Дефенестрация? Не, не слышал!
Системный БлокъУже несколько лет люди охотно делятся в соцсетях результатами теста своего словарного запаса. Выглядит это так:
Ваш пассивный словарный запас — 88000 слов. Ваш индекс честности — 90%.
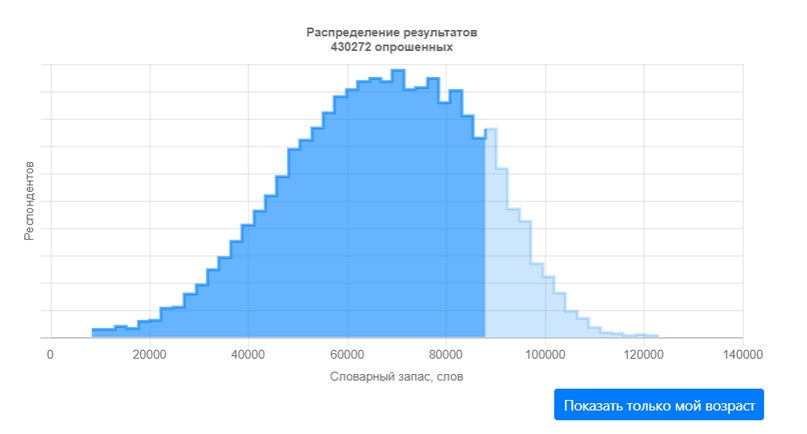
Предлагаем заглянуть под капот этого теста и посмотреть какие технологии позволяют посчитать число известных вам слов за 5 минут.
Задача теста — определить пассивный словарный запас (то есть количество слов, которые вы узнаете при чтении и на слух). Единственный способ сделать это точно — взять словарь потолще, отметить все слова, которые вы знаете, и посчитать их. Вряд ли найдется желающий пойти на подобное испытание.
К счастью, альтернативный подход предлагает современная теория тестов (IRT, Item Response Theory). Она предлагает методику тестирования с вопросами разной ценностью для предсказания уровня знаний. Каждый вопрос имеет три параметра:
- Трудность
- Дискриминация (насколько эффективно этот вопрос может различать студентов по уровню их знания)
- Угадывание (насколько вероятно, что испытуемые могут получить правильный ответ, угадывая)
Но как определить трудность вопроса «Знаете ли вы это слово»? В тесте это делается через частотность его употребления в большой коллекции текстов (корпусе текстов). Чем реже встречается слово — тем ценнее, что вы его знаете. Частотность слов считалась по Национальному корпусу русского языка. Например, если вы отмечаете слово «кошка» как знакомое, это не очень ценно для исследования, а вот «дефенестрация» — это да, вы молодец!
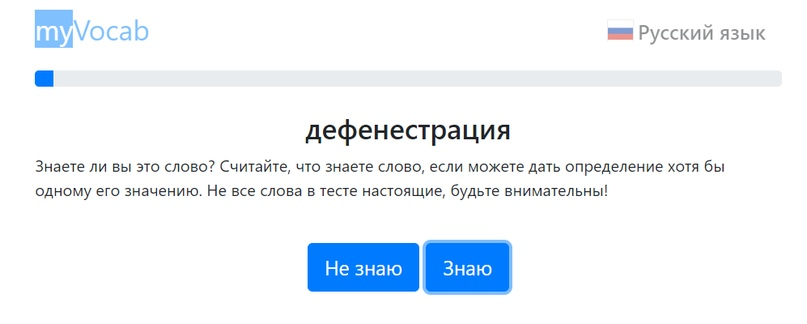
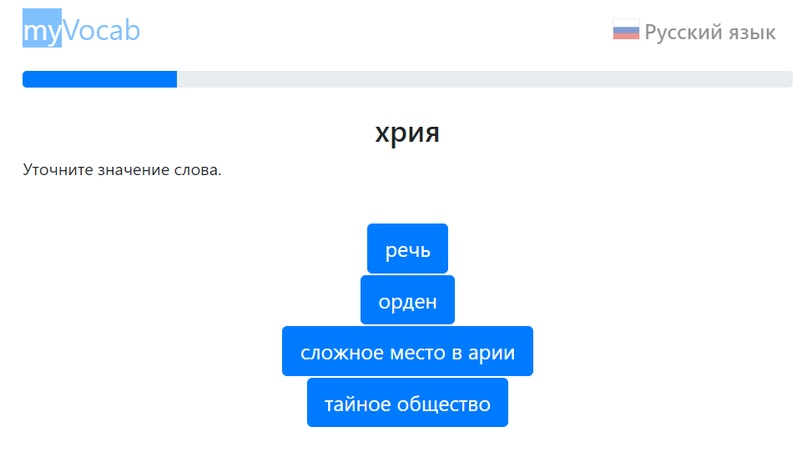
