ChatGPT как инструмент для поиска: решаем основную проблему (часть 2)
Базовый принцип обучения WebGPT с учителем
А что такое правильные данные в контексте поиска информации в интернете? Это поисковые сессии реальных пользователей, или демонстрации. Важно разработать метод, как последовательность действий будет представляться модели (причем, языковой модели - то есть хочется еще и переиспользовать ее знания об естественном языке), чтобы получился "понятный" формат. Следует начать со списка действий, которые доступны человеку (и модели):
- Отправить поисковый запрос в API/строку поиска (авторы используют Bing, и вообще коллаборация OpenAI - Microsoft всё масштабнее и масштабнее) и получить ответ;
- Кликнуть на ссылку в выдаче;
- Найти текст на странице;
- Прокрутить страницу вверх или вниз;
- Вернуться на страницу назад.
Это действия связанны с "браузером", но так как мы решаем задачу генерации ответа на вопрос (именно генерации, а не просто поиска - ведь сам поисковый движок Bing выдаст ответ, но он может быть неполным, неточным), то логично добавить еще два шага: это "цитировать/выписать" (то есть запомнить найденный текст со страницы для себя на будущее) и "сформулировать ответ" - чтобы мы могли понять, что модель закончила работу, и последний написанный текст стоит воспринимать как ответ. Опционально можно ограничивать количество действий, предпринимаемых моделью, что на самом деле важно, ведь для получения очередной команды от модели необходимо ждать существенное количество времени (большие модели размерами в несколько десятков миллиардов параметров тратят на генерацию ответа 0.3-20 секунд, в зависимости от длины текста, размера модели и используемых GPU/TPU). Ожидание ответа на вопрос больше минуты явно не способствует улучшению пользовательского опыта.
Команда OpenAI предлагет оригинальное решение перевода пользовательских демонстраций в виртуальный "браузер" для модели, который полностью представлен текстом:
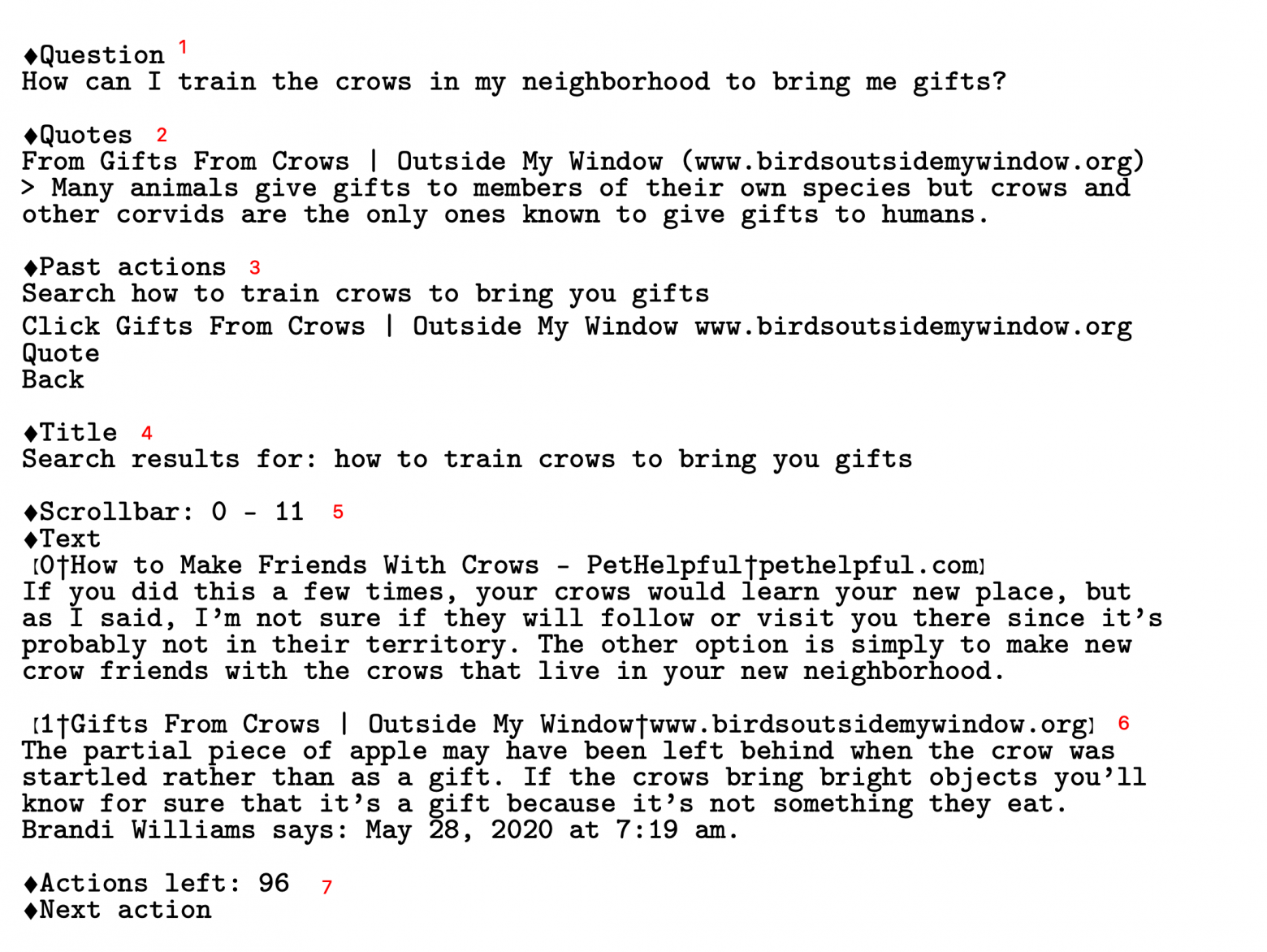
