DataOps-Driven Governance and Analytics with dbt and StarRocks
Data&AI Insights📖 Источник: medium.com
Краткое содержание статьи Статья посвящена современному подходу к управлению данными и аналитике на базе интеграции dbt, StarRocks и практик DataOps. Рассматривается, как объединение моделирования данных, автоматизации и аналитики в единую архитектуру позволяет повысить скорость разработки, надежность и качество управления данными в условиях растущих требований к реальному времени и гибкости. В статье подробно раскрываются ключевые компоненты dbt для моделирования и автоматизации управления, роль DataOps в обеспечении контроля и скорости, технические инновации StarRocks для гибридной аналитики, а также реальные кейсы применения этих технологий.
Роль dbt в моделировании данных и автоматизации управления
Основные возможности dbt dbt (data build tool) представляет собой фреймворк для построения и управления аналитическими данными через код. Принцип «data models as code» позволяет описывать преобразования, логику и зависимости данных в структурированном, версионируемом виде. Помимо создания курируемых моделей данных, dbt автоматически генерирует артефакты управления — словари данных, графы происхождения (lineage) и автоматические тесты качества данных. Это создает основу для разработки разнообразных продуктов — от аналитических дашбордов до бизнес-приложений.
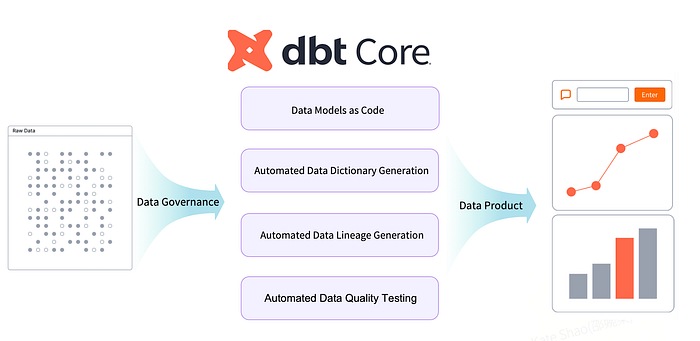
Модели данных как код и DevOps-подход dbt внедряет DevOps-подобную методологию в область данных. Команды работают с несколькими feature-ветками, где автоматические тесты запускаются при слиянии. После проверки в staging-среде CI/CD-пайплайны продвигают изменения в продакшн. Такой процесс обеспечивает версионирование, ревью и управление моделями данных с тем же уровнем дисциплины, что и в разработке ПО.
StarRocks как слой аналитического исполнения StarRocks — высокопроизводительная аналитическая СУБД, построенная по lakehouse-архитектуре, объединяющей аналитику реального времени и пакетную обработку без разделения на разные системы. Она обеспечивает высокую конкуренцию и низкую задержку запросов на свежих данных, что идеально подходит для дашбордов и операционной аналитики. Интеграция с data lakes и ELT-пайплайнами позволяет строить масштабируемые платформы без потери производительности и консистентности.
В архитектуре StarRocks отвечает за хранение и исполнение запросов, dbt — за моделирование, версионирование и тестирование. Это разделение ответственности повышает управляемость и надежность. Git используется как система учета изменений, все SQL-модели, материализованные представления и другие объекты проходят через pull request workflow и CI/CD, что обеспечивает трассируемость и безопасность.
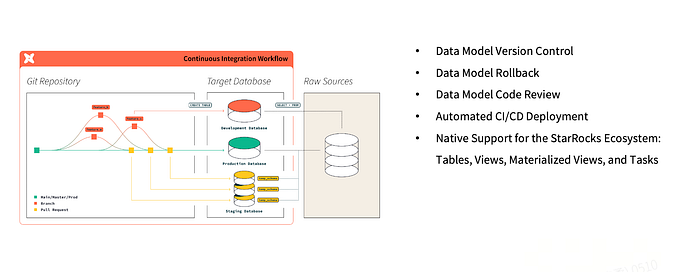
Управление моделями и автоматизация В dbt модель — это SQL-шаблон. Обычно создается staging-модель для исходных данных, которая затем используется в бизнес-моделях. dbt автоматически разрешает зависимости и управляет порядком выполнения, устраняя необходимость во внешних планировщиках.
