ChatGPT как инструмент для поиска: решаем основную проблему (часть 3)
Регуляризация при обучении WebGPT

Регуляризация - краеугольный камень машинного обучения. Обычно это работает так: добавляешь в большую математическую формулу для оптимизации еще пару членов, которые, как кажется на первый взгляд, взяты на ходу из головы - и модель начинает учиться лучше, учиться стабильнее, или просто хотя бы начинает учиться. В целом регуляризация направлена на предотвращение переобучения, и часто зависит от способа тренировки и самой архитектуры модели.
Так как мы переживаем, что модель начнет эксплуатировать неидеальность Reward Model, и это выльется в бессмысленные или некорректные генерации, то стоит задуматься над добавлением штрафа за, собственно, бессмыслицу. Но как её оценить? Существует ли инструмент, который позвоялет определить общую адекватность и связанность текста?
Нам очень повезло: мы работаем с языковыми моделями, натренированными на терабайтах текста, и они хороши в оценке правдоподобности предложений (вероятности из появления в естественной среде, в речи или скорее в интернете. Можно рассчитать как произведение вероятностей каждого отдельного токена). Особенно остро это проявляется в случаях, когда одно и то же слово повторяется по многу раз подряд - ведь в языке такое встретишь нечасто. Получается, что при обучении модели мы можем добавить штраф за генерацию неестественного текста. Для того, чтобы модель не сильно отклонялась от уже выученных текстовых зависимостей, введем член регуляризации, отвечающий за разницу между распределениями вероятностей слов, предсказанными новой обучаемой моделью и оригинальной BC (после тренировки на демонстрациях).
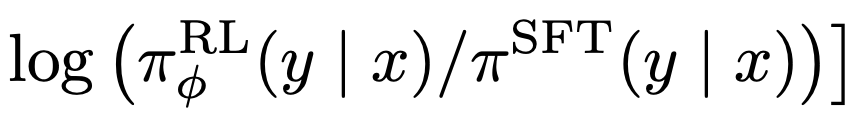
Чаще всего для этой цели используется Дивергенция Кульбака-Лейблера: это нессиметричная неотрицательная мера удаленности двух вероятностных распределений. Чем более похожи распределения, тем меньше её значение, и наоборот. Это значение вычитается из общей награды, и - так как мы решаем задачу максимизации - мешает достижению цели. Таким образом, мы вынуждаем модель найти баланс между отступлением от исходной BC с точки зрения генерируемых вероятностей для текста и общей наградой за генерацию. Приведённый подход - не панацея, и он не позволит бесконечно тренировать модель относительно зафиксированной RM, однако может продлить процесс, увеличивая тем самым эффективность использования разметки.
Альтернатива RL: меняем шило на мыло
Обучение с применением RL - задача не из лёгких, тем более на такой необычной проблеме, как "оптимизация генерируемого текста согласно фидбеку людей". Пользуясь тем, что WebGPT представляет собой языковую модель, оперирующую вероятностями, из которых можно семплить, авторы предлагают альтернативный способ, который не требует дообучения модели (относительно BC, после использования датасета демонстраций), однако потребляет куда больше вычислительных ресурсов.
Этот метод называется Best-of-N, или Rejection Sampling, и он до смешного прост. После полученя первой группы размеченных пар сравнений ответов WebGPT, согласно плану пайплана, обучается Reward Model. Эта модель может выступать в качестве ранжировщика для десятка (или N, если быть точным. Best-of-64 означает ранжирование 64 вариантов) потенциальных ответов одновременно, ее задача - проставление оценки (согласно предсказанию) и упорядочивание всех ответов. Самый высокооценённый ответ из всех и является финальным.
