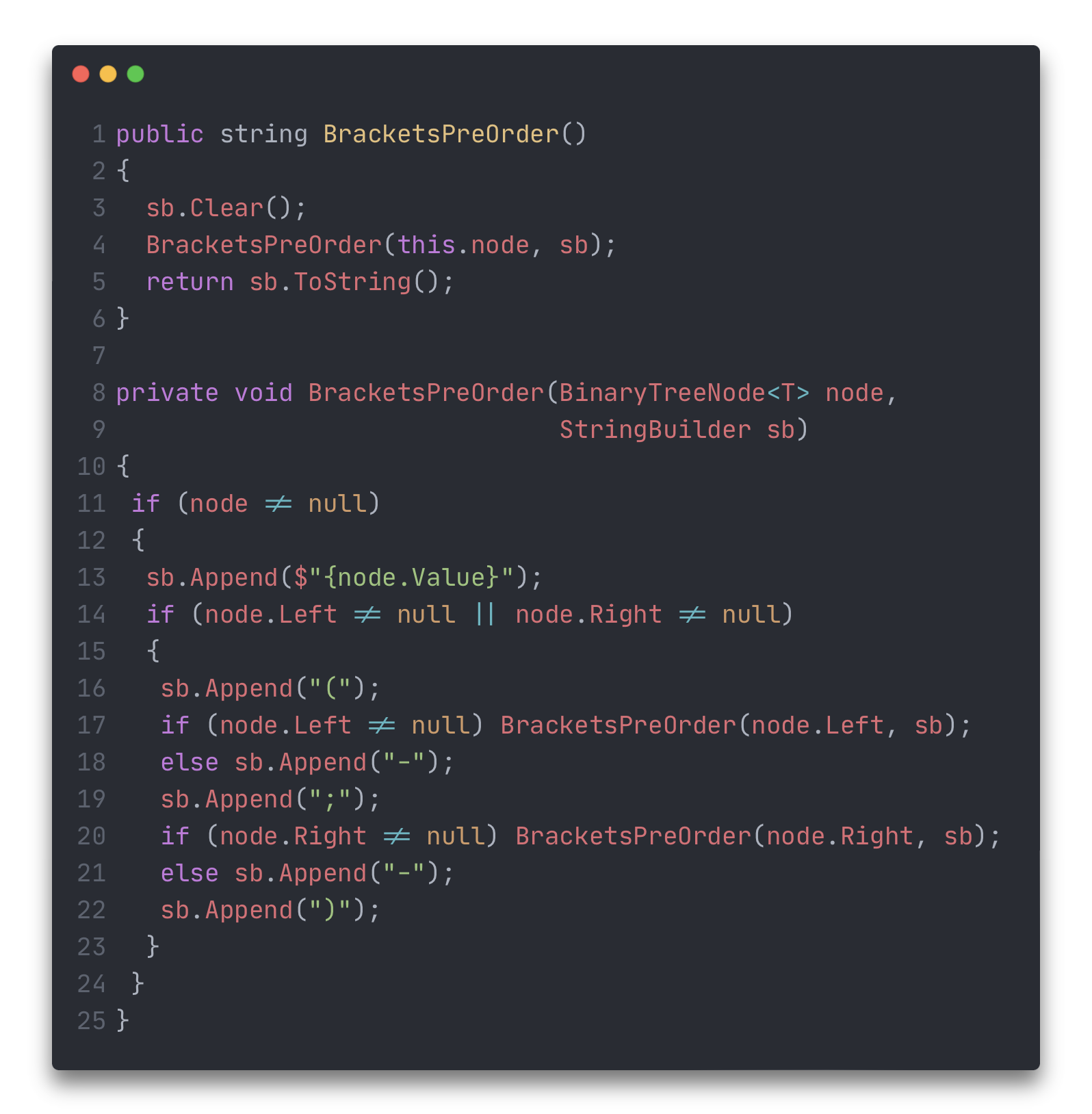
Применив этот код к дереву, изображенному на рисунке 2 получим запись: 1(2(4;5(-;9));3(6;7(-;8(10;-))))
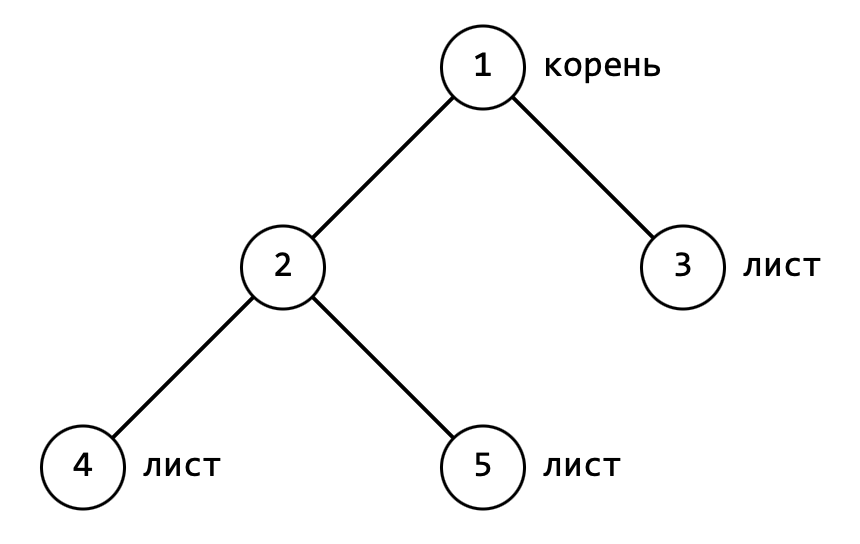
Замечание: в деревьях некоторые узлы имеют специальные названия. Узел, находящийся в самом верху иерархии часто называют корнем, а узлы, находящиеся в самом низу иерархии часто называют листьями.
Узел 1 является родительским (предком) по отношению к узлам 2 и 3. Узлы 2 и 3 являются дочерними (потомками) по отношению к узлу 1. Узлы 4 и 5 – потомки по отношению к узлу 2, узел 2 – предок для узлов 4 и 5.
Бинарные деревья поиска
Бинарное дерево становится бинарным деревом поиска если выполняются следующие условия:
- Если в дереве нет ни одного элемента (узла), то добавляемый узел становится корневым элементом (корнем).
- Если добавляемый элемент меньше корневого – идём налево. При достижении узла, у которого левый потомок пуст – делаем добавляемый элемент левым потомком.
- Если добавляемый элемент больше корневого – идём направо. При достижении узла, у которого правый потомок пуст – делаем добавляемый элемент правым потомком.

Замечание: при описании простого бинарного дерева поиска, часто левое поддерево содержит элементы меньше корневого, а правое содержит элементы, которые больше или равны корневому. В рамках этого примера я допускаю добавление только уникальных элементов.
Замечание: для того, чтобы ввести отношение больше/меньше тип, которым будет закрываться обобщённый тип <Т> должен содержать реализацию компаратора. В рамках текущей реализации результат работы компаратора такой:10.CompareTo(20) = -1, 20.CompareTo(10) = 1, 10.CompareTo(10) = 0.