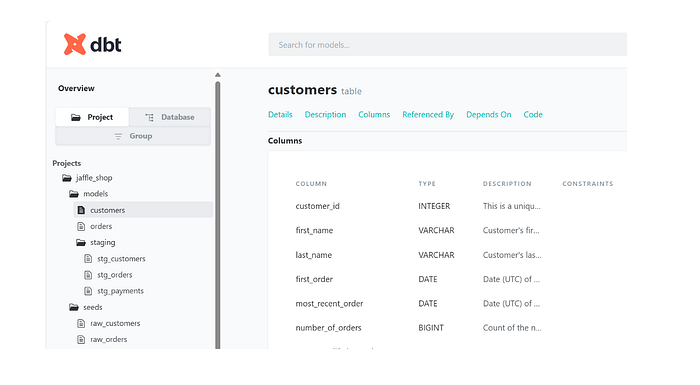
Автоматическая генерация словарей данных dbt генерирует HTML-документацию, включающую определения полей, бизнес-смысл, SQL-логику и зависимости. Документацию можно брендировать под корпоративный стиль.
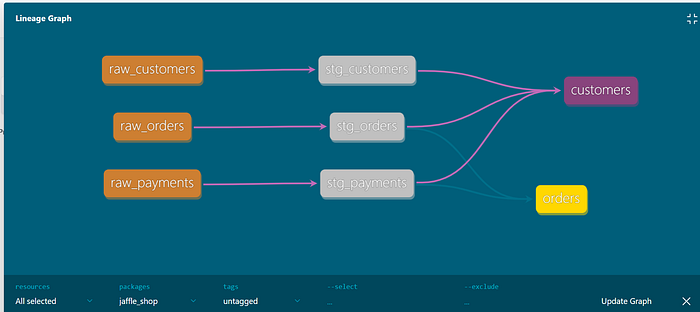
Автоматический анализ происхождения данных (data lineage) Data lineage — ключевой элемент управления данными, особенно в крупных организациях с тысячами таблиц и продуктов. Например, в индустрии гостеприимства, где объединяются данные из отелей, ресторанов и других бизнес-единиц для создания Customer 360, lineage помогает быстро оценить влияние изменений на downstream модели и отчеты.
Автоматизированное тестирование качества данных dbt позволяет определять разнообразные тесты, например, проверки уникальности (unique), отсутствия null-значений (not_null), а также связи между моделями (ref-based relationship tests). Тесты конфигурируются в YAML-файлах, что централизует управление качеством. Ежедневные проверки позволяют оперативно выявлять аномалии и запускать оповещения.

Некоторые команды используют AI-инструменты для автоматической генерации и поддержки YAML-конфигураций, снижая ручной труд и повышая консистентность.
Улучшение гибкости и контроля в проектах с DataOps
Основные компоненты DataOps DataOps расширяет DevOps-подход на весь жизненный цикл данных: разработка, тестирование, деплой, эксплуатация. В архитектуре DataOps dbt покрывает моделирование, автоматическое тестирование, lineage и документацию. Для остальных этапов интегрируются Jira (управление задачами), планировщики (ежечасное/ежедневное выполнение), Jenkins (CI/CD), BI-инструменты (визуализация и принятие решений).
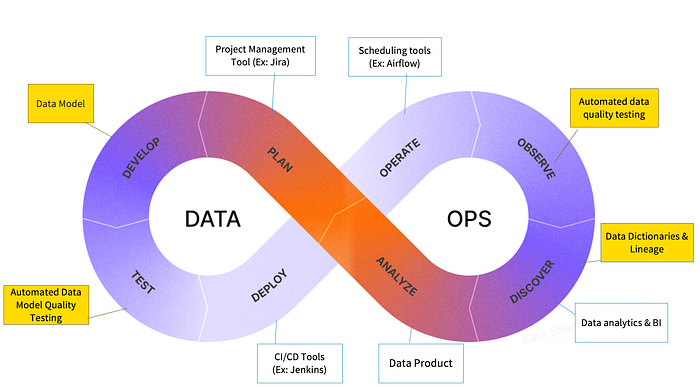
Стандарты контроля версий: Conventional Commits Команды применяют Conventional Commits — стандартизированный формат сообщений коммитов, который четко разделяет типы изменений: новые функции (feature), исправления багов (fix) и др. Например, добавление нового измерения в модель order увеличивает минорную версию (2.0 → 2.1), исправление бага — патч (2.1.0 → 2.1.1). Это позволяет автоматизировать управление версиями и генерацию релиз-нот.

Пример CI/CD в DataOps CI/CD начинается с Pull Request, который запускает пайплайн валидации. Сначала выполняется linting — автоматическая проверка качества SQL и конфигураций. После успешных проверок изменения деплоятся в staging, где запускаются unit-тесты и проверки качества данных. Затем следует ручной код-ревью, после одобрения изменения мержатся в основную ветку, автоматически создается новая версия, обновляются релиз-ноты и происходит продвижение в QA или продакшн.
