Data Science Guide for Beginners
Maria SparkData science is not just a buzzword. This is something that will change the world like the steam engine and personal computer once did. In fact, Data Science is already changing our reality bringing new innovations to surface.
From our credit story to birth records and medical history – data is all around and needs to be stored, processed, and protected. This is what data science is aimed at – to create a secure and powerful environment for huge arrays of information.
Previously, we taught you theoretical basis of data science, including its structure, purposes, and entreprise cases. Today we`ll see the way it works it practice and tell you how to deal with data science from the ground.
Data Science Challenges
Before rushing into data science application, it`s important to anticipate the problems you`re likely to encounter.
Insufficient Involvement of Stakeholders
In case you haven`t determined the project customers and sponsors, your startup is doomed to failure. The customer means the end user of the product – an external or internal consumer. Whereas the sponsor allocates resources – a specific manager, head of department, who is more concerned about the financial aspect and deadlines. The purpose of the big data and machine learning integration should be discussed and agreed with the customer.
Lack of Clear Hypothesis
Unclear goals and unproven justifications impede you from building a successful data-based product. Often, data scientists rely on initial information from management or business analysts, skipping the stage of self-immersion in the subject area.
To accurately determine the concrete purpose of Big Data and Machine Learning technologies, you need to ask a few simple questions:
- What is the problem? Is it really worth spending resources (effort, time and money)?
- How often does it repeat itself: is this a systemic discrepancy or a special case?
- How will the solution help the business? Is it supposed to bring new customers, lower churn rate, increase revenue, or reduce costs?
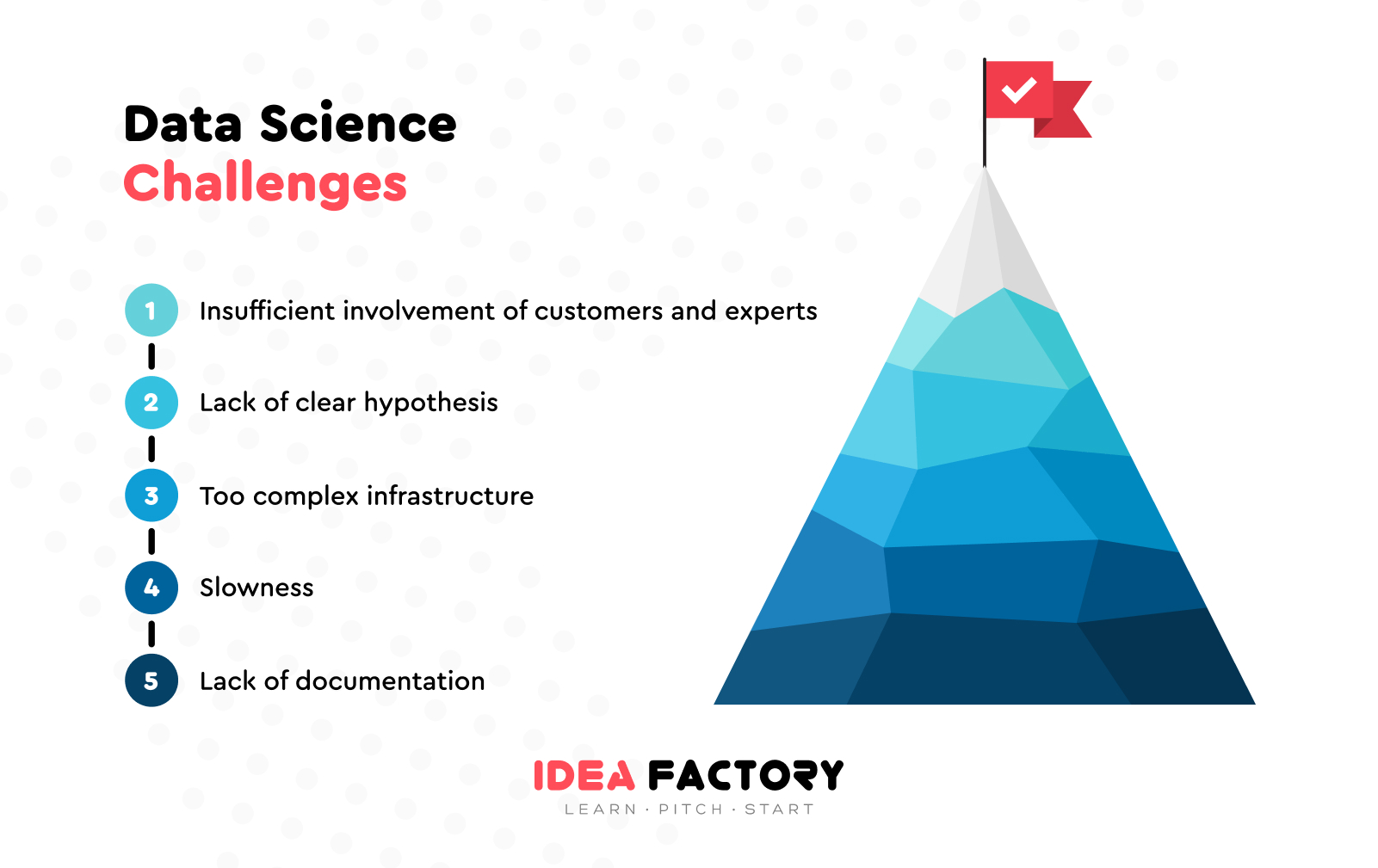
Too Complex Infrastructure
If a data scientist is too much focused on technical issues at the early development stage, it might impair the business and data analysis. Don't try to create a perfect product right away. Instead, take advantage of the agile methodology or lean startup approach. Make constant iterations to make sure things go as planned and gradually complicate it.