Разные ответы получаются за счет разных действий, сгенерированных WebGPT - на самом раннем этапе это может быть слегка изменённая формулировка вопроса в Bing API; чуть позже - прокрутка на 3-4 страницу поисковой выдачи вместо проверки топа; под конец - финальные формулировки, используемые для связывания процитированных фактов. Развилок достаточно много (во время генерации каждой команды! А ведь их может быть и 100), и потому варианты получаются действительно неоднородными. Более того, у модели появляется шанс "прокликать" как можно больше ссылок (в разных сессиях, но при ответе на один и тот же вопрос - то есть паралелльно). Быть может, лучший ответ на поступивший запрос спрятан в сайте с невзрачным описанием, которое видит модель в поисковой выдаче, однако внутри предоставлен наиболее точный ответ - в таком случае обилие посещённых сайтов играет лишь на руку. А главное - никакого обучения, как только получена версия Reward Model. Для генерации используется LM, обученная только на демонстрациях (BC, порядка 6,200 примеров - очень мало по меркам Deep Learning /современного NLP).

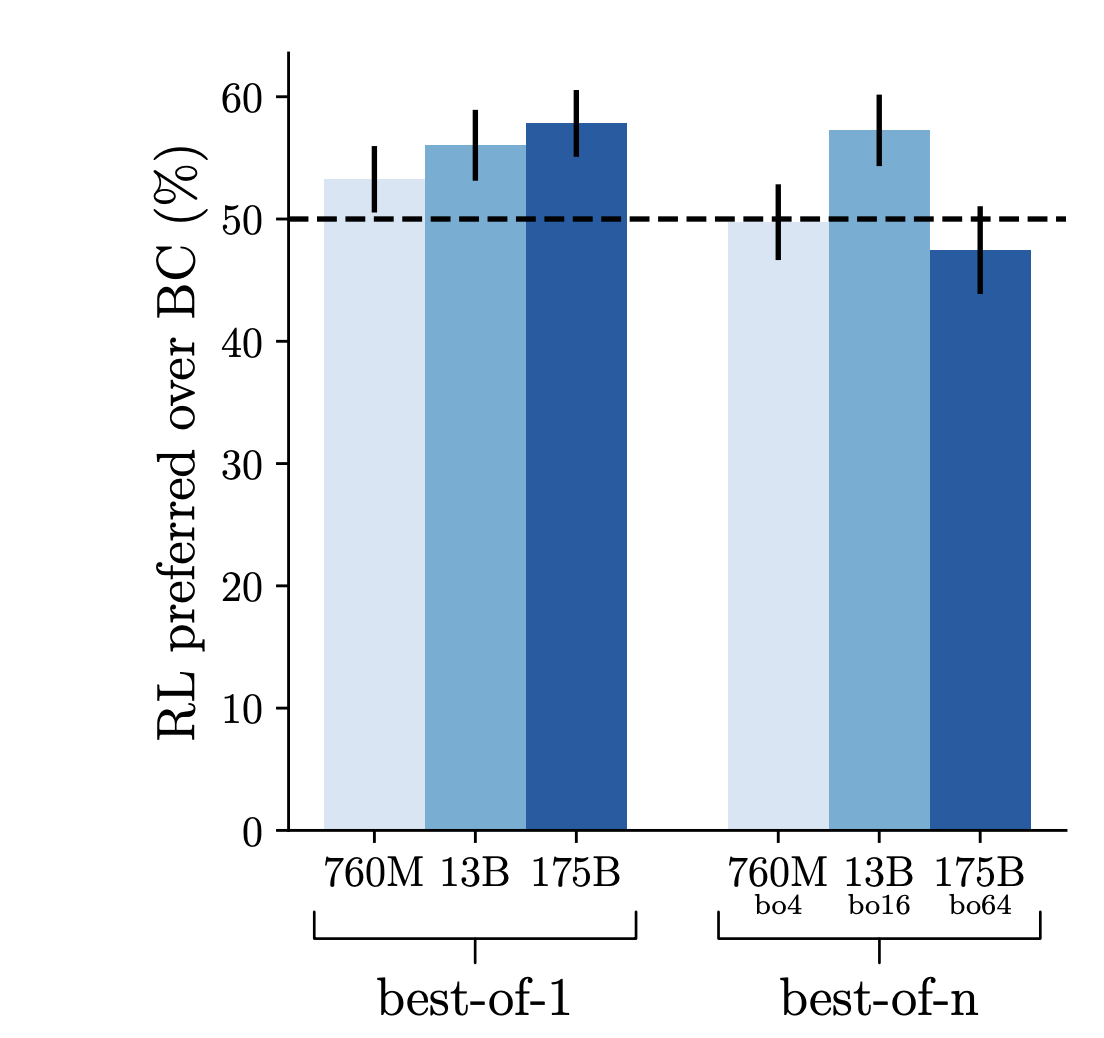
А сколько разнообразных ответов оптимально генерировать для ранжирования, и что вообще такое "оптимально"? Ответы на эти вопросы представлены на картинке слева. Чем больше модель, тем больше генераций можно пробовать ранжировать, и тем больший прирост к метрике это даст. В целом, это логично - большие модели хранят больше знаний, их выдача более разнообразна, а значит может привести к таким сайтам и, как следствие, ответам, которые не встречаются у других моделей. Оптимальными считаются точки перегиба на графике, где прирост метрики за счет наращивания ресурсов начинает уменьшаться. Это значит, что можно взять модель чуть-чуть побольше, натренировать ее и получить метрику немного выше. Однако видно, что даже маленькая модель на 760M параметров может тягаться с 175B гигантом - просто нужно генерировать порядка сотни вариантов (и это всё еще будет на порядок вычислительно эффективнее 2-3 вариантов от LLM GPT-3). Отмеченные на графике звёздочками точки являются оптимальными для рассматриваемых моделей, и именно эти значения будут использовать для рассчета метрик ниже (например, N=16 для средней модели на 13B параметров).
Метрики и восприятие людьми
Начнем с конца - попробуем оценить, какой из методов генерации ответов показывает себя лучше: RL (обучение через моделирование функции оценки ответа) или BoN (без дообучения; множественное семплирование из модели). Может ли их комбинация прирастить качество генерируемых ответов еще сущестеннее?
Попробуем разобраться, как производить такое сравнение. У нас есть модель, обученная исключительно на 6,200 демонстрациях, без прочих трюков, и в режиме языкового моделирования. Напомню, что её называют BC (Behavioral Cloning). Относительно ответов, порождаемых этой моделью, можно проводить сравнения по уже описанному выше принципу с ответами от других моделей. Если качество ответов в среднем одинаковое, то можно ожидать ситуации 50/50 - когда в половине случаев люди предпочтут ответ первой модели, а в половине - второй. Если ответы одной модели стабильно выигрывают в 55% случаев - можно сказать, что - согласно оценке людей - её ответы качественнее.
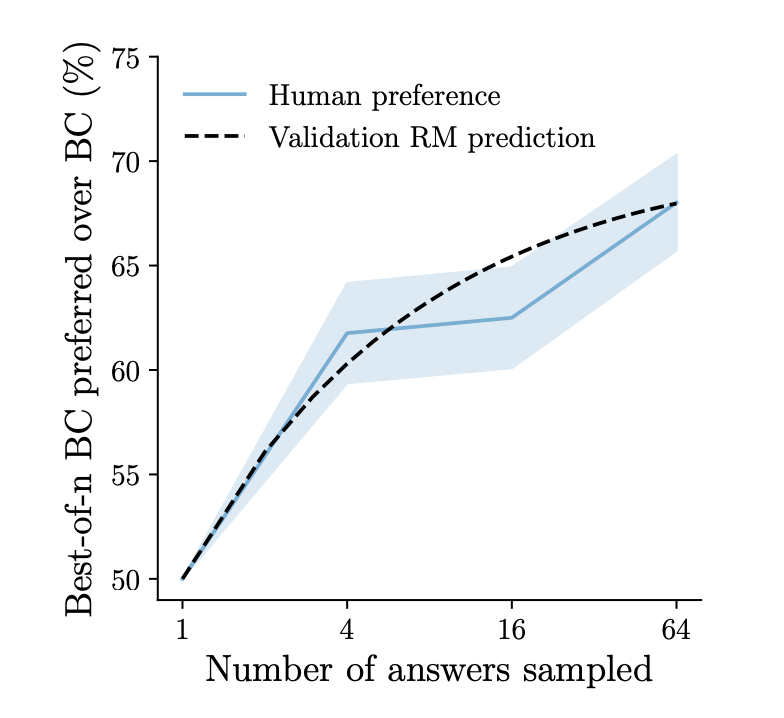
Именно поэтому величина в 50% отмечена пунктирной линией на графике - это наша отправная точка, и мы хотим видеть прирост доли выигранных сравнений относительно заданного уровня. Из графика можно сделать несколько выводов. Во-первых, RL позволяет улучшить модель, натренированную на демонстрациях (то есть все эти трюки с RM и разметкой были не зря!). Во-вторых, самый лучший результат - 58% побед для 175B Bo1 модели. В-третьих, RL и Rejection Sampling плохо сочетаются, и либо ухудшают результат, либо не меняют его существенно (исключение 13B-Bo16 модель, однако это скорее выброс, случившийся из-за маленького размера выборки для оценки).