И соответствующий этому cостоянию UI, который видел бы пользователь условного браузера (side-by-side для удобства соотнесения элементов):
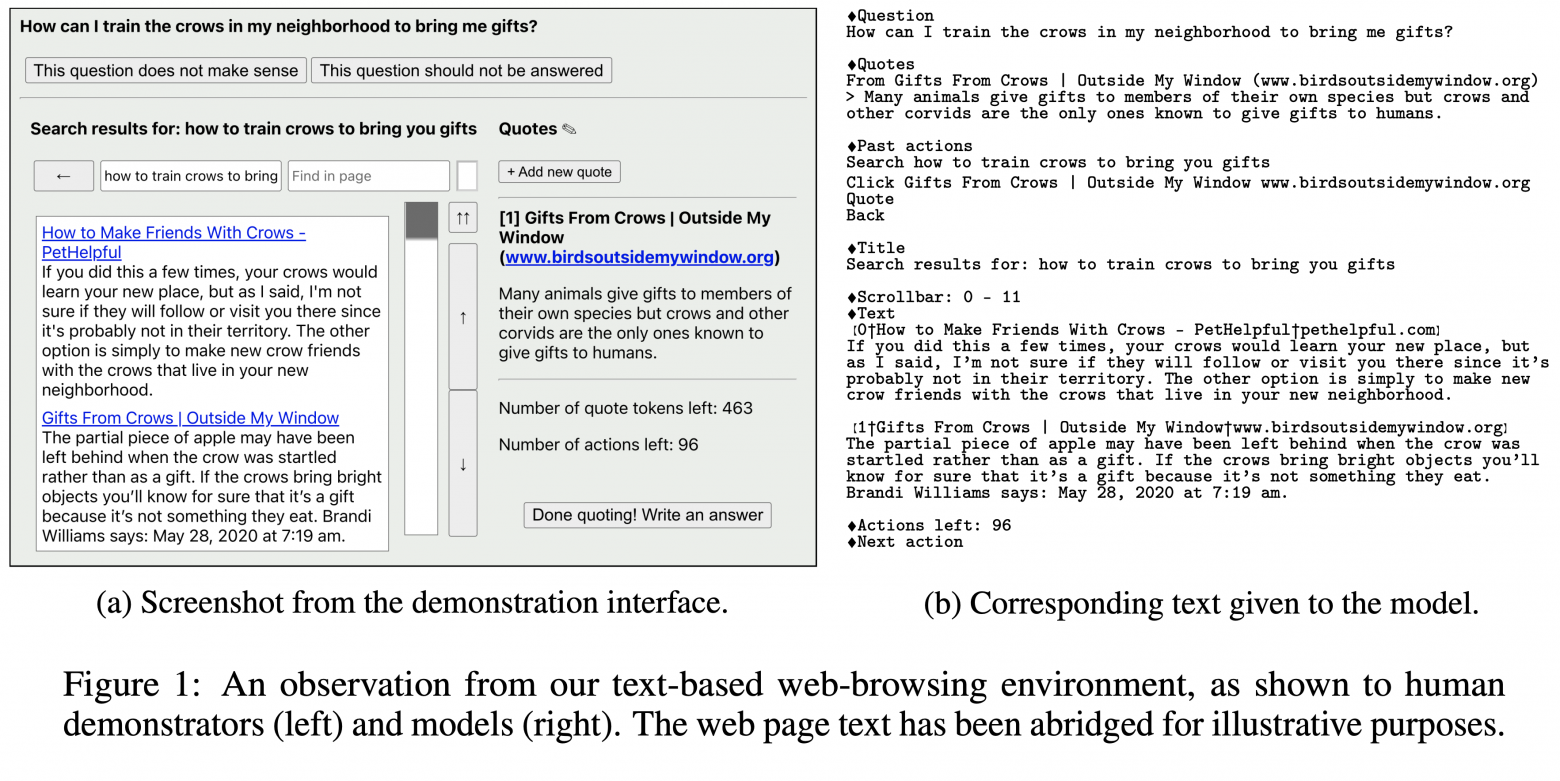
Первое изображение представляет собой текстовое описание текущего состояния, которое подается в модель. Та, в свою очередь, должна предсказать следующее действие (из уже приведенного выше списка). Текст, подающийся в модель, состоит из нескольких блоков (отмечены красными цифрами):
- Основной вопрос, который задан модели. Он не меняется в течение всей работы над одним ответом;
- Блок цитат, которые модель сама себе выписывает. Она сама определяет, с какой части текста по какую цитировать источник. В целом можно сказать, что из этого блока знаний модель и будет генерировать финальный ответ, опираясь на информацию, "отложенную" на будущее в этом блоке. На каждом этапе работы модели видны все цитаты, и LM может понимать, какую информацию сверх этого нужно найти для полного ответа на вопрос, что позволяет писать и отправлять новые запросы в Bing;
- Блок последних выполненных в браузере действий, добавленный для консистентности, чтобы модель не повторялась, и не заходила в петлю одних и тех же команд. Важно понимать, что между двумя соседними "прогонами" текста через LM информация никак не сохраняется, и её веса не меняются. Можно сказать, что у модели нет памяти, и именно этот блок помогает отслеживать траекторию ответа на вопрос, чтобы не запутаться;
- Заголовок текущей страницы. Тут будет отражен реальный заголовок, если модель "кликнула" на какую-либо ссылку;
- Блок текущего окна браузера. Здесь представлено то, что видел бы человек в UI. В конкретном случае предудущее действие - это запрос в API ("how to train crows to bring you gifts", как видно из блока 3), а значит в блоке 5 представлена часть поисковой выдачи (для примера - 2 ссылки, и их краткие описания). Сейчас модель видит строчки 0-11, и, если будет сгенерирована соответствующая команда, страница прокрутится, и станут доступны новые поисковые результаты;
