Clustred and none clustred index in postgres 2
@MojtabaPasoدرک کردن ایندکس خوشه ای و غیر خوشه ای در پایگاه داده محبوب فیل آبی PostgreSQL:
ایندکس های خوشه ای و غیر خوشه ای برای بهبود عملکرد query ها استفاده میشوند کلا همه چیز در برنامه نویسی وب در انتها و ابتدا به کوئری ها مربوط میشود .
شاخص های خوشه ای در PostgreSQL:
ایندکس های شاخه ای یک نوع ساختار ایندکس هست که ترتیب فیزیکی داده های روی دیسک را تعیین می کند چطوری خود PostgreSQL، شاخص خوشهبندی شده را با استفاده از مفهوم جدول خوشهای یا جدول سازمانیافته ایندکس پیادهسازی میشود. (کلمه کم آوردم قلبه سلمبه شد clustered table —index-organized table) وقتی که یک جدول از پایگاه داده فیلی را با استفاده از ایندکس خوشه ای مرتب میکنیم فیل آبی داستان ما داده ها را به صورت فیزیکی بر اساس مقادیر موجود درون ستون ها ایندکس شده مرتب میکند و مثل اینکه این (طبق مستندات فیل آبی PostgreSQL) این کار موجب تا پایگاه داده بتواند داده ها را به صورت موثر تری بازیابی کند
تفاوت بین ایندکس های خوشه ای و غیر خوشه ای :
۱.ایندکس خوشه ای سریعتر است و ایندکس غیر خوشه ای کندتر است .
۲.ایندکس خوشه ای به مقدار حافظه کمتری نیاز دارد .
۳.در ایندکس خوشه ای ، ایندکس خوشه ای بر روی داده های اصلی است و در ایندکس غیر خوشه ای بر روی مقادیر کپی شده از جدول اصلی است.
۴.یک جدول تنها میتواند یک ایندکس خوشه ای داشته باشد در مقابل میتواند چندین ایندکس غیر خوشه ای داشته باشد.
۵.ایندکس خوشه ای دارای توانایی ذاتی برای ذخیره داده ها بر روی دیسک است ، در مقابل ایندکس غیر خوشه ای این توانایی را به صورت ذاتی ندارد.
۶.در فهرست خوشه ای، گره های برگ خود داده های واقعی هستند. در مقابل در فهرست غیر خوشه ای، گره های برگ خود داده های واقعی نیستند، بلکه فقط شامل ستون های گنجانده شده هستند.
۷.در یک ایندکس خوشه ای، کلید خوشه ای ترتیب داده ها را در یک جدول تعریف می کند. در مقابل در یک ایندکس غیر خوشه ای، کلید ایندکس ترتیب داده ها را در ایندکس تعریف می کند.
۸.ایندکس خوشه ای نوعی ایندکس است که در ان سوابق جدول به صورت فیزیکی برای مطابقت با ایندکس مرتب می شوند. در مقابل یک ایندکس غیر خوشه ای نوع خاصی از ایندکس است که در ان ترتیب منطقی ایندکس با ترتیب ذخیره شده فیزیکی ردیف های روی دیسک مطابقت ندارد.
۹.اندازه ایندکس خوشه ای اولیه بزرگ است. در مقابل اندازه ایندکس غیر خوشه ای نسبتا مقایسه می شود کامپوزیت کوچکتر است.
۱۰.کلیدهای اصلی جدول به طور پیش فرض ایندکس های خوشه ای هستند. در مقابل کلید کامپوزیت هنگامی که با محدودیت های منحصر به فرد جدول استفاده می شود، به عنوان ایندکس غیر خوشه ای عمل می کند.


ایندکس کردن خوشهای یا غیر خوشهای؟
دادهها در دیتابیس ذخیره میشوند. اما چگونه پیدا میشوند؟
یک مثال خیلی معروفی که همیشه برای توضیح بعضی مفاهیم پایگاه داده استفاده میشود، مثال دفترچه تلفن است. فرض کنید دفتری دارید که شماره هر نفر را با نامش در آن مینویسید. سادهترین راه وارد کردن شماره افراد در این دفترچه چیست؟
به ترتیب هر نفری که اضافه میشود را به آخر لیست اضافه کنیم. در این حالت، اضافه کردن هر عضو جدید به دفترچه از مرتبه O(1) زمان لازم دارد. یعنی مهم نیست قبلا چند نفر وارد دفترچه شدهاند، اگر میخواهی عضو جدیدی اضافه کنی، باید یک زمان ثابت صرف انجام اینکار کنی.
