Data architecture 101
Data&AI Insights📖 Источник: vutr.substack.com
Data Architecture 101: основы проектирования систем данных
Введение
Архитектура данных представляет собой фундаментальную дисциплину в области инженерии данных, определяющую принципы построения систем для поддержки растущих потребностей бизнеса в информации. В отличие от программной архитектуры, не существует единого общепринятого определения этого термина. Автор статьи опирается на формулировку из книги «Fundamentals of Data Engineering» авторов Джо Рейса и Мэтта Хаусли: архитектура данных — это проектирование систем для поддержки меняющихся потребностей предприятия в данных, достигаемое гибкими и обратимыми решениями на основе тщательной оценки компромиссов. Архитектура данных служит своеобразным чертежом для любых операций, обеспечивающих получение insights из исходных данных: от приёма и хранения до трансформации, управления и предоставления пользователям. Ключевое требование — гибкость и способность адаптироваться к быстрорастущим запросам бизнес-пользователей.
Два основных подхода к архитектуре данных
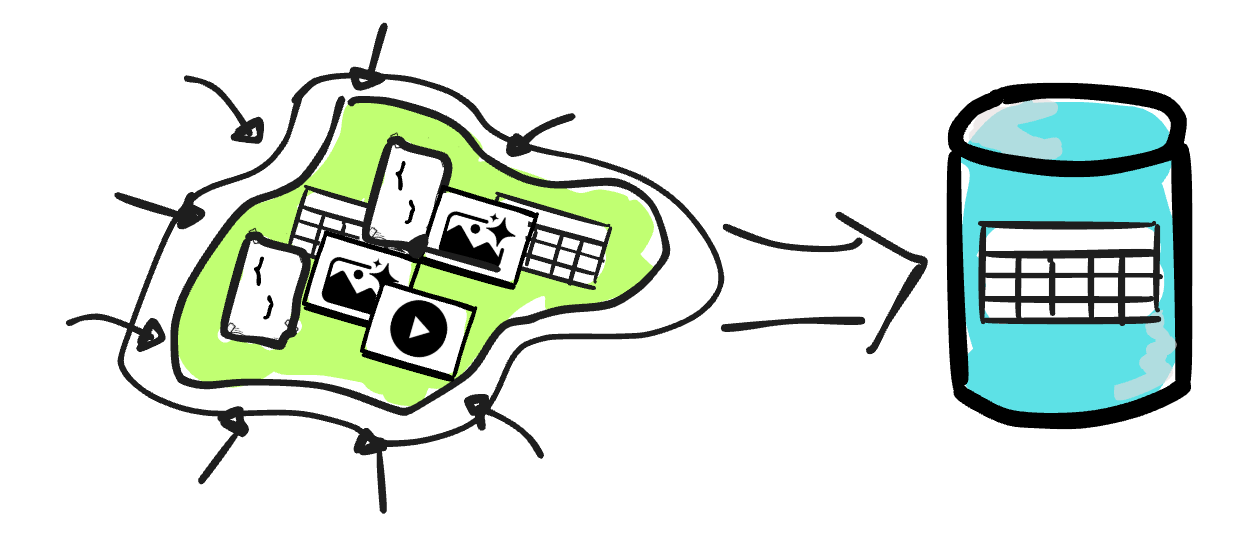
В любой компании данные поступают из множества источников. Изначально может казаться, что источник один, но со временем компания наращивает количество сервисов, приложений и интеграций с внешними инструментами — каждый из них генерирует собственные данные. Бизнес-пользователи постоянно нуждаются в аналитике: чем больше данных появляется, тем больше возможностей они видят для наблюдения, обучения и оптимизации бизнеса.
Существует два фундаментальных подхода к организации архитектуры данных: централизованный и децентрализованный. В централизованном подходе все данные консолидируются в едином «месте», которое становится источником истины для приёма, хранения, обработки и предоставления данных. Управление данными осуществляется централизованной командой. Билл Инмон назвал это место data warehouse (хранилище данных). Децентрализованный подход предполагает распределение данных и управления ими между различными командами или подразделениями.
Эволюция хранилищ данных (Data Warehouse)
Концепция data warehouse была введена Биллом Инмоном и представляет собой централизованное хранилище, где данные консолидируются из различных источников для аналитических целей. Исторически хранилища данных реализовывались на основе транзакционных баз данных, которые изначально не проектировались для аналитических нагрузок.
В 2000-х и 2010-х годах произошёл значительный прогресс благодаря появлению OLAP-баз данных. Эти системы способны обрабатывать большие объёмы данных через сканирование и агрегацию, а модель оплаты по факту использования в облачных решениях сделала реализацию хранилищ данных более производительной и экономически эффективной.
Существует распространённое заблуждение, что реляционные хранилища данных принимают только структурированные данные. Это стало основной мотивацией для появления концепции data lake. Однако современные решения, такие как Snowflake и BigQuery, уже поддерживают полуструктурированные данные (например, JSON) и даже неструктурированные данные — текст, изображения, аудио.
Озера данных (Data Lake)
Data lake (озеро данных) — это концепция хранения больших объёмов данных в их исходном формате, первоначально в HDFS, а позже в облачных объектных хранилищах. В отличие от реляционных хранилищ данных, data lake не требует предварительного определения схемы, что позволяет хранить данные любого формата без ограничений.
Первоначально предпринимались попытки полностью заменить традиционное хранилище данных на data lake, размещая обработку непосредственно поверх озера. Однако этот подход имел серьёзные недостатки: из-за отсутствия полноценных функций управления данными (обнаружение данных, гарантии качества и целостности, ACID-транзакции, поддержка DML-операций) data lake быстро превращался в «болото данных» (data swamp).
Синтез подходов: архитектура Lakehouse
Необходимость преодоления недостатков обоих подходов привела к созданию гибридной архитектуры. С середины 2000-х до 2020-х годов наиболее рекомендуемым подходом стала комбинация: data lake используется для приёма сырых данных в исходном формате, а data warehouse — для хранения преобразованных данных. Такой подход позволяет сохранить гибкость приёма данных любого формата и одновременно обеспечить качество, управляемость и производительность аналитики.
Эта архитектура получила название lakehouse — объединение лучших качеств озера данных и хранилища. Она обеспечивает единую точку для управления данными на всех этапах: от приёма сырых данных до предоставления готовых аналитических витрин бизнес-пользователям.
Заключение
Архитектура данных продолжает эволюционировать вместе с потребностями бизнеса и технологическими возможностями. Ключевой вывод из статьи: не существует универсального решения — выбор между централизованным и децентрализованным подходом, между warehouse, lake и lakehouse зависит от конкретных требований организации, объёма данных, команды и бизнес-целей. При этом критически важно сохранять гибкость архитектуры, способную адаптироваться к меняющимся условиям, поскольку решения в области данных должны быть обратимыми и учитывать постоянно меняющиеся требования бизнеса.
📢 Информация предоставлена телеграм-каналом: Data&AI Insights
🤖 Data&AI Insights - Ваш источник инсайтов о данных и ИИ