Slowness
When the preparation phase lasts excessively long, developers may lose interest and focus on the key things. Don't try to do everything perfectly at once. It`s better to increase the technical complexity of your machine learning models gradually, from iteration to iteration. Stick to the set deadlines to keep your team concentrated.
Lack of Documentation
This problem typically occurs at the data preparation stage. If you haven`t necessary documents, the subsequent steps and iterations will last much longer. Ensure the information about the process of changing data is accessible and understandable for everyone.
Trends in Data Science
To make your product stand out on the market, it should be up-to-date. Take advantage of the latest tendencies to boost your chances for success.
Data Literacy
If the company doesn`t know how to implement data, it ends up useless. According to Tableau's Data Trends 2020 report, 40% of data budgets are spent on data literacy - the ability to handle data correctly. Enterprises arrange courses, cooperate with specialized departments and institutions to educate their teams on data science.
Data Storytelling
According to the Accenture`s study, the vast majority of consumers choose brands that totally understand their customers by means of data. Data-based content is an effective tool to spark buyers` interest and increase loyalty. So when collecting data, you need to create something exciting based on it, and not just slip ads on phrases from search queries. The user experience will thus become more complex, turning into compelling personal stories linking the customer with your company.
.
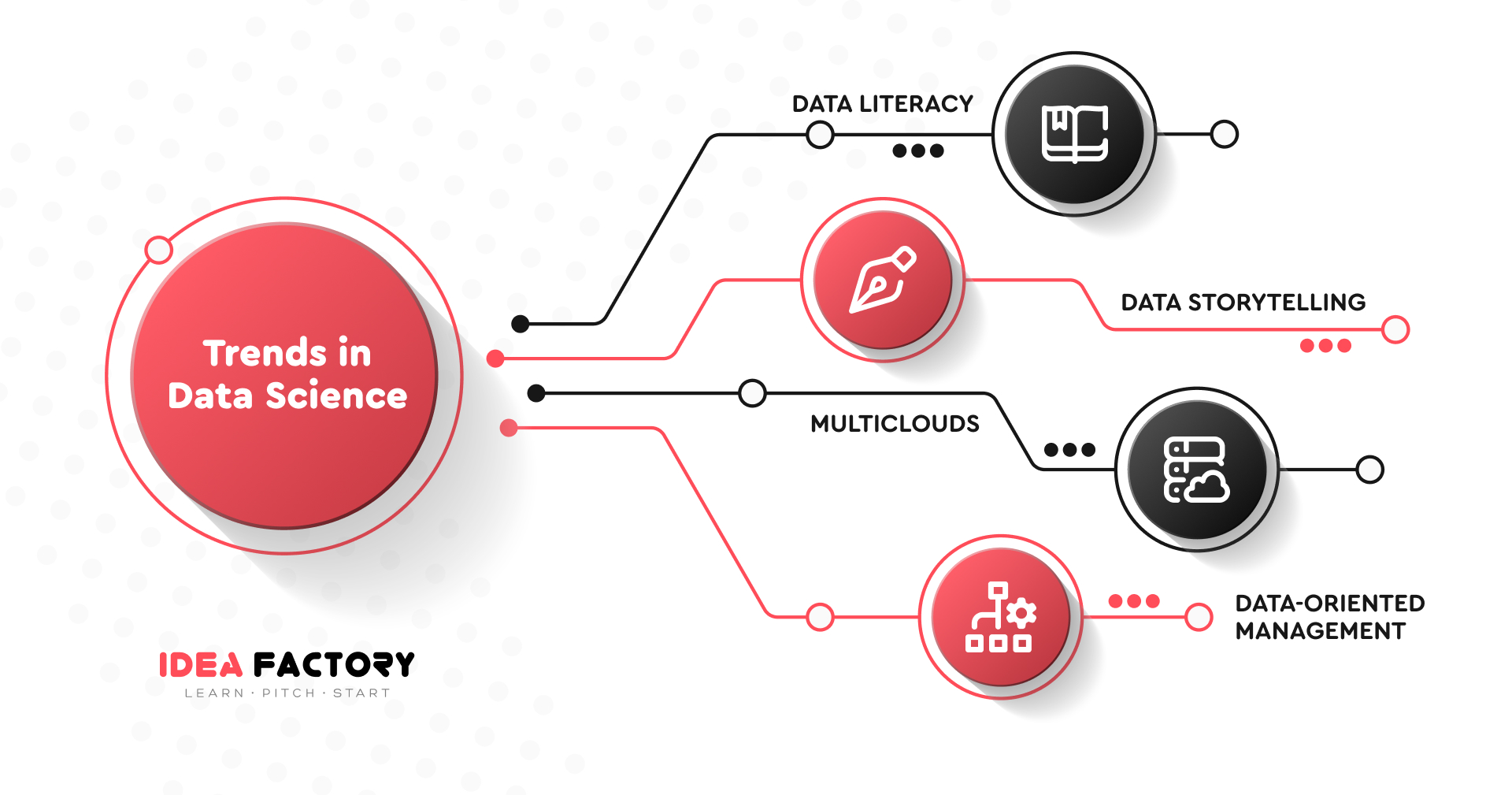
Multiclouds
Many organizations use hybrid cloud environments, where most of the data is stored in private data centers in systems from several vendors. Unstructured data grows many times, so the cloud is used as a secondary storage layer.
Here, it may be difficult to manage costs and risks, as well as to ensure high performance. IT leaders realize that extracting value from data distributed across cloud and on-premises environments is a real challenge. Multi-cloud strategies is the most efficient option when using multiple clouds for different use cases and datasets.
Data-oriented Management