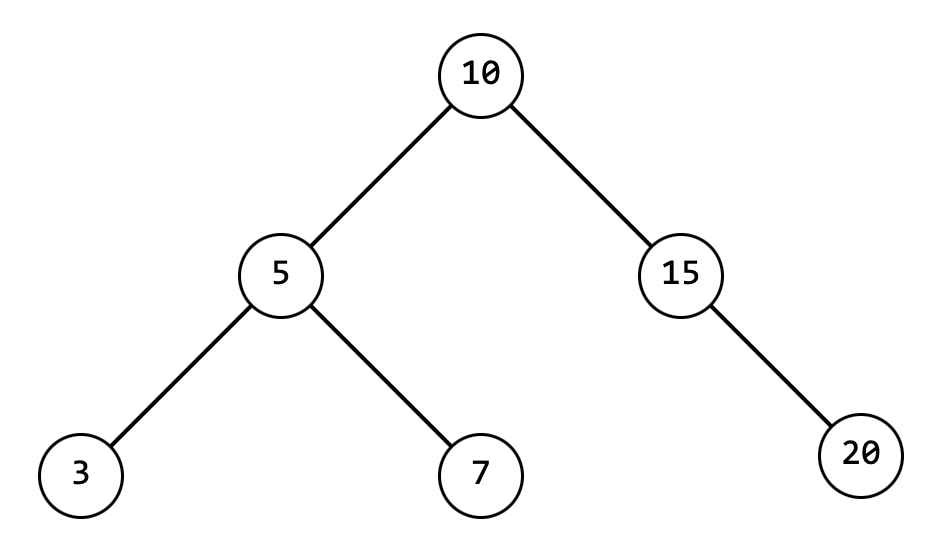
Если последовательно вызвать метод Append с аргументами 10, 5, 15, 3, 7, 20 будет сформировано такое дерево:
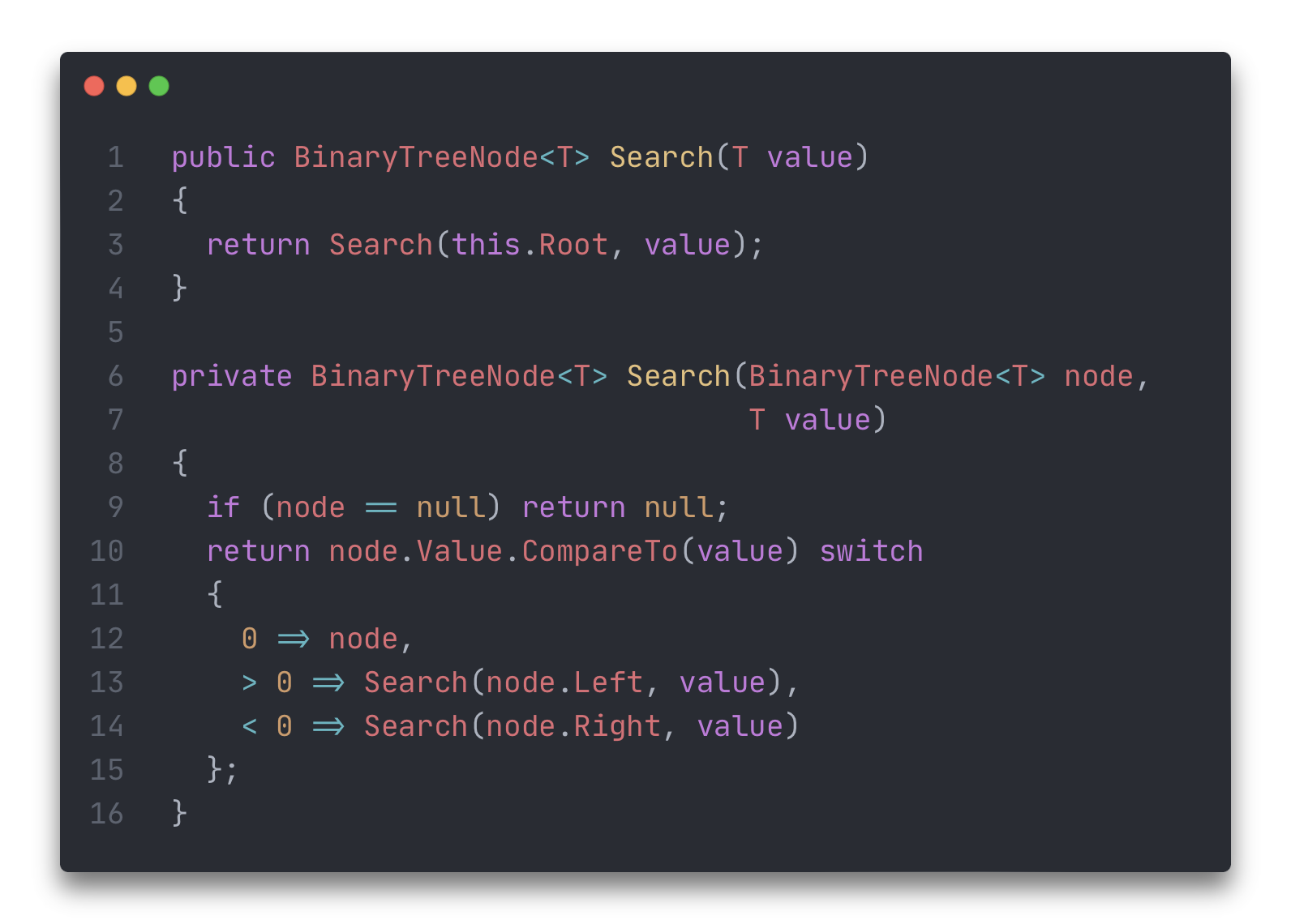
Добавим метод поиска нужного элемента. Правило простое: если искомое значение совпало со значением корня – элемент найден, если искомое значение меньше значения в корне – просматриваем левое поддерево, если искомое значение больше значения в корне – просматриваем правое поддерево.
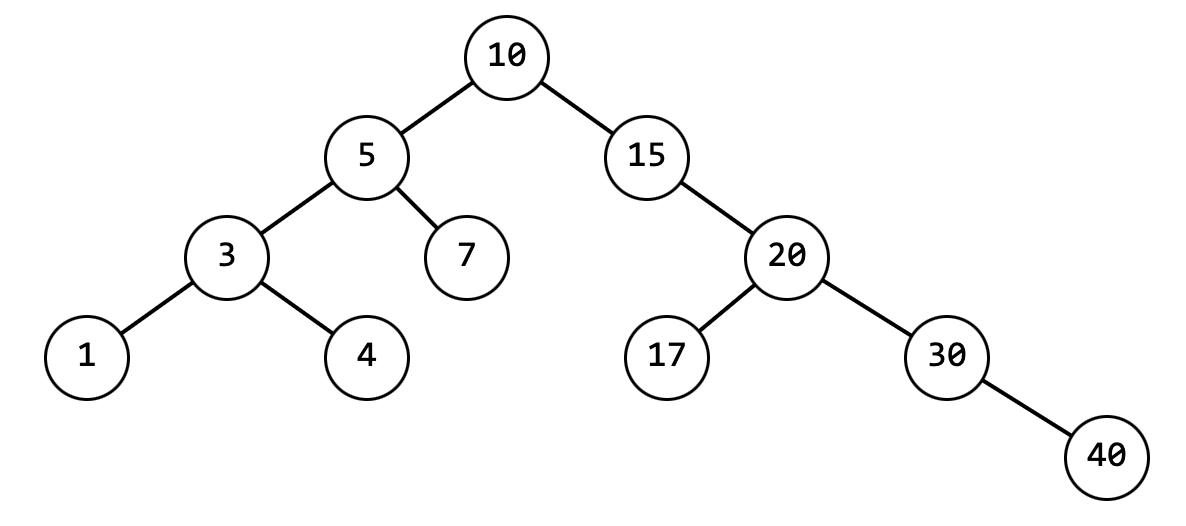
Для дерева, изображенного на рисунке 5, результат поиска будет выглядеть так
Результат
(10, True) (20, True) (30, False) (3, True) (6, False) (9, False)
Элементы 30, 6, 9 не найдены.
Замечание: очевидно, что на основе метода Search можно легко построить метод Contains проверки наличия элемента в дереве.
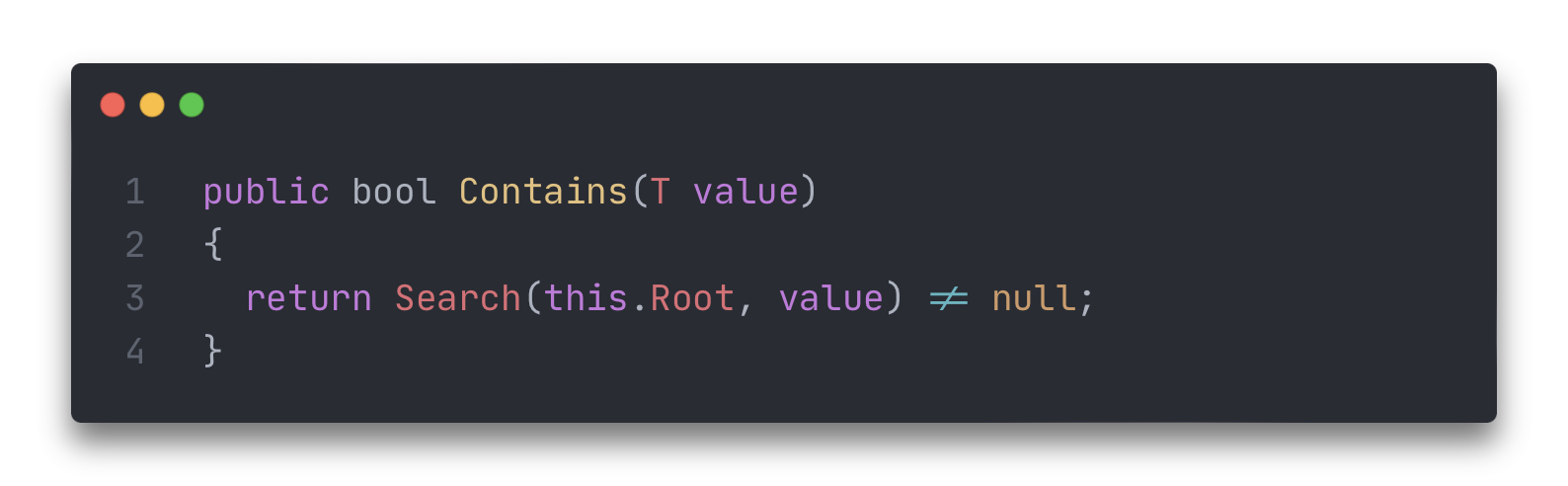
Любопытный факт: если мы строим бинарное дерево поиска, то легко можно отыскать самый минимальный и самый максимальный элемент.
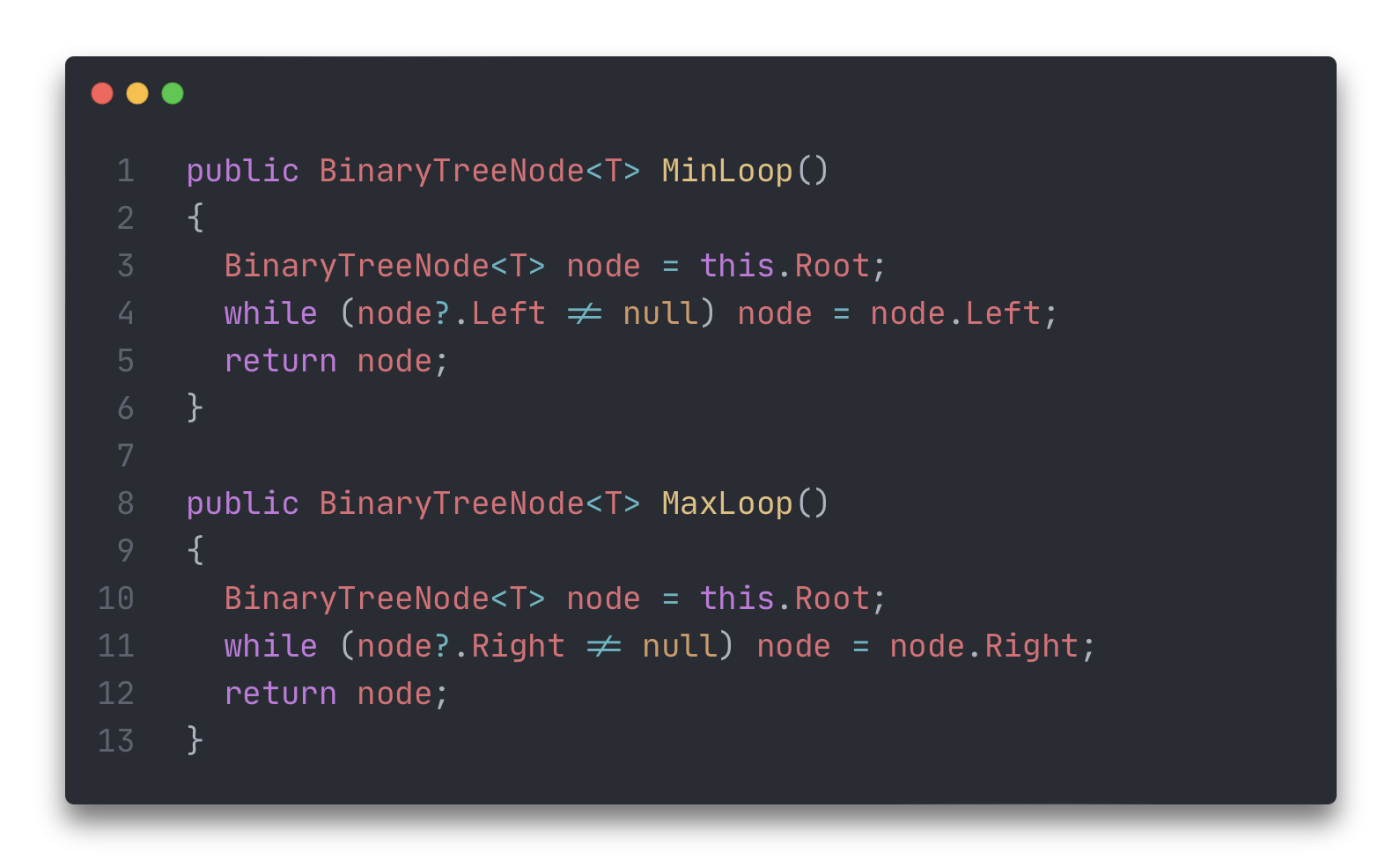
Минимальный будет самым левым потомком.