Если же сравнить отдельно BoN модель (генерация N ответов BC-моделью и ранжирование через оценку RM) с самой BC моделью (то есть параметры сетей одинаковые, отличается только способ получения ответа, и как следствие вычислительная мощность, необходимая для генерации), то процент побед будет равняться 68% (при N=64, что, согласно приведенной оценке выше в статье, является оптимальным значением). Получается, что одной и той же BC модели Bo64 проигрывает в 32% случаев, а RL - в 42%. Разница существенна, если учесть, что метрика рассчитана на реальных человеческих оценках, восприятии. По этой причине дальше авторы статьи большинство экспериментов делают именно с BoN-моделями, а не RL. Но вообще интересно разобраться, почему так может происходить, что дообученная модель хуже показывает себя, чем модель, видевшая лишь 6,200 демонстраций. Можно выдвинуть несколько гипотез или связать это со следующими фактами:
- Исходя из специфики задачи, может быть существенно выгоднее посетить бОльшее количество сайтов, сделать больше попыток запросов в API, чтобы сгенерировать качественный ответ;
- Среда, в которую "играет" наша модель (интернет и вебсайты, поисковый движок), безумно сложна для прогнозирования. В то же время с применением Rejection Sampling модель может попытаться посетить гораздо больше веб-сайтов, и затем оценить полученную информацию через RM;
- RM была натренирована в основном на сравнениях, сгенерированных BC и BoN-моделями, что ведет к смещению в данных. Быть может, если собирать датасет сравнений исключительно под PPO-алгоритм, то проигравший и победитель поменяются местами;
- В конце концов, как было упомянуто выше, RL-алгоритмы требуют настройки гиперпараметров, и хоть PPO в достаточной мере нечувствивтелен к их выбору, всё равно нельзя утверждать, что полученная в результате обучения модель оптимальна, и ее нельзя существенно улучшить;
- Вполне возможно, что в результате неоптимального выбора параметров в пункте 4 произошло переобучение под RM, и модель потеряла обобщающую способность. Как следствие - получает более низкие оценки ответов от людей;
Стоит дополнительно отметить, что немало усилий было приложено и к обучению исходной BC модели. Авторы долго и тщательно подбирали гиперпараметры, и в итоге это привело к существенному сокращению разрыва в метриках, который изначально наблюдался между BC и RL подходами. Таким образом, сам по себе бейзлайн в виде BC достаточно сильный, производящий осмысленные и высокооцененные ответы.
Следующим логичным шагом становится сравнение лучшей модели (175B Bo64) с ответами, написанными самими живыми людьми. Это не упоминалось ранее, однако исходные вопросы для сбора демонстраций и генерации пар на сравнение (в RL/RM частях) были выбраны из датасета ELI5. Он сформирован следующим образом: на Reddit есть сабреддит Explian me Like I'm Five (ELI5), где люди задают вопросы, и в комментариях получают ответы. Для сбора демонстраций при тренировке BC разметчики сами искали ответы на вопрос, прикрепляли источники информации/ссылки (как было описано далеко в начале статьи). Однако в самом датасете ответами считаются самые высокооцененные (залайканные) комментарии, с некоторыми фильтрациями и ограничениями. И формат таких ответов существенно отличается от производимого моделью: там (зачастую) нет ссылок-источников, упоминаемые факты не сопровождаются аннотацией ([1][2] для указания на первый и второй источник, к примеру).