Data factory is an architecture that provides data visibility, the ability to move and copy it, as well as access data in hybrid cloud storage. Near-real-time analytics allows brands to monitor the location of data in the clouds and storage. This helps make sure the information gets to the right place at the right time. Data factories will gain momentum and provide data-centric management rather than storage.
Instead of storing all medical images on a single NAS server, you can integrate analytics and user reviews to segment them. Businesses can copy data to provide access to MO-tools for clinical research. Or move critical data to immutable cloud storage to protect it from ransomware.
How to Learn Data Science from Scratch?
To get the hand of data science, you need to take 6 steps. It`s not an easy process but as you learn the things will become more comprehensible. Just stick to the strategy and soon you`ll see the result.
Statistics & Mathematics
Although nearly all algorithms are implemented in Python and R libraries, the knowledge in basic mathematical concepts will greatly simplify your studies. In addition, most articles on machine learning contain mathematical calculations, which will be difficult to read without knowing maths.
It will be enough to learn three core sections: linear algebra fundamentals, mathematical analysis basics (integration and derivatives) and probability theory which includes statistics.
Programming
To handle data, you should be able to program. This skill enables you to upload data, parse, synthesize new features, or implement any other idea of yours.
You can start learning one language and focus on all the nuances of its syntax. If you only start your journey, we recommend choosing Python. Firstly, it is a perfect pick for beginners as its syntax is relatively simple. Secondly, Python is multifunctional and can be used for various startups.
Machine Learning
If you want to set up a data-driven startup, you also need to know the main classes of Machine Learning tasks, what algorithms exist and what approaches allow you to solve a particular type of problems. Besides, you should distinguish between algorithms of different specializations, as well as understand their advantages and disadvantages. Machine learning is a practical discipline, so it is very important to apply the knowledge in practice.
