Deep Learning: как это работает? 1 часть
Небольшое вступление
Это начало цикла статей о том, какие задачи есть в DL, сети, архитектуры, принципы работы, как решаются те или иные задачи и почему одно лучше другого.
Какие предварительные навыки для понимания всего нужны? Сказать сложно, но если вы умеете гуглить или правильно задавать вопросы, то, я уверен, мой цикл статей поможет разобраться во многом.
В чем вообще суть глубокого обучения?
Суть в том, чтобы построить некий алгоритм, который принимал бы на вход X и предсказывал Y. Если мы пишем алгоритм Евклида для поиска НОД, то мы просто напишем циклы, условия, присваивания и вот это вот все — мы знаем как построить такой алгоритм. А как построить алгоритм, который на вход принимает изображение и говорит собака там или кошка? Или вовсе ничего? А алгоритм, на вход которого мы подаем текст и хотим узнать — какого он жанра? Вот так просто ручками написать циклы и условия тут не выйдет — тут на помощь и приходят нейронные сети, глубокое обучение и все вот эти модные слова.
Более формально и чуть-чуть о функциях активации
Выражаясь формально, мы хотим построить функцию от функции от функции…от входного параметра X и весов нашей сети W, которая выдавала бы нам некий результат. Тут важно отметить, что мы не можем взять просто много линейных функций, т.к. суперпозиция линейных функций — линейная функция. Тогда любая глубокая сеть аналогична сети с двумя слоями (входом и выходом). Для чего нам нелинейность? Наши параметры, которые мы хотим научиться предсказывать, могут нелинейно зависеть от входных данных. Нелинейность достигается путем использования различных функций активаций на каждом слое.
Fully-connected neural networks(FCNN)
Просто полносвязная нейронная сеть. Выглядит как-то так:

Суть в том, что каждый нейрон одного слоя связан с каждым нейроном следующего и предыдущего (если они есть).
Первый слой — входной. Например, если мы хотим подать изображение 256x256x3 на вход такой сети, то ровно 256x256x3 нейронов во входном слое нам и понадобится (каждый нейрон будет принимать 1 компоненту (R, G или B) пикселя). Если хотим подать рост человека, его вес и еще 23 признака, то понадобится 25 нейронов во входном слое. Кол-во нейронов на выходе — кол-во признаков, которые мы хотим предсказать. Это может быть как 1 признак, так и все 100. В общем случае по выходному слою сети можно почти наверняка сказать — какую задачу она решает.
Каждая связь между нейронами — вес, который тренируется алгоритмом backpropagation, о котором я писал тут.
Какие задачи может решать FCNN
-Задача регрессии. Например, предсказание стоимости магазина по каким-то входным критериям типа страны, города, улицы, проходимости и т.п.
-Задача классификации. Например, классика — MNIST classification.
-Насчет задачи сегментации и обнаружения объектов с помощью FCNN я сказать не возьмусь. Быть может, кто-то поделится в комментариях :)
Недостатки FCNN
- Нейроны одного слоя не имеют «общей» информации (все веса в сети уникальны).
- Огромное кол-во обучаемых параметров (весов), если мы хотим обучать сеть на фотографиях.
Convolutional Neural Networks (CNN)
Сверточная нейронная сеть. Выглядит примерно так (архитектура vgg-16):
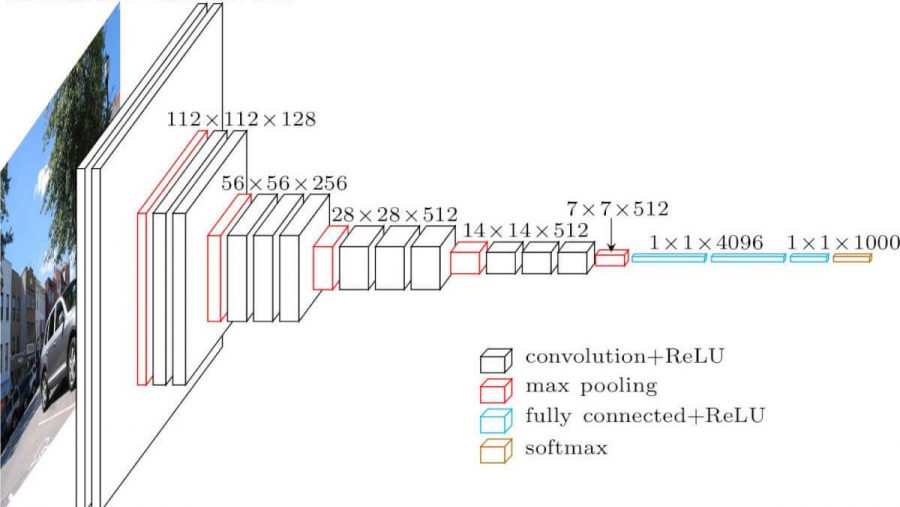
Какие отличия от полносвязной сети? В скрытых слоях теперь происходит операция свертки.