Указанные особенности подводят нас к развилке:
- С одной стороны, мы можем сравнить результаты модели на новых вопросах, демонстрации для которых не участвовали в тренировочной выборке, и для которых есть аннотированные ответы с указанием источников. Такие ответы с нуля написаны живым человеком по результатам его поиска;
- С другой, если на этапе постобработки вырезать блок ссылок из ответа модели, а также их упоминания-референсы в тексте, то такие ответы, в теории, можно сравнить с исходными комментариями людей на Reddit.
Поэтому проведём два сравнения! Однако стоит учесть, что люди, участвовавшие в генерации демонстраций или же в сравнении двух ответов по разным факторам (влкючающим корректность цитирования источника), имеют некоторую смещенную точку зрения на задачу: они уже видели инструкцию по разметке, представляют примерный процесс ответа на вопрос, знакомы с критериями оценки. Их мнение в слегка измененной задаче нельзя назвать незамыленным. Исходя из этого, для человеческой оценки качества оригинальных ответов на Reddit против ответов модели были наняты новые разметчики, которым было сообщено куда меньше деталей о проекте (инструкция занимает буквально пару страниц). Они практически идеально представляют собой усредненное мнение человека, который просто хочет получить вразумительный ответ на свой вопрос.

Оценивалось всего три показателя - общая полезность ответа, согласованность и фактическая точность. На графике слева видно, что большая модель 175B Bo64 генерирует ответы, которые в 56% случаев признаны более полезными, чем ответы, полученные ручным поиском живого человека с последующей ручной компиляцией ответа по источникам. Немного страдает согласованность, а фактическая аккуратность держится на уровне. Можно сказать, что таким сгенерированным ответам стоит доверять, как если бы вы сами искали ответ на вопрос в интернете (не то что ответы ChatGPT или Galactica!). Главный вывод тут - модель выигрывает у написанных людьми ответов в более чем 50% случаев - то есть достигает уровня человека в использовании браузера для поиска информации. Также стоит отметить, что использование обратной связи от людей (пары сравнений для обучения Reward Model) имеет важнейшее значение, поскольку нельзя ожидать превышения планки 50% предпочтений только за счет подражания исходным демонстрациям (в лучшем случае мы научимся делать точно так же, и получится 50/50).