Максимальный будет самым правым потомком.
Пример реализации метода поиска узлов, содержащих минимальный и максимальный элементы при помощи циклов. В качестве тренировки, попробуйте реализовать эти методы при помощи рекурсии.
Удаление в бинарном дереве поиска
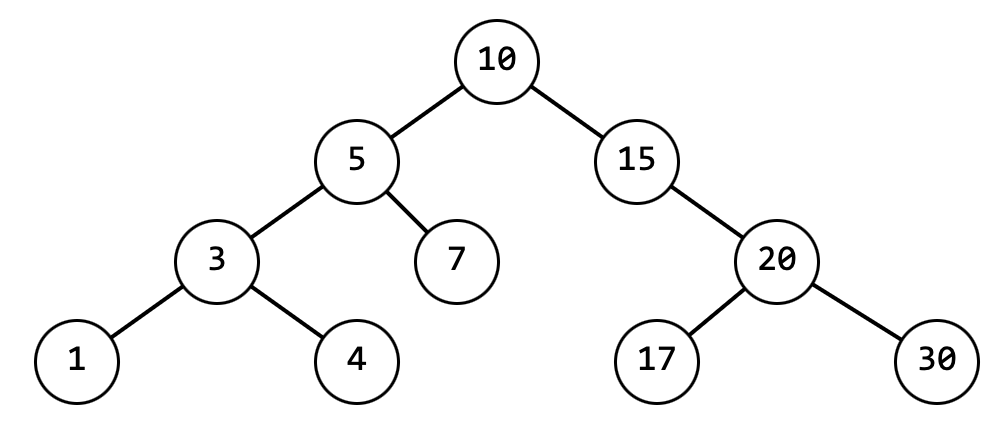
С добавлением и поиском вроде бы разобрались, но что делать если нужно что-то удалить? Тут всё не так просто, так как если в дереве, изображенном на рисунке 7, для удаления узла со значением 1, достаточно заменить его на null, но так нельзя сделать если нам требуется удалить узел со значением 5.
Если проанализировать, то можно получить три возможных ситуации при необходимости удаления узла, а именно:
У удаляемого узла:
- Нет ни одного потомка
- Есть левый или правый потомок
- Есть левый и правый потомок
В зависимости от того какая ситуация, нужно реагировать разными способами. Рассмотрим каждый из них:
- Нет ни одного потомка:
В этом случае достаточно заменить удаляемый узел наnull, так как он является листом и никаких проблем с потерей данных быть не может
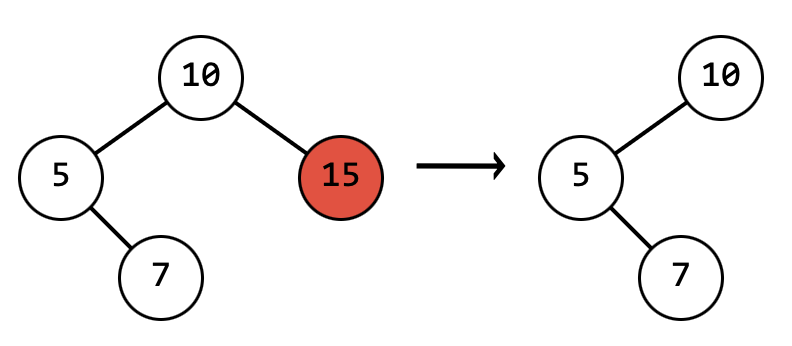
- Есть левый или правый потомок:
В этом случае необходимо заменить удаляемый узел на этого потомка
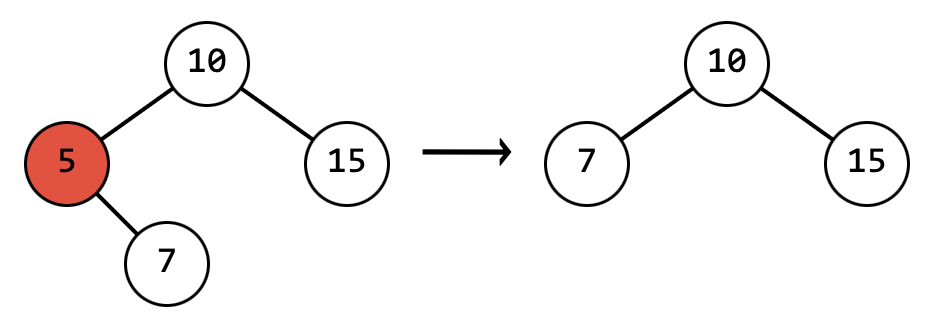
- Есть левый и правый потомок:
В этом случае на место удаляемого узла должен придти узел, который будет больше чем всё левое поддерево или узел, который меньше чем всё правое поддерево
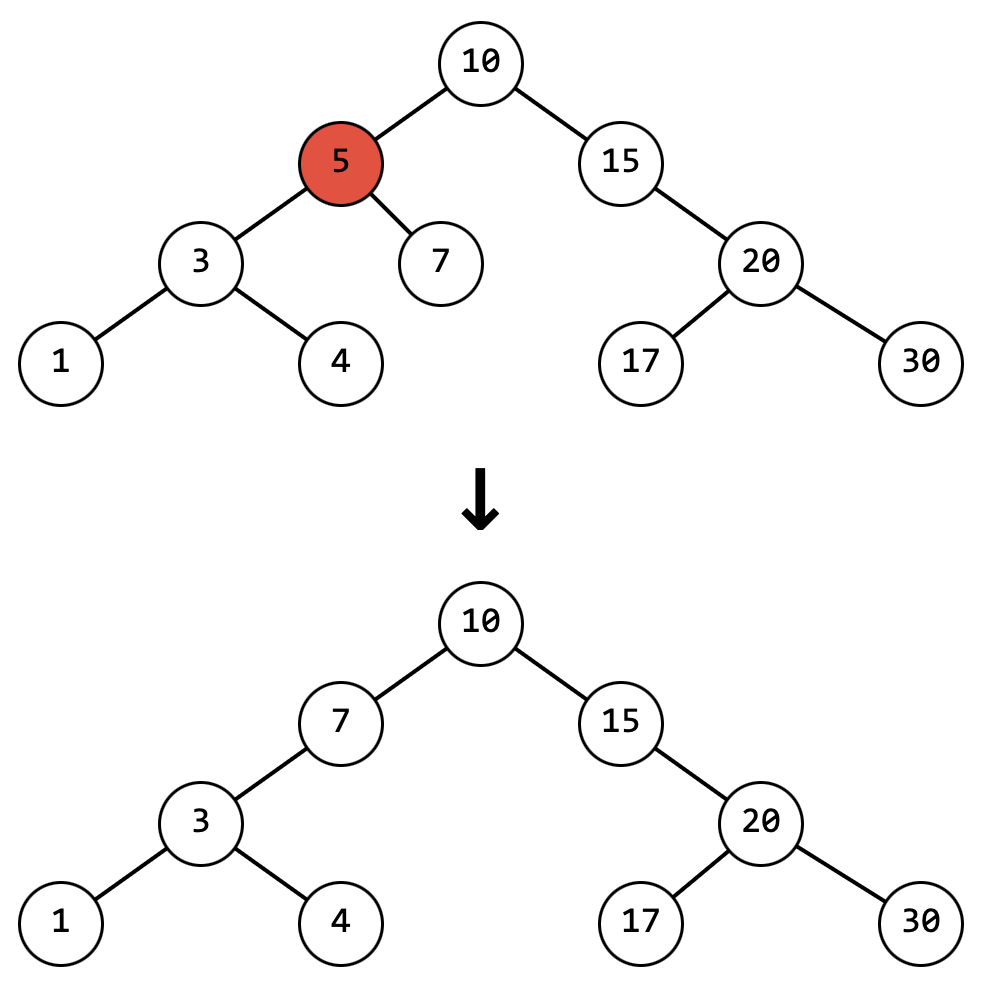
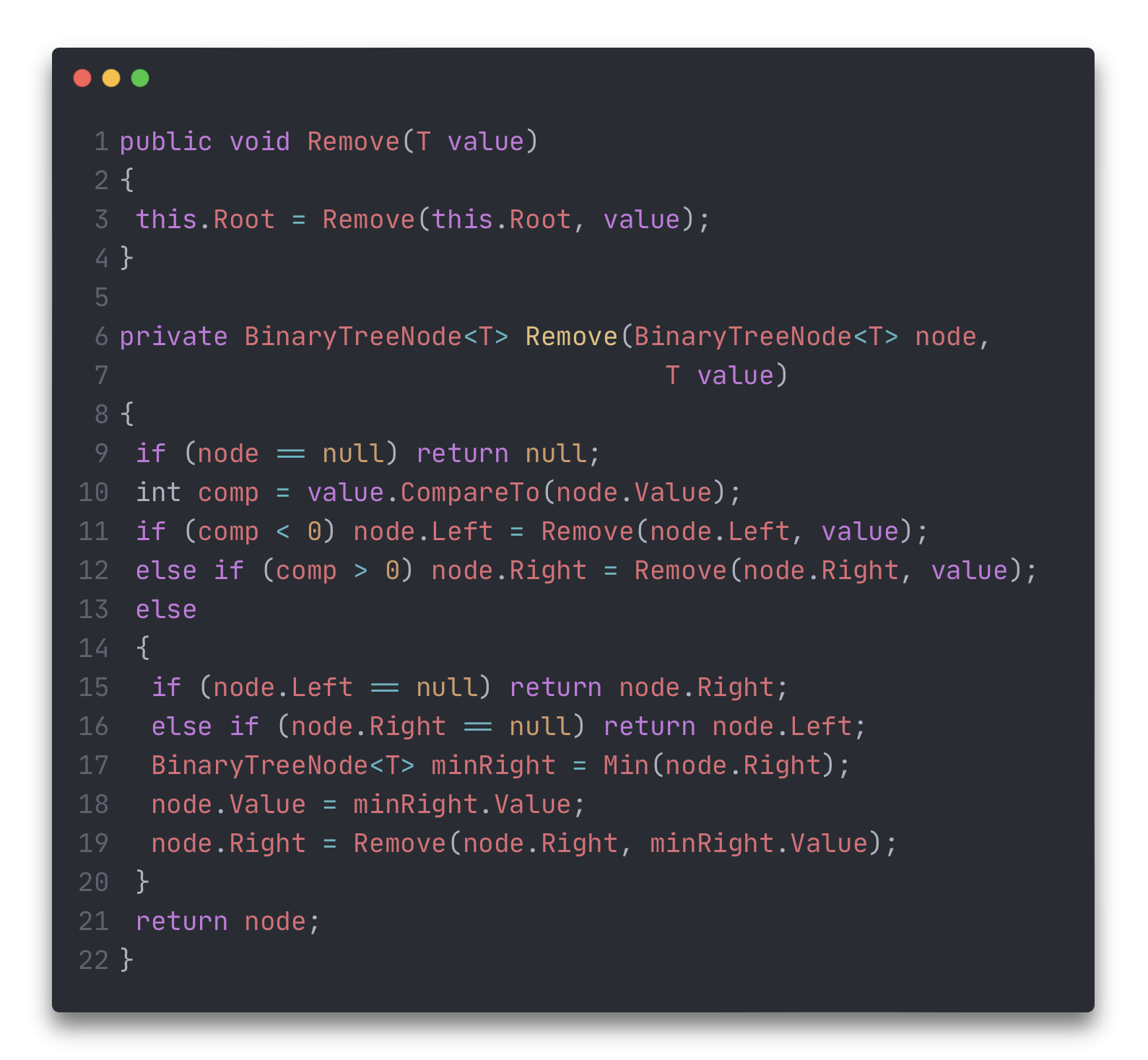
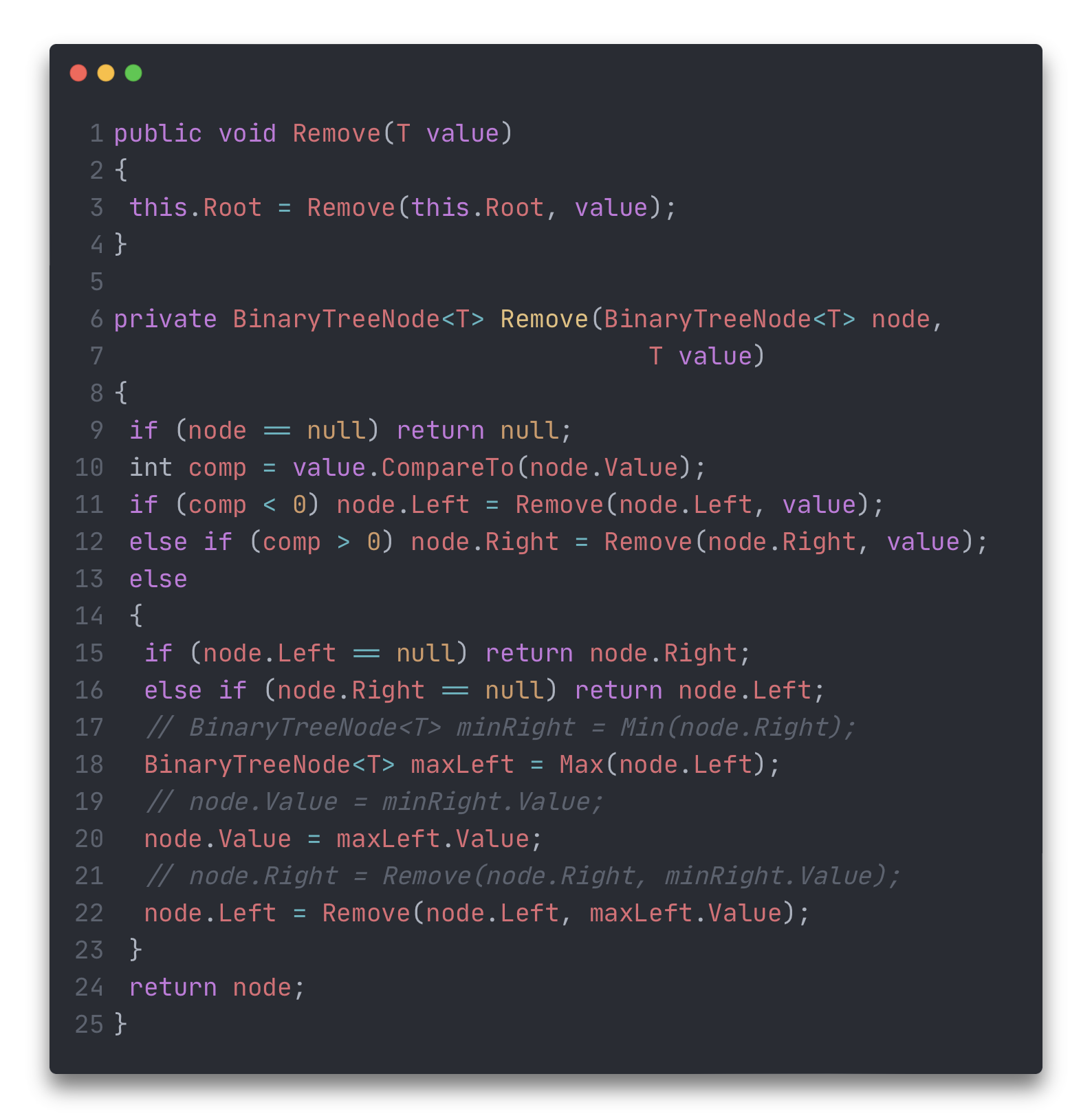
Весь метод с учётом двух предыдущих случаев будет выглядеть так:
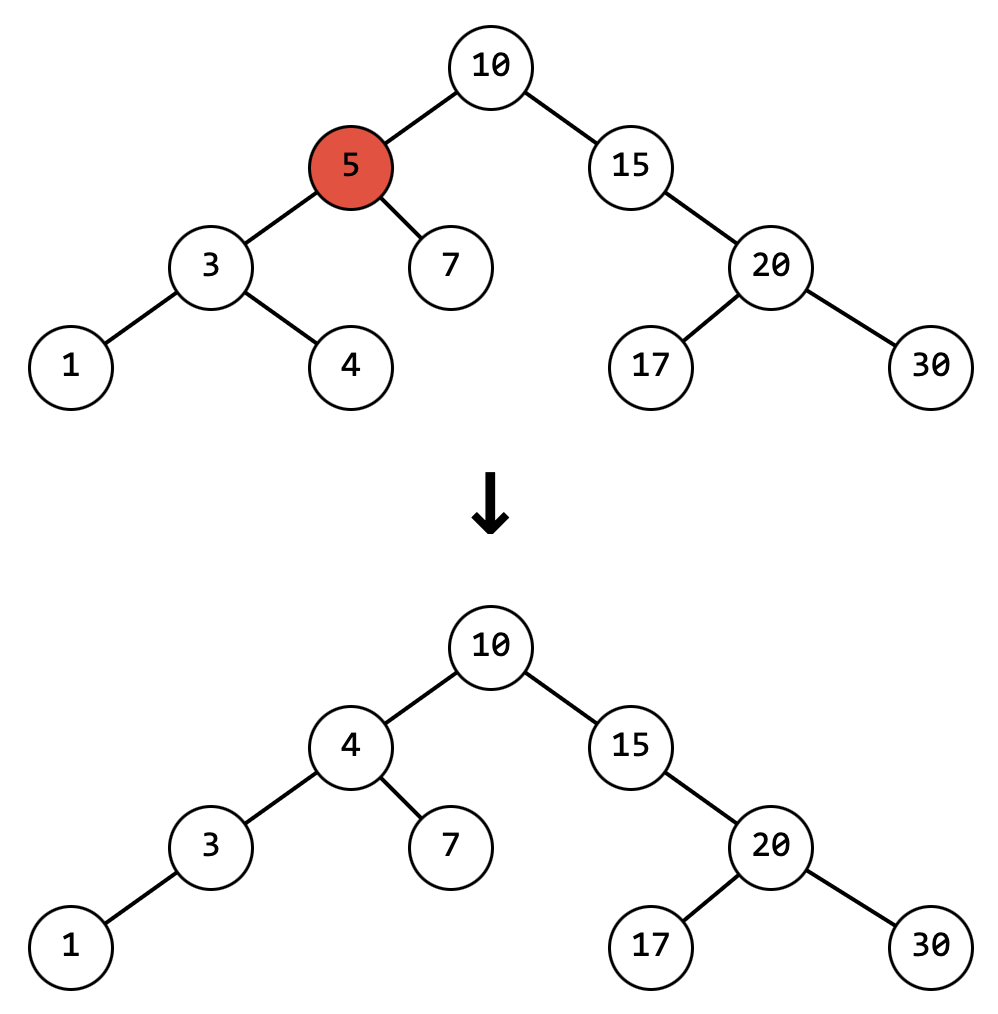
Любопытный факт с обходами
При помощи центрированного обхода в бинарном дереве поиска можно получить вывод элементов в порядке возрастания.