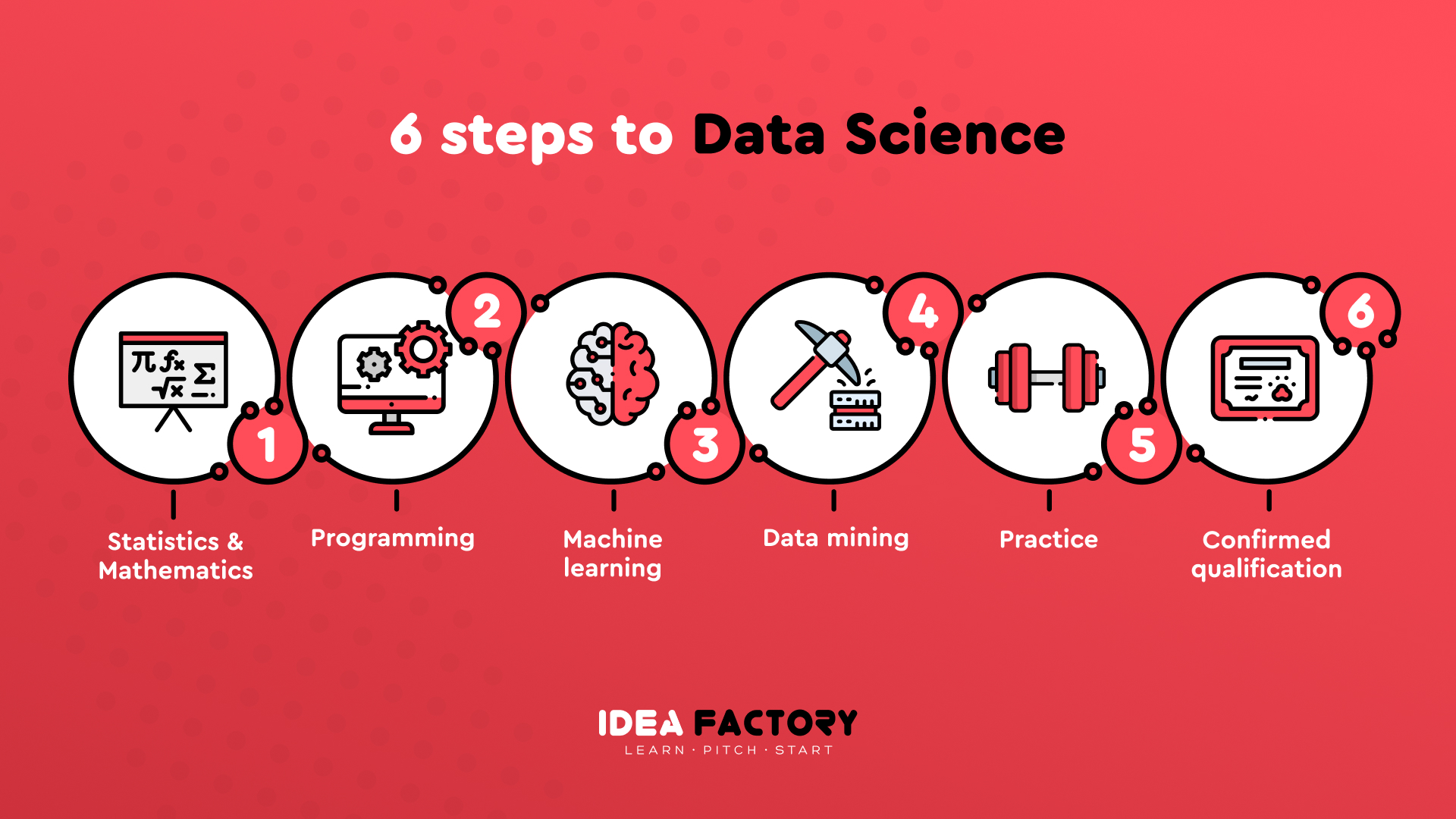
Data Mining
Data Mining is an important research process. It means the analysis of hidden data models based on various translation options into meaningful bites. They are them collected and formed in data warehouses to facilitate business decisions, reduce costs, and increase revenue.
Practice
Don`t overdo with theory. Otherwise, you might get bored and demotivated. Therefore, it is important to try your hand at practice. There is a bunch of open data arrays that you can analyze and then publish results. In addition, you can watch scripts posted by other users and learn from their experience.
Confirmed Qualification
To make sure you`ve gained enough experience in data science, you can pass some tests or take part in a contest. This will boost your self-confidence and officially prove your competences. In addition, such certificates may serve as an advantage when looking for an investor for your startup.
Final Recommendations
Our congrats, you`re almost ready to start your data science journey! In conclusion, we`ll provide you with hands-on tips when dealing with data-driven technologies.
The Simpler, the Better
You may know a huge number of Machine Learning algorithms and neural network architectures, but this does not mean that any problem needs to be solved by them. Sometimes it`s enough to use simple linear regression instead of integrating a multi-layer convolutional network (CNN). Simple solutions are always easier to implement and maintain. So start with a simple one, analyze the results, and complicate if needed.
Take Your Time
There is no need to rush when you`re learning. Take the time to completely understand the business problem you are trying to solve and grasp the data you are working with.