Так выглядит свертка (same convolution):

Просто берем изображение(пока что — одноканальное), берем ядро свертки(матрицу), состоящее из наших обучаемых параметров, «накладываем» ядро(обычно оно 3х3) на изображение, производим поэлементное умножение всех значений пикселей изображения, попавших на ядро. Затем все это суммируется(еще нужно добавить параметр bias — смещение), и мы получаем какое-то число. Это число является элементом выходного слоя. Двигаем это ядро по нашему изображению с каким-то шагом(stride) и получаем очередные элементы. Из таких элементов строится новая матрица, на нее же применяется(после применения к ней функции активации) следующее ядро свертки. В случае, когда входное изображение трехканальное, ядро свертки тоже трехканальное — фильтр.
Но здесь не все так просто. Те матрицы, которые мы получаем после свертки, называются картами признаков (feature maps), потому что хранят в себе некие признаки предыдущих матриц, но уже в неком другом виде. На практике применяют сразу несколько фильтров для свертки. Это делается для того, чтобы «вынести» как можно больше фич на следующий слой свертки. С каждым слоем свертки наши признаки, которые были во входном изображении, представляются все более в абстрактных формах.
Еще пара замечаний:
- После свертки наш feature map становится меньше (по ширине и высоте). Иногда, чтобы слабее уменьшать ширину и высоту, или вовсе ее не уменьшать(same convolution), используют метод zero padding — заполнение нулями «по контуру» входной feature map.
- После самого последнего сверточного слоя в задачах классификации и регрессии используют несколько fully-connected слоев.
Почему это лучше, чем FCNN
- У нас теперь может быть меньше обучаемых параметров между слоями
- Теперь мы, извлекая признаки из изображения, учитываем не только какой-то отдельный пиксель, но и пиксели возле него(выявление неких паттернов на изображении)
Max pooling
Выглядит это так:
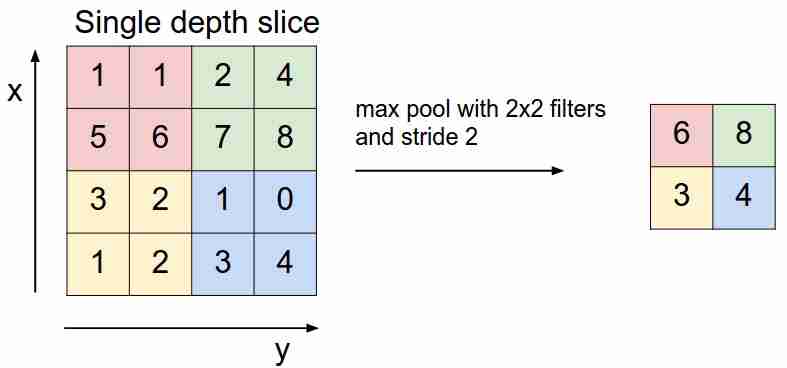
Мы «скользим» по нашей feature map фильтром и выбираем только самые важные(в плане входящего сигнала, как некоторого значения) признаки, уменьшая размерность feature map. Есть еще average(weighted) pooling, когда мы усредняем значения, попавшие в фильтр, но на практике более применим именно max pooling.
- У этого слоя нет обучаемых параметров
Функции потерь
Мы подаем на вход сети X, доходим до выхода, вычисляем значение функции потерь, выполняем алгоритм обратного распространения ошибки — именно так учатся современные нейронные сети(пока речь только об обучении с учителем — supervised learning).
В зависимости от задач, которые решают нейронные сети, используются разные функции потерь:
- Задача регрессии. В основном используют функцию средней квадратичной ошибки (mean squared error — MSE).
- Задача классификации. В основном используют кросс-энтропию (cross-entropy loss).