Customer2Vec: Representation learning for customer analytics and personalization
Artem ErokhinСегодня поговорим о репрезентации пользователей в векторном виде. Идея достаточно простая - давайте вместо ручной генерации признаков мы отдадим все на откуп той или иной нейронной сети, откуда возьмем промежуточную сжатую репрезентацию пользователя в виде некоего вектора его свойств (embedding). Тогда, с помощью этого сжатого представления, мы сможем получить близость между пользователями (или продуктами). При этом, обычно такое представление лучше будет описывать наши данные, чем вручную полученные признаки (но это скорее верно при достаточно большом количестве входных данных).
Итак, классический способ представить пользователя в классическом ритейле или e-commerce - это его корзина. Понятно, что если пользователь любит крепкий алкоголь и дорогое мясо, то ему можно предложить хороший сыр. А молодой маме лучше предложить полезные продукты и эко-товары.
И такой же классический способ получить какое-то сжатое представление пользователя - разложить матрицу пользователь-товар. Но тут мы учитываем только часть информации (а именно, взаимодействие пользователя и товаров), но не учитываем контекст, агрегируем пользовательское поведение за все время и т.д.
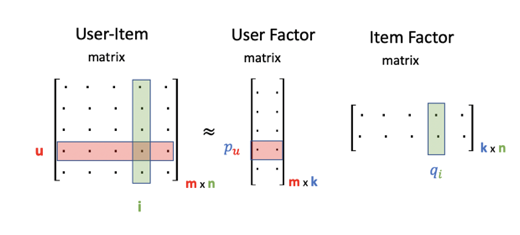
Соответственно, можно представить много разных способов для автоматизированного получения пользовательских представлений:
- Рекуррентные нейронные сети.
Мы можем взять пользовательскую последовательность действий, по которой будем предсказывать некий таргет (например, последующее действие). Тогда мы можем получить требуемые представления из скрытых слоев нашей сети; - Word2Vec.
Мы можем представить пользовательские действия, как тексты. Соответственно, мы можем обучить W2V модель, из нее получить представление для “слов” (это могут быть товары), а если мы усредним представления “слов”, то получим представление для пользователя. При этом, можно дополнить наш метод, представив пользовательский “текст” в виде набора атрибутов каждого из купленных товаров. Тогда можно будет учить представления для атрибутов; - Doc2Vec.
Получение представлений “слов” и их усреднение может работать не очень хорошо. Потому мы хотим получать представления целых “текстов” (“текстом” можно считать одну корзину пользователя), учитывая и иерархическую связь пользователь-корзина. Собственно, такой подход часто и называют user2vec, client2vec, или customer2vec; - Word2Vec и Doc2Vec на логах.
Применимо к онлайн-бизнесам, где мы можем учиться на логах поведения пользователя, а не только на его корзинах. Очевидно, логи будут обладать чуть большей информацией. Но доступна эта информация скорее онлайн-бизнесу. Для оффлайна такого бонуса не предусмотрено. - Guided learning.
Здесь мы миксуем получаемые без учителя репрезентации и обучение с учителем. Как это может быть реализовано? Например, мы можем иметь общую матрицу весов на задачу W2V и задачу обучения с учителем, ориентированную на какой-либо бизнес показатель. Тогда мы получим представления, более адаптированные к нашим бизнес-целям. - Автоэнкодеры.
В этой задаче мы учим исходный набор значений для пользователя переводить в сжатое представление, после чего стараемся максимально хорошо восстановить исходные данные из этого представления. Конечно же, такого рода представления тоже можно “докрутить” ближе к нашим бизнес целям; - Использование совмещенных источников данных.
В случае, если у нас есть несколько разных источников данных: графовые данные, текстовые, изображения и т.п. Мы можем объединить это в одну большую сеть, либо получать представления для сущностей отдельно, а уже их использовать в некоем объединенном виде.
Стоит отметить, что в разных случаях лучше могут сработать разные варианты реализации, т.к. заранее сложно представить, что сработает лучше. Впрочем, это достаточно стандартная история для работы с данными.
Дополнительно добавлю ссылку на оригинальную статью (ее лучше почитать, там более полно материал описан). И на код от авторов статьи.
В итоге поделюсь своим мнением.
Я считаю, что для многих областей автоматическое получение представлений и работа с уже готовыми наборами представлений может быть очень полезным бустером к качеству получаемых решений. Впрочем, не стоит недооценивать классические реализации, т.к. они сильно проще в разработке и поддержке, при этом, позволяют получить крепкий бейзлайн (и его еще нужно побить настолько, чтобы трудности с поддержкой окупились).