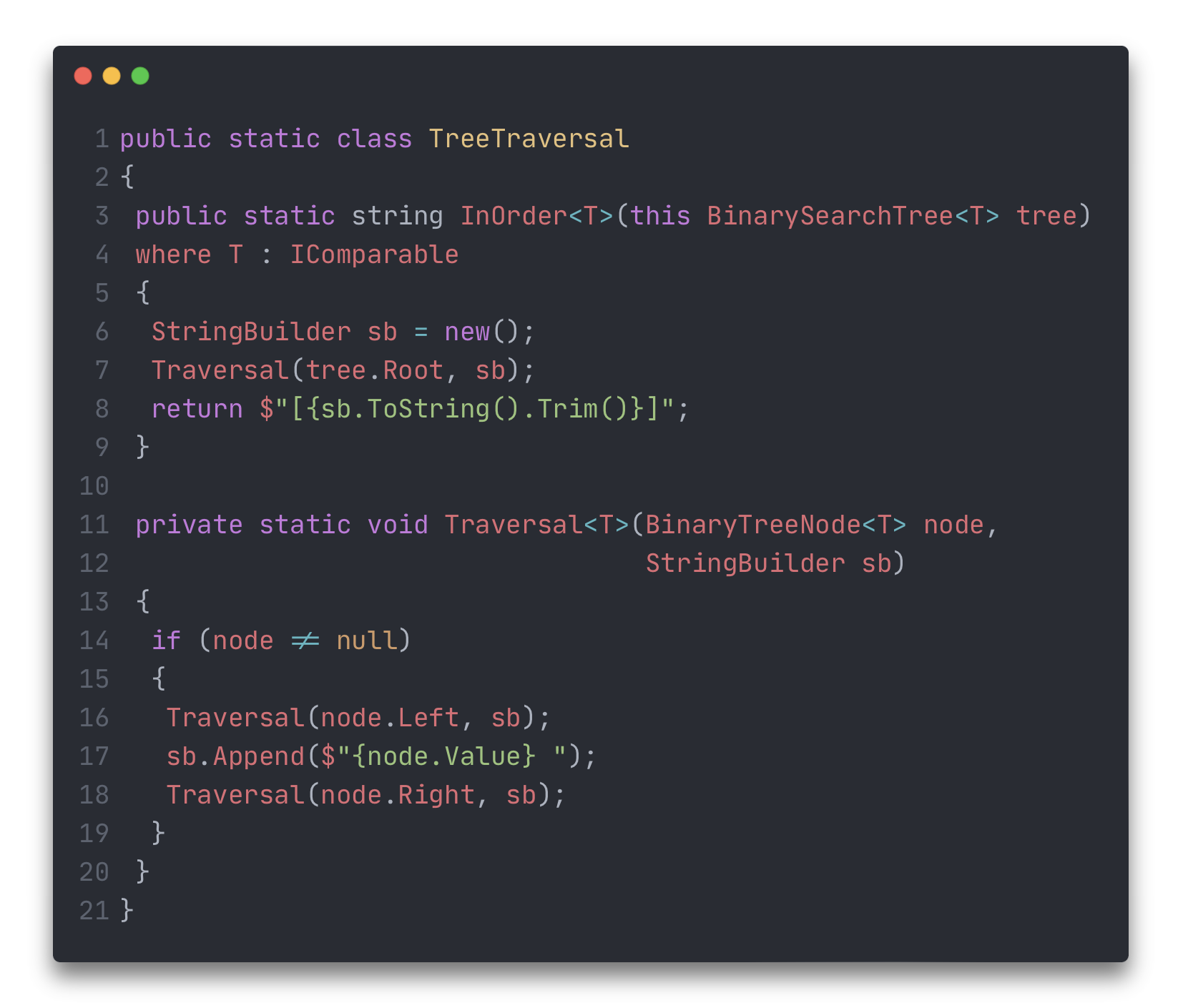
При помощи обратного обхода дерево лучше всего удалять.
При помощи прямого обхода дерево лучше всего копировать.
Промежуточные итоги и проблемы
Мы реализовали операции: добавления, удаления, чтения данных в рамках нашей структуры данных. Операцию обновления данных реализовать не составит труда, так как достаточно найти нужный элемент и изменить данные в нём.
Какое дерево получится, если в него добавлять элементы такой последовательности: 1, 2, 3, 5, 8, 13, 21, 34?
Получится такое дерево:
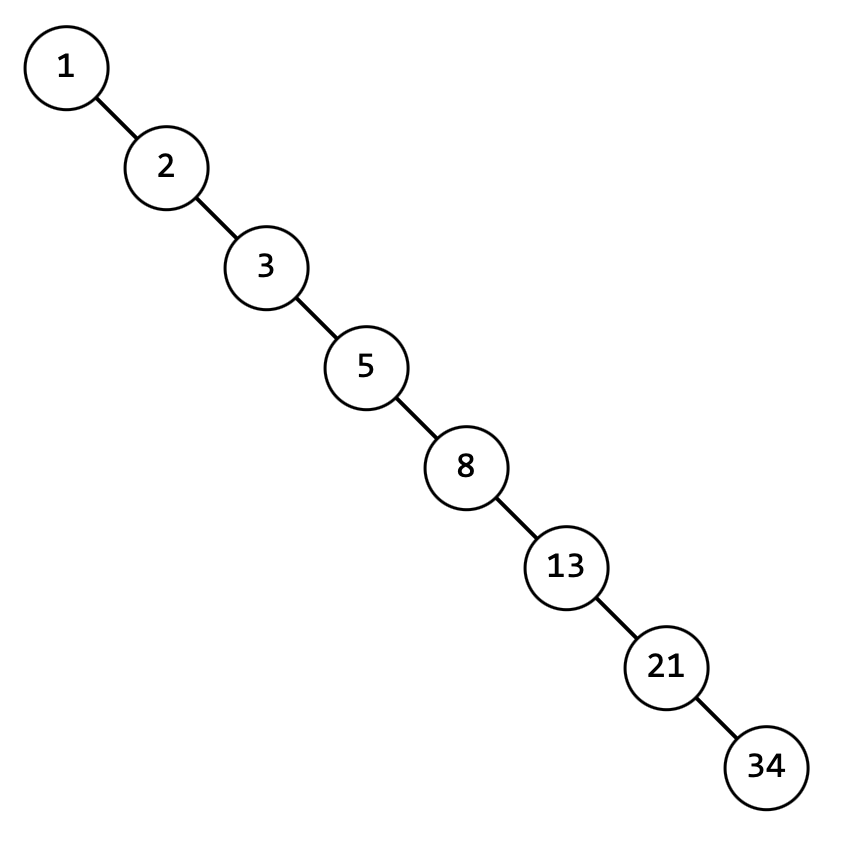
Для дерева можно ввести понятие высоты. Высотой дерева называется максимальное число вершин дерева в цепочке, начинающейся в корне дерева, заканчивающейся в одном из его листьев, и не содержащей никакую вершину дважды.