- Вторая ссылка из выдачи поисковика, по сути то же самое, что и блок 5;
- Счетчик оставшихся действий (каждый раз уменьшается на единицу) и запрос следующей команды от модели (Next Action), которая должна быть сгенерирована.
Всё это описано текстом, и подается в текстовую модель как контекст в надежде на то, что в ответ LM сгенериурет следующую команду (вроде "кликни на ссылку один" или "промотай страницу вниз"). Такой контекст называется prompt (промпт). Чем он "качественнее", чем ближе он к тому, что понимают модели (что они видели во время тренировки), тем лучше модель генерирует ответы.

Интересный факт про промпты
Вообще работа над промптами - вещь очень важная. Вы могли об этом слышать или даже заметить самостоятельно, если пытались сгенерировать что-то в MidJourney / DALL-E 2 / Stable Diffusion. Простой запрос на генерацию изображения может вас не удовлетворить, но если добавить теги "screenshot in a typical pixar movie, disney infinity 3 star wars style, volumetric lighting, subsurface scattering, photorealistic, octane render, medium shot, studio ghibli, pixar and disney animation, sharp, rendered in unreal engine 5, anime key art by greg rutkowski and josh black, bloom, dramatic lighting" - то результат может приятно удивить :)
Еще важнее роль промптов при генерации текста языковыми моделями. Мой любимый пример - это добавление фразы "Let's think step by step" в конец запроса с задачей на несколько действий (было представлено в этой статье).

Данная фраза "включает" режим CoT, что означает "chain-of-thought", или цепочка рассуждений/мыслей. Включает не в прямом смысле - скорее просто заставляет модель следовать этой инструкции, и писать выкладки одну за другой. Интересно, что такой эффект значимо проявляется только у больших языковых моделей (Large Language Models, LLMs) - обратите внимание на ось OX, где указаны размеры моделей (в миллиардах параметров):