На графике справа, иллюстрирующем сравнение относительно оригинальных ответов из комментариев на Reddit, метрики еще лучше (ответ модели выбирается лучшим из пары 69% случаев). В целом, это не удивительно - люди пишут ответы в свободное время, ничего за это не получая (кроме апвоутов и кармы), и иногда ссылаются на знания из памяти, и не проверяют факты в интернете.
Заключение
Да, полученная модель не гарантирует выверенных и 100% фактологически точных ответов на запросы, однако это гораздо сильнее приближает описанный подход (и ChatGPT вместе с ним) к надежным поисковым системам, которые можно не перепроверять на каждом шагу. Более того, такие модели уже сейчас способны сами добровольно предоставлять источники информации, на которые опираются - а там дело за вами. Для самых терпиливых читателей, добравшихся до заключения, у меня подарок - три сайта, в которых реализованы поисковики на принципах обучения моделей, описываемые в статье:
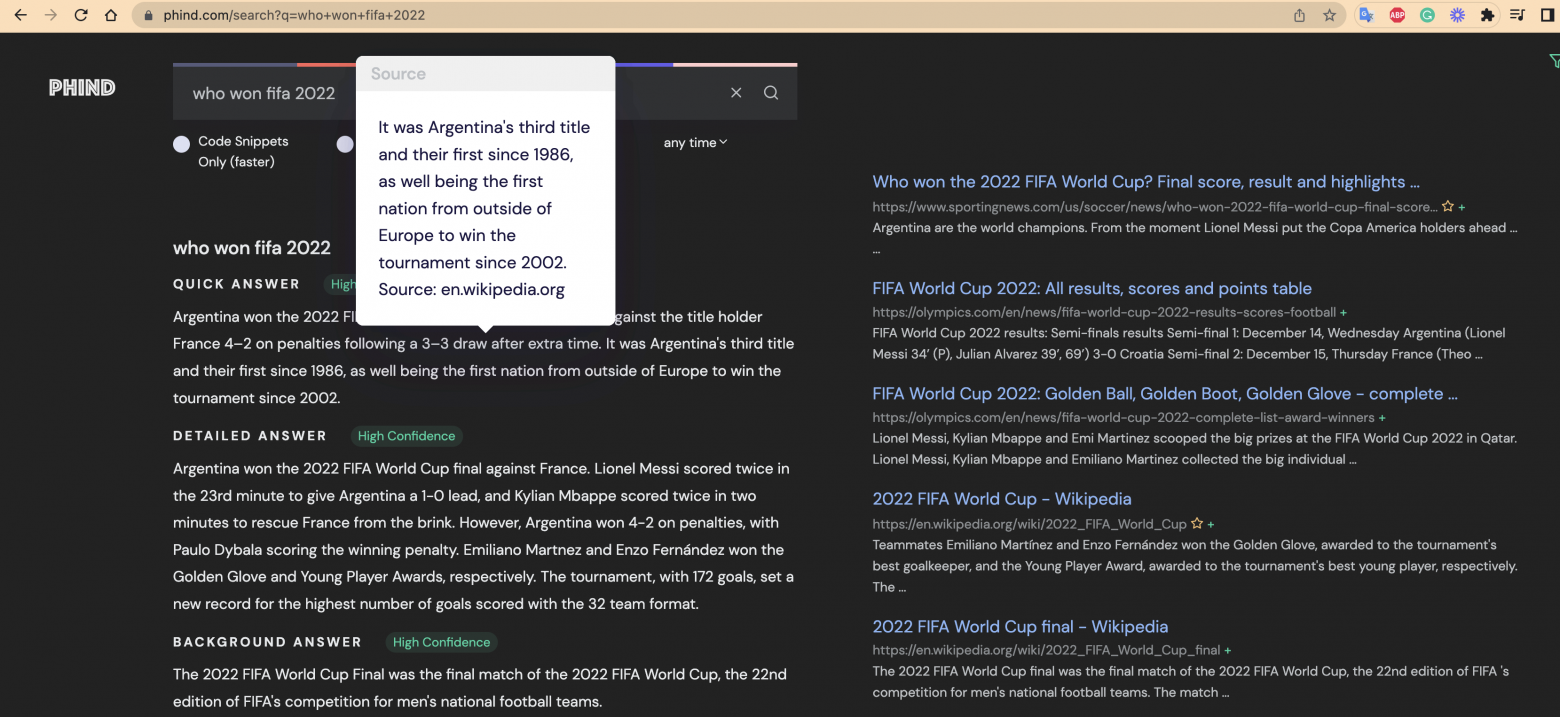
UI: Справа ссылки как будто из Google, слева - ответ, сгенерированных на основе текста из них. Для ответов указан уровень уверенности, а для каждого предложения при наведении доступен источник - просто фантастика! Такие поисковые результаты это нам надо обязательно.
Уже сейчас они предоставляют возможность получать ответ в режиме диалога, и это только начало. У меня очень большие ожидания от 2023го года, и надеюсь, что у вас теперь тоже!
P.S.: разумеется, от метода, разобранного в статье, до готового к внедрению в продакшен решения необходимо преодолеть огромное количество других проблем и инженерных задач. Я выбрал данную тему исходя из ситуации, которую наблюдаю в разнообразных телеграм, слак и прочих чатах: люди массово жалуются и упрекают ChatGPT в том, что она врет, подтасовывает факты. "Как это внедрять в поиск? Оно же даже дату развала СССР не знает!!!". В этом массовому потребителю и видится основная проблема. Надеюсь, что сейчас стало более понятно, как близки мы к новой парадигме обращения с поисковыми системами.

Об авторе
Статья подготовлена и написана Котенковым Игорем (@stalkermustang).