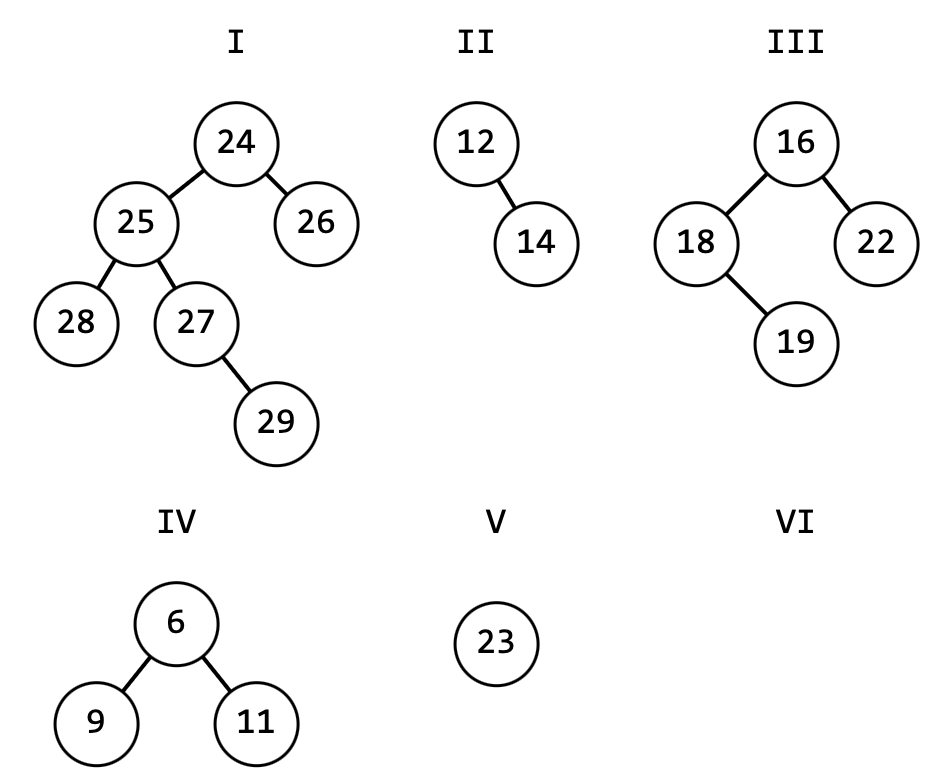
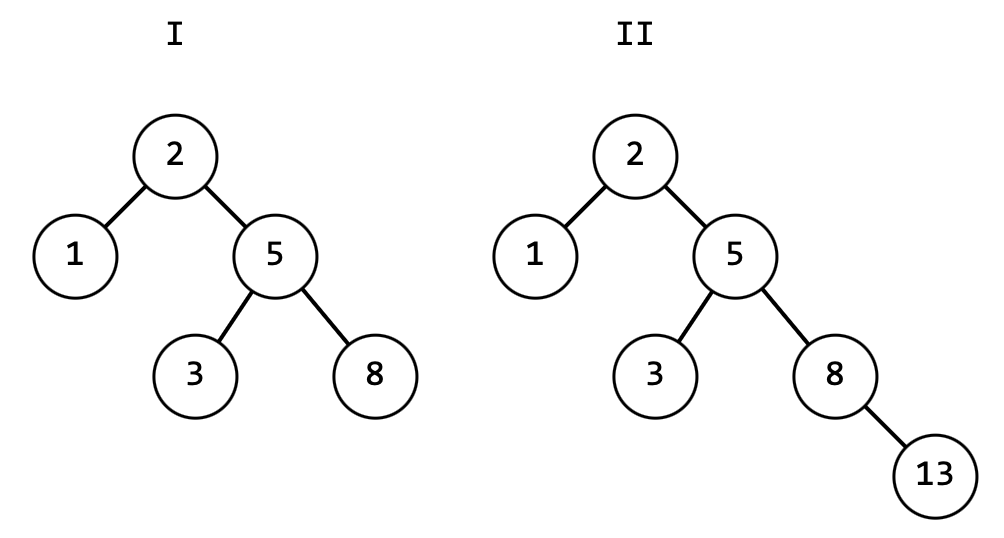
На рисунке 13 деревья имеют высоту:
I – четыреII, IV – дваIII – триV – одинVI – ноль (пустое дерево)
Замечание: Иногда за высоту дерева принимают количество связей от корневого элемента до самого дальнего узла.
Замечание: высота дерева в котором нет ни одного узла равна нулю, но можно встретить реализации, в которых высоту такого дерева принимают за -1.
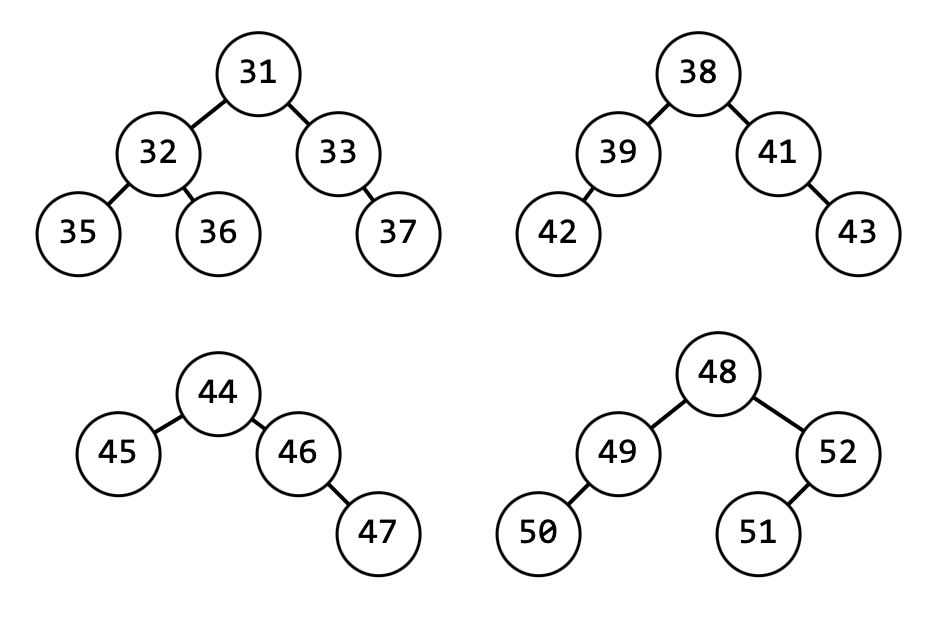
Чтобы ускорить все операции (CreateReadUpdateDelete) при хранении данных в деревьях, деревья стараются формировать так, чтобы высота левого и правого дерева были примерно равными, а количество узлов в левом поддереве отличалось от количества узлов в правом поддереве не более, чем на единицу – рисунок 14.
Для того, чтобы в деревьях не было перекосов (как на рисунке 12 или 13-I), существуют сбалансированные деревья.
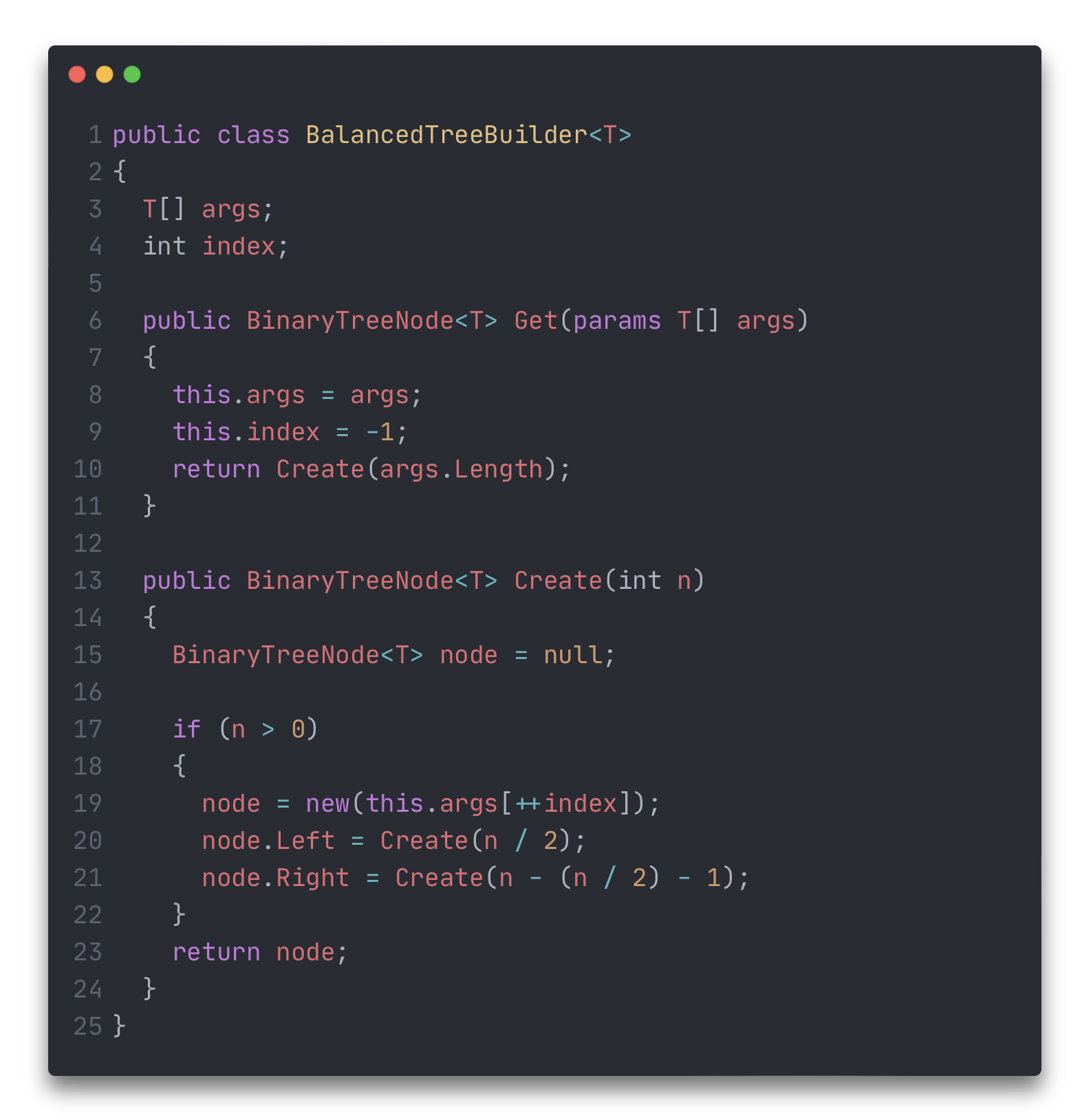
Пример построения простого сбалансированного дерева
Определение: Сбалансированное дерево – это дерево, для каждого узла которого высота левого и правого поддеревьев отличается не более чем на 1.
Если всего в дереве должно быть N узлов, тогда в левом поддереве будет N/2, а в правом – N - N/2 - 1 узел, (-1 - так как один узел будет корнем текущего дерева).

Пример построения 1:
n: 6 items = 1 2 3 4 5 6 1 2 3 4 5 6
Пример построения 2:
n: 12 items = 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12
Пример построения 3:
n: 2 items = 1 2 1 2
Хорошо. Теперь мы готовы к тому, чтобы построить "самобалансирующееся" бинарное дерево поиска. Примером таких деревьев являются АВЛ-деревья.
АВЛ-деревья
АВЛ-дерево (AVL tree) – это сбалансированное двоичное дерево поиска, в котором разница высот поддеревьев (баланс) каждого узла не превышает 1.
AVL-дерево было разработано в 1962 году двумя советскими учеными, Георгием Адельсон-Вельским и Евгением Ландисом, поэтому оно получило свое название. Оно является одним из наиболее эффективных способов хранения и поиска данных в деревьях.