طبیعی است که پیدا کردن شماره افراد در این دفترچه کار راحتی نخواهد بود اگر تعداد شمارهها زیاد باشد. در تعداد پایین، به راحتی میتوان با بررسی تکتک خطوط دفترچه، شماره مورد نظر را پیدا کرد. به این نوع جستجو sequential scanning گفته میشود که در تعداد پایین خیلی خوب جواب میدهد. اما وقتی یک میلیون شماره داشته باشیم باید چه کنیم؟ پیدا کردن شماره افراد در این دفترچه تلفن، برعکس اضافه کردنش، کار دشواری است که از مرتبه O(n) است. یعنی زمان مورد نیاز برای پیدا کردن هر شماره، رابطه خطی دارد با تعداد شمارههای داخل دفترچه.
برای بهبود بخشیدن به وضعیت دفترچه، باید اندکی زحمت بیشتری هنگام افزودن یک شماره به دفترچه بکشیم. در این صورت ممکن است موقع خواندن کار سادهتر شود. به اینکار ایندکس کردن میگویند. به مرتب کردن یا دستهبندی کردن دادههای پایگاهداده، به نحوی که پیدا کردن هر داده سادهتر شود، ایندکس کردن گفته میشود.
حالا سادهترین راه ممکن برای ایندکس کردن دادهها چیست؟
ایندکس کردن خوشهای یا clustered indexing
سادهترین راه برای تسهیل جستجو در دفترچه تلفن (سادهترین راهی که به ذهن من میرسد) این است که افراد را به ترتیب حروف الفبا وارد دفترچه کنیم. واضح است که نوشتن عضو جدید در دفترچه سختتر میشود. اما در عوض پیدا کردن یک شماره در کل دفترچه از مرتبه O(log n) زمان خواهد برد. به عبارتی از این به بعد میتوانیم جستجوی باینری انجام بدهیم برای پیدا کردن عضو جدید.
این راه نسبتا خوب بود نه؟ اما طبیعتا معایبی هم دارد. در این مثال شاید کمتر معایبش پیدا باشد. برای اینکه بهتر این نوع از ایندکس کردن را درک کنیم بهتر است مثال بهتری بزنم.
فرض کنید پایگاهدادهای از اطلاعات دانشآموزان یک مدرسه داریم. هر دانشآموز اطلاعات معدل، سن، مقطع تحصیلی و نام را دارد. خب حالا برای وارد کردن این دانشآموزان به پایگاهداده همه دانشآموزان را براساس نامشان مرتب میکنیم. اینطوری اطلاعات هر دانشآموز را به سرعت میتوانیم استخراج کنیم. اما اگر خواستیم شاگرد اول را پیدا کنیم باید چه کنیم؟ احتمالا کاری که باید کرد بررسی معدل تکتک دانشآموزان است. چرا؟ چون دانشآموزان را براساس معدل مرتب نکردیم، فقط براساس نام مرتب کردیم. اما آیا میتوانیم دانشآموزان را هم بر اساس معدل و هم بر اساس نام مرتب کنیم؟ شاید بشود اما کار سختی است. چون احتمالا باید دو تا جدول بزرگ داشته باشیم. در هر دو جدول دادههای یکسانی داشته باشیم. در جدول اول همه دانشآموزان بر اساس معدل و در جدول دوم همه بر اساس نام مرتب شدهاند. حجم خیلی زیادی از اطلاعات دوباره ذخیره میشوند. و این خیلی جالب نیست! چه باید کرد؟
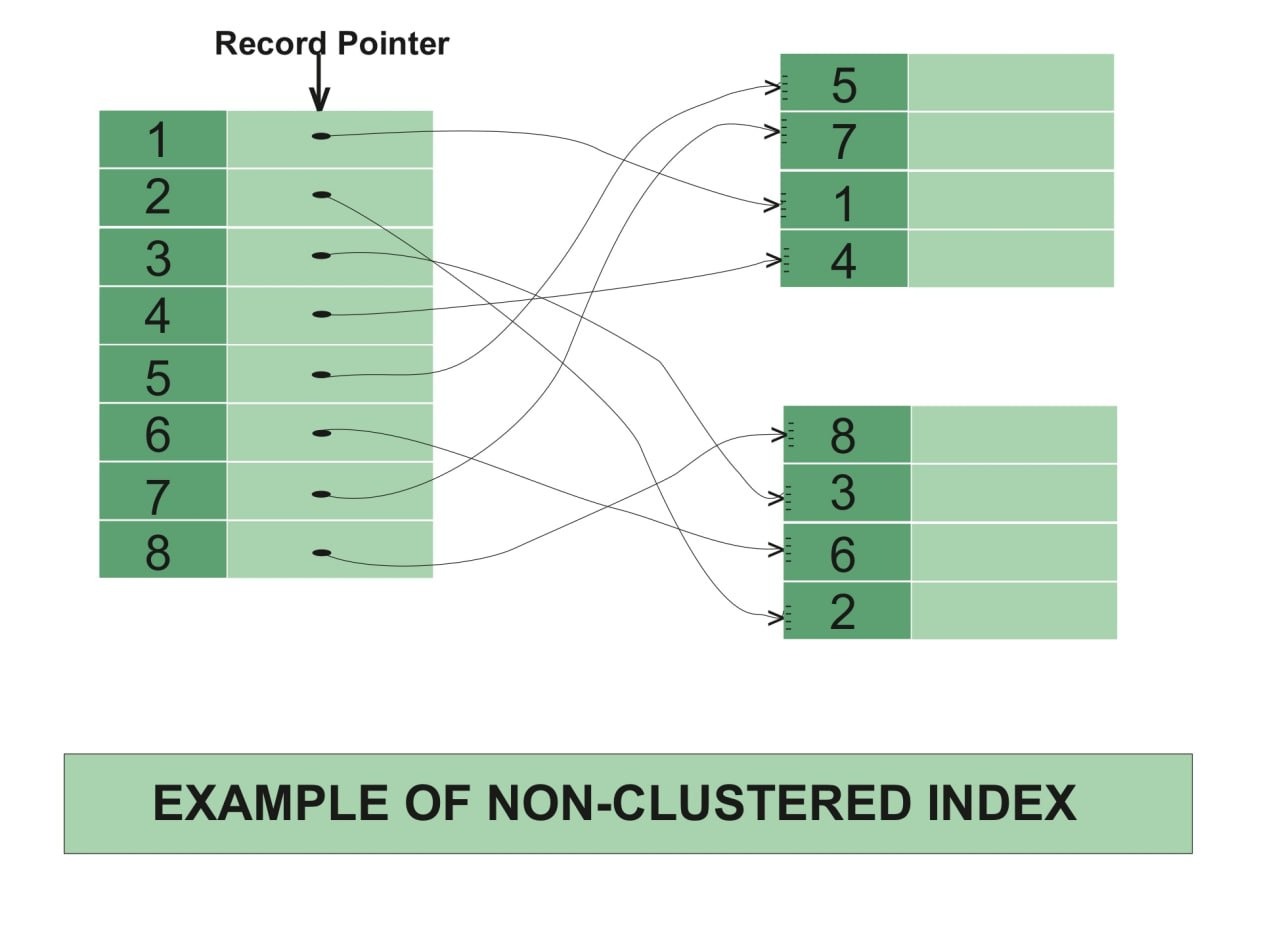
ایندکس کردن غیرخوشهای یا non-clustered indexing
در ایندکس کردن خوشهای، عینا خود دادهها در حافظه مرتب کنار یکدیگر چیده میشدند. بدیهی است که نمیشود یک سری از دادهها را به دو صورت مختلف مرتب کرد. یا باید دانشآموزان بر اساس معدل مرتب شوند یا نام. این محدودیت در ایندکس کردن غیرخوشهای رفع شده. روشی که در این نوع از ایندکس کردن استفاده میشود این است که جدول جدایی تعبیه میشود که در آن هر سطر شامل ۲ عنصر است. یک عنصر، عنصری است که قرار است با آن دادهها را مرتب کنیم، و دیگری آدرس حافظهای که آن داده در حافظه ذخیره شده. یعنی چه؟
مثلا فرض کنید میخواهیم دانشآموزان را هم بر اساس معدل و هم براساس نام مرتب کنیم. علاوه بر جدولی که خود دانشآموزان در آن ذخیره شدهاند، ۲ جدول دیگر خواهیم داشت. در یک جدول، نام دانشآموزان به ترتیب الفبا مرتب شده و جلوی هر نام، آدرس حافظهای که اطلاعات آن دانشآموز در آن ذخیره شده موجود است. یعنی شما در این جدول میگردی و دانشآموز با نام سینا را پیدا میکنی. حالا با استفاده از آدرسی که جلوی نام هست به اطلاعات سینا دسترسی پیدا میکنی. همین اتفاق درمورد جدول مربوط به معدل هم رخ میدهد. جدولی داریم که معدلها مرتب شده، و جلوی هر معدل آدرس حافظه مربوط به دانشآموز ذخیره شده.

همانطور که در تصویر بالا نظاره میکنید، لزوما دادهها به ترتیب داخل حافظه نوشته نشدهاند. دادهها میتوانند به هر ترتیبی در حافظه ذخیره میشوند اما چون حافظه دادهها در یک جدول مجزا وجود دارد، میتوانیم به دادهها به صورت مرتب دسترسی داشته باشیم.
یکی از معایب این روش این است که دسترسی به هر داده، ۲ مرحله است. ابتدا باید داده در جدول مرتب شده پیدا شود و سپس با استفاده از آدرس، دسترسی به داده اصلی ایجاد شود. اما در ایندکس کردن خوشهای دسترسی کاملا مستقیم بود.
@code_crafters