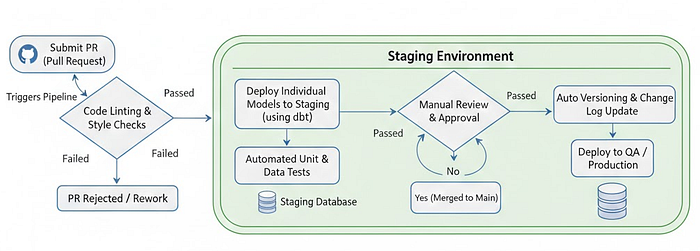
Такой процесс обеспечивает баланс между скоростью и контролем, что является ключом к зрелой DataOps-практике.
Технические инновации StarRocks для гибридной аналитики
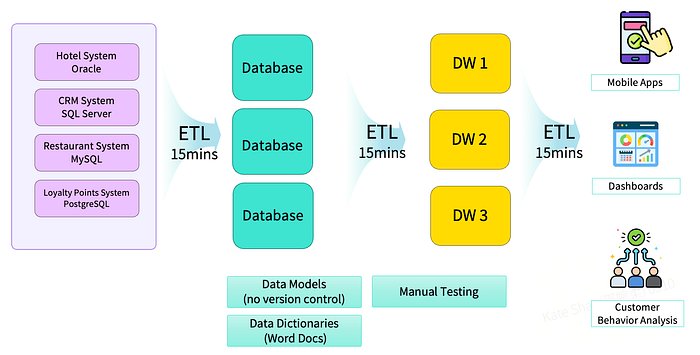
Проблемы традиционных ETL-архитектур Ранее многие организации использовали разрозненные ETL-системы с отдельными operational DB и периодическими загрузками (например, каждые 15 минут) в несколько хранилищ данных. В индустрии гостеприимства это приводило к множеству независимых pipeline для мобильных приложений, отчетности и аналитики. Недостатки такой архитектуры: отсутствие версионирования моделей, ручное тестирование, фрагментированная документация в виде отдельных Word-файлов, что снижало надежность и увеличивало трудозатраты.
ELT-фреймворк StarRocks С появлением StarRocks архитектура трансформировалась в lakehouse-модель, поддерживающую как потоковую, так и пакетную обработку. С помощью CDC (Change Data Capture) данные из операционных систем непрерывно поступают в data lake. ELT-подход позволяет быстро создавать продукты для приложений, одновременно обеспечивая сквозное управление данными: версионирование моделей, централизованные словари и автоматический lineage.
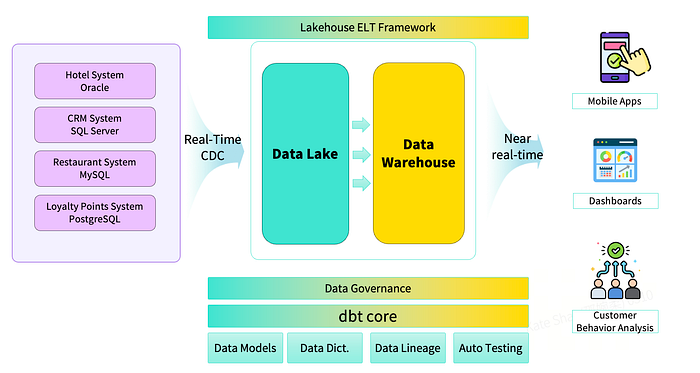
Результаты внедрения StarRocks + dbt + DataOps В новой системе данные в near-real-time поддерживают мобильные приложения, дашборды и поведенческую аналитику. Объединенный DataOps-фреймворк обеспечивает:
- Ускорение итераций и восстановления: модели dbt можно быстро обновлять и откатывать, что повышает скорость разработки и время реакции на инциденты.
- Эффективность доставки: стандартизированные пайплайны и Agile-подходы сокращают время от требования до продакшна.
- Консистентность моделей и документации: модели и YAML-документация хранятся в Git, изменения без обновления документации блокируют релиз.
- Повышенная точность и надежность аналитики: анализ lineage помогает оценить влияние изменений в десятках систем отелей, а автоматические тесты ежедневно проверяют корректность данных.
Заключение
Интеграция dbt, StarRocks и DataOps создает мощный, гибкий и управляемый стек для современных аналитических задач, объединяя моделирование данных как код, автоматизацию тестирования и управления, а также высокопроизводительную аналитику в реальном времени. Такой подход позволяет предприятиям значительно повысить скорость разработки, качество данных и прозрачность процессов, что критично в условиях растущих требований к оперативности и надежности данных. Опыт крупных организаций, таких как SJM Resorts, подтверждает эффективность этой архитектуры, демонстрируя улучшение процессов разработки, управления и эксплуатации аналитических платформ.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