Всё, что было справедливо для двоичных деревьев поиска остаётся и добавляется идея балансировки, при добавлении узла или его удалении так, чтобы разница высот всегда была не больше 1.
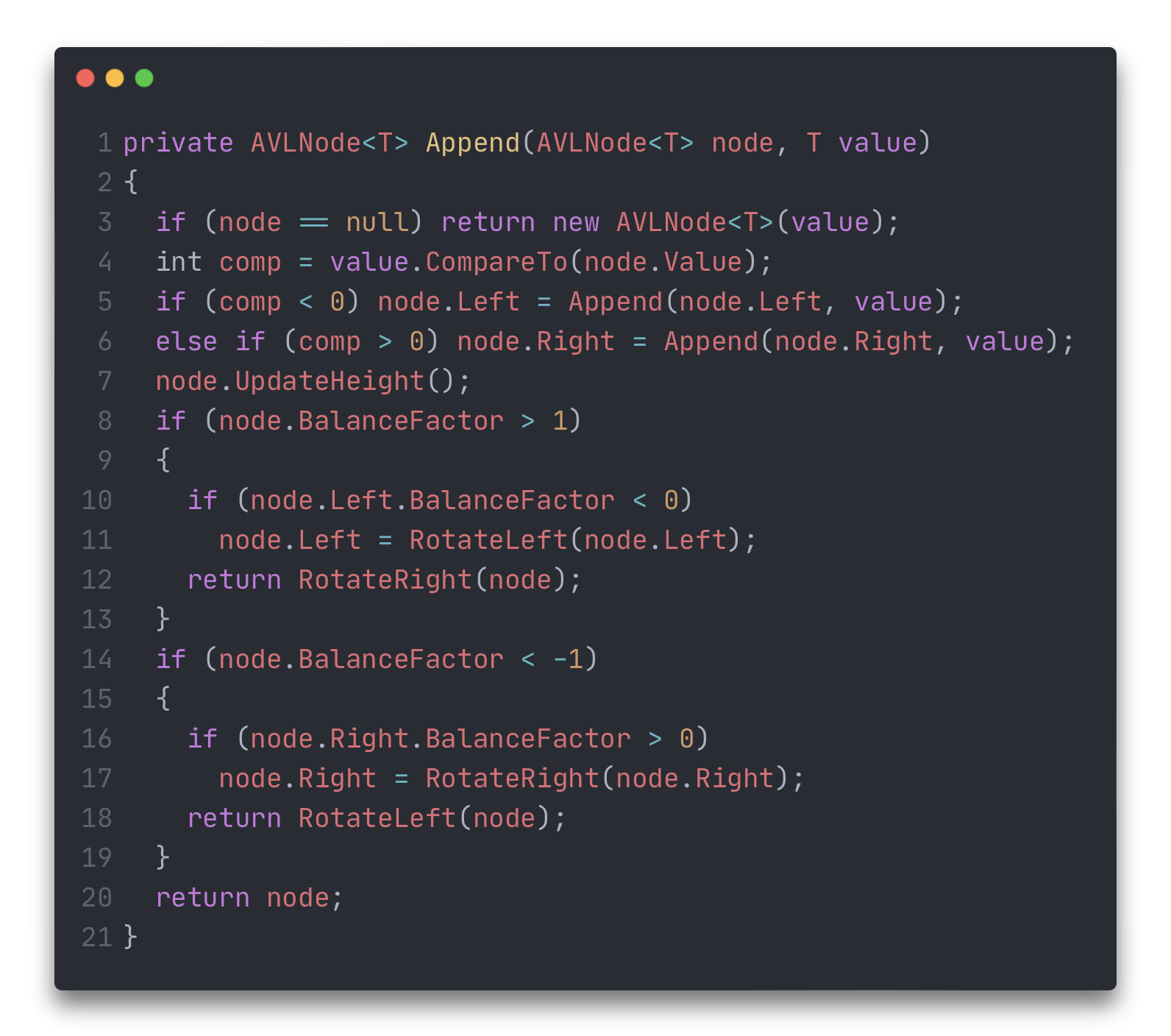
Учитывая то, что теперь требуется работать с высотами, значит нужно немного поменять модель узла: помимо потомков требуется хранить высоту и как следствие – нужна логика вычисления текущей высоты, логика обновления высоты в случае добавления\удаления узлов и логика получения разницы высот левого и правого поддерева.
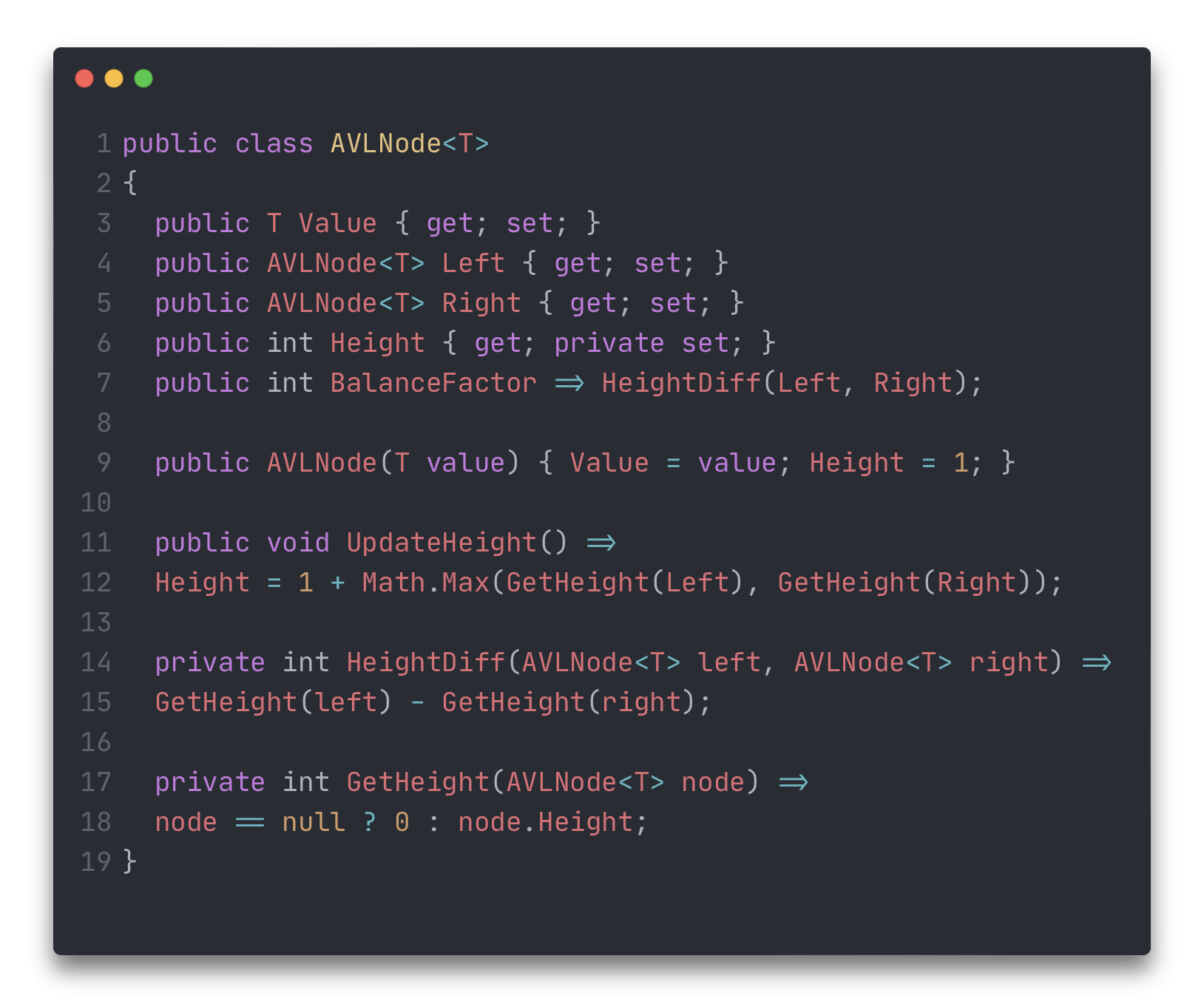
Логика поиска нужного узла, проверки наличия узла с заданными значением, поиск узла с минимальным значением и максимальным значением, написанная ранее для BinarySearchTree<T> остаётся неизменной. Логика добавления и удаления узла должна быть дополнена.
Дело в том, что теперь при добавлении или удалении узла, высота поддеревьев может поменяться, а значит поддерево относительно текущего узла нужно балансировать.