There is a bunch of questions you should be able to answer before diving into the development of the model. Some of them include: where the data comes from, how to prepare it, which libraries to use, etc.
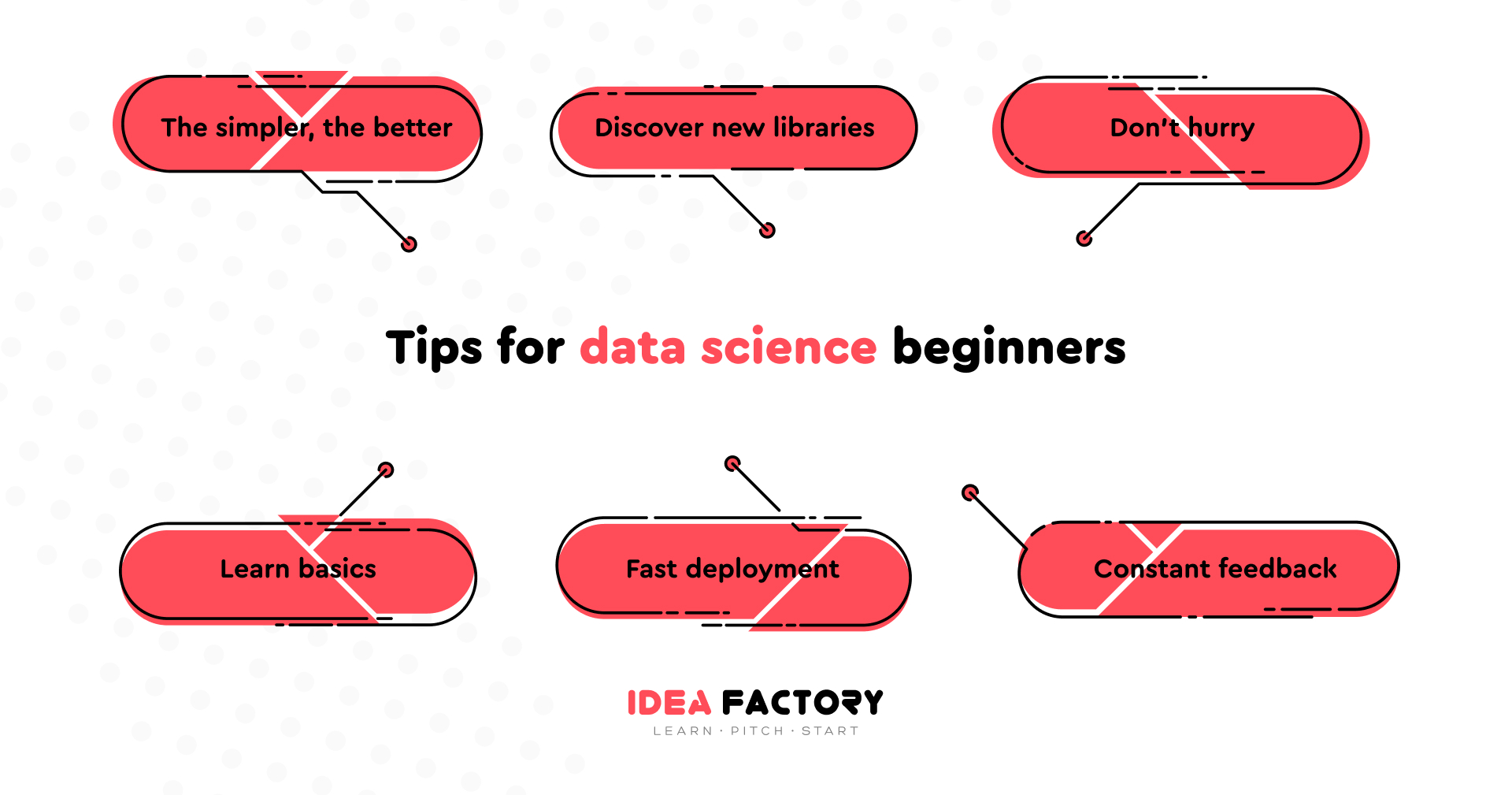
Learn Basics
Like machine learning, data science is entirely based on statistics. You can't do without statistical metrics as part of data analysis. Therefore, if you study statistics first, it will be much easier to learn the concepts and algorithms of machine learning and data science as a result.
Fast Deployment & Feedback
It is important to constantly communicate with all stakeholders, keep them informed on your drafts and ideas. This is the purpose of feedback. Divide the cycle into small iterations and collect feedback from customers, experts, mentors, and other parties. Otherwise, you may get a model that does not solve the problem.