Чтобы сделать тест точным, но максимально коротким, была использована надстройка над современной теорией тестов — компьютерное адаптивное тестирование (Computerized Adaptive Testing, CAT). От ответа на вопрос зависит выбор следующего вопроса. Если респондент отмечает сложное слово (скажем, «петроглиф») как знакомое, скорее всего, у него большой словарный запас, поэтому следующим вопросом он получает слово с высокой сложностью, и наоборот. Таким образом, каждое тестовое слово приносит в тест максимум информации.
Почему нельзя просто врать и всё время жать кнопку «Знаю»? Для проверки на честность введены две методики: во-первых, врунишка может попасться на несуществующем слове, во-вторых — несколько раз за тест система предложит выбрать верное толкование для слова, которое вы только что отметили как знакомое.
Немного интересной статистики по результатам теста:
- Словарный запас растет с практически постоянной скоростью до примерно 20 лет, после чего скорость его набора уменьшается, останавливаясь примерно к 45 годам. После этого словарный запас уже практически не меняется.
- Во время обучения в школе подросток узнает по 10 слов в день.
- К моменту выпуска из школы человек в среднем знает 51 тысячу слов. Для сравнения: Словарь Ожегова — 70 тысяч слов, Даля — более 200 тысяч слов.
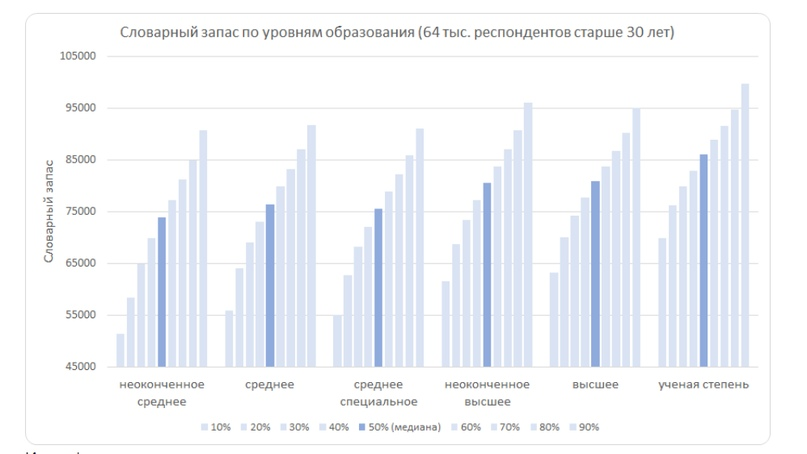
На графике выше видно как словарный запас зависит от уровня образования. И кажется, наконец появился ответ, зачем люди пишут кандидатские: как минимум, чтобы подучить новых слов :) В среднем люди с ученой степенью знают на 5 тысяч больше, чем те, у кого просто есть высшее образование.
Ссылки:
Статистика по результатам для русского языка
Антонина Лапошина
«Системный Блокъ» — ваш проводник в девяти кругах Big Data. Подписывайтесь на «Системный Блокъ»!