Балансировка деревьев происходит через "повороты", которых четыре вида:
- Левый
- Правый
- Левый-правый
- Правый-левый
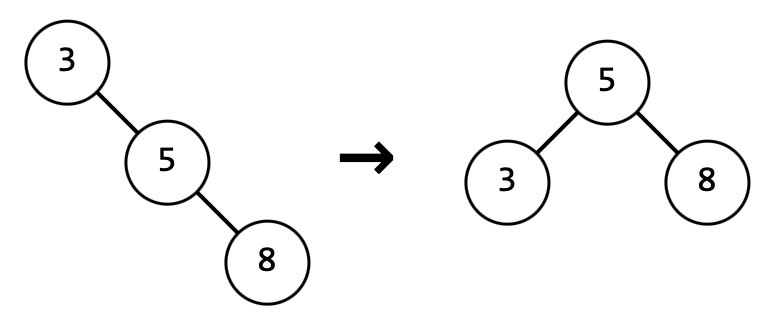
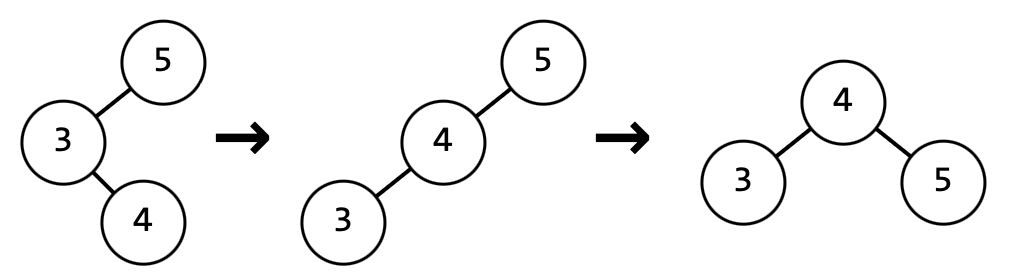
Пример "левого" поворота:
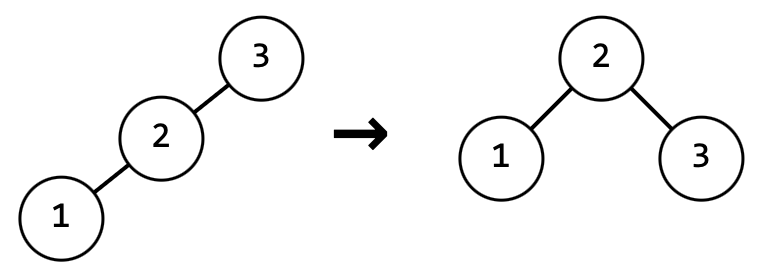
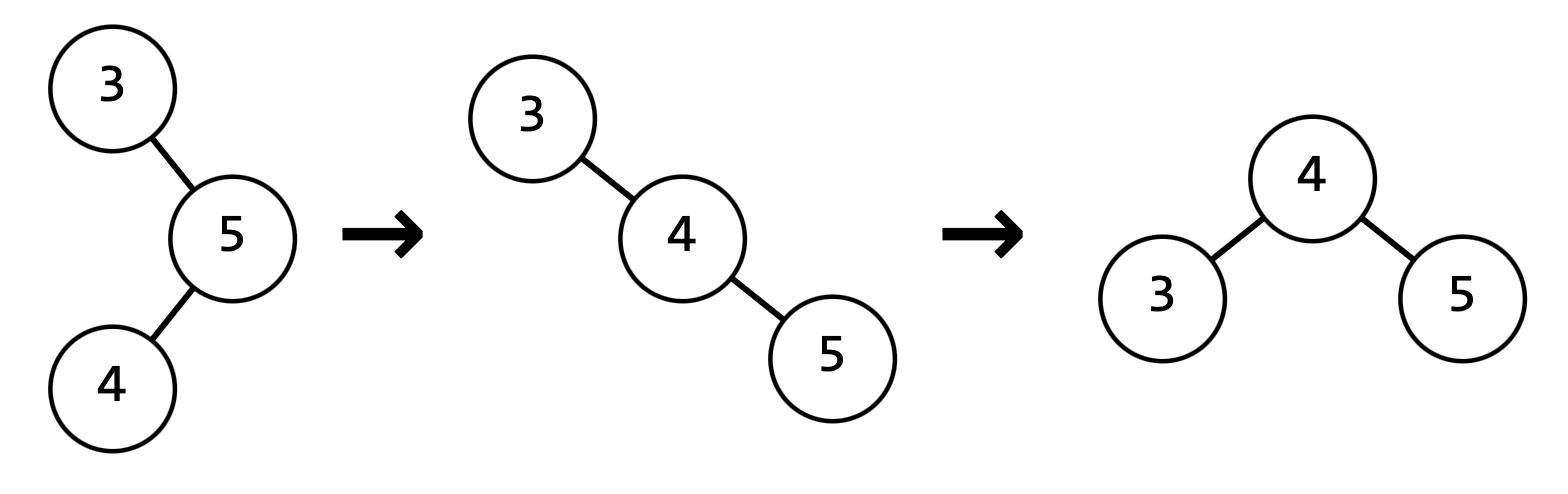
Пример "правого" поворота:
Если нам потребуется добавлять узлы со значениями 8, 5, 13, 3, 4, 2 в заданном порядке посмотрим, как будет меняться дерево:
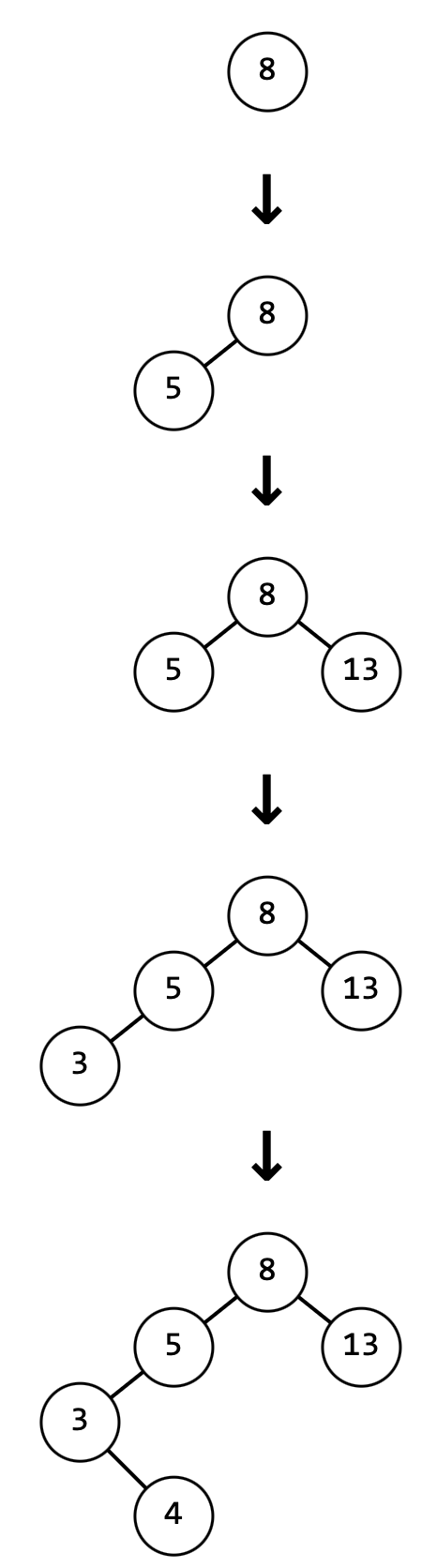
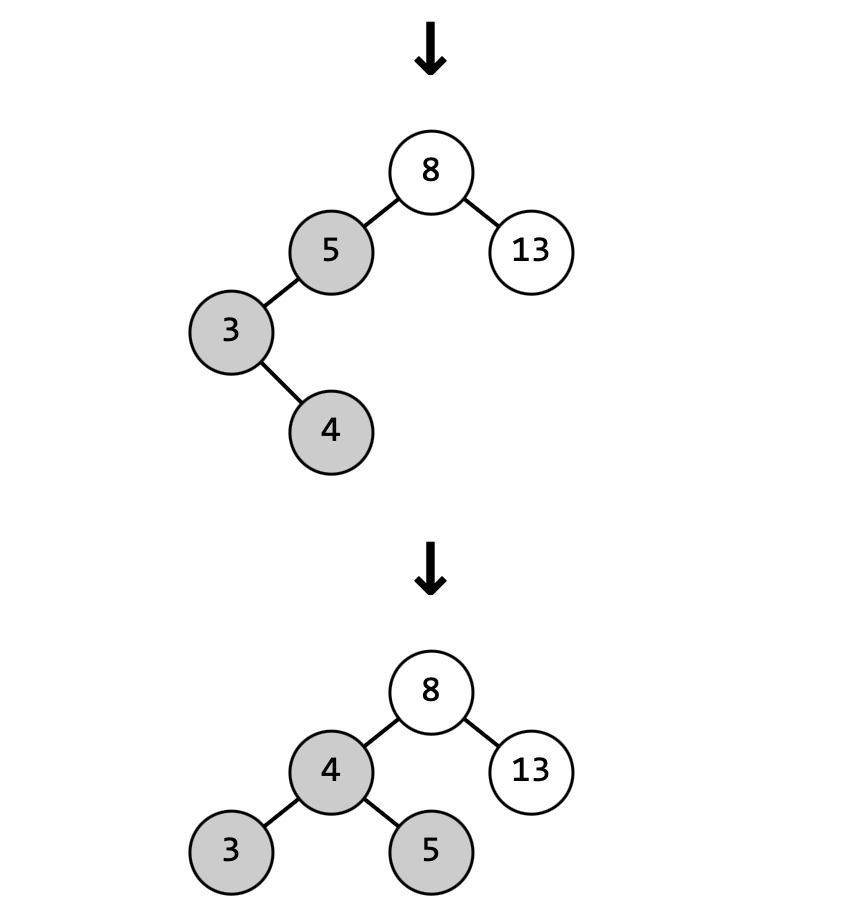
Такая балансировка получается путём левого-правого поворота.
Правый-левый поворот
Понять какой поворот требуется выполнять нам помогает свойство BalanceFactor который указывает на перегрузку поддерева.
- Если
BalanceFactorтекущего узла равен-2– нужен левый поворот - Если
BalanceFactorтекущего узла равен2– нужен правый поворот - Если дополнительно
BalanceFactorправого потомка равен1– нужен правый-левый поворот - Если дополнительно
BalanceFactorлевого потомка равен-1– нужен левый-правый поворот


В качестве демонстрации того, что при таком добавлении дерево действительно остаётся сбалансированным, можно посмотреть как меняется его высота

Результат:
AVLTree.Height: 10 -> n: 1023 AVLTree.Height: 11 -> n: 2047 AVLTree.Height: 12 -> n: 4095 AVLTree.Height: 13 -> n: 8191 AVLTree.Height: 14 -> n: 16383 AVLTree.Height: 15 -> n: 32767 AVLTree.Height: 16 -> n: 65535 AVLTree.Height: 17 -> n: 131071 AVLTree.Height: 18 -> n: 262143 AVLTree.Height: 19 -> n: 524287 AVLTree.Height: 20 -> n: 1048575
Исходники можно найти у меня на GitHub. Репозиторий Article-Tree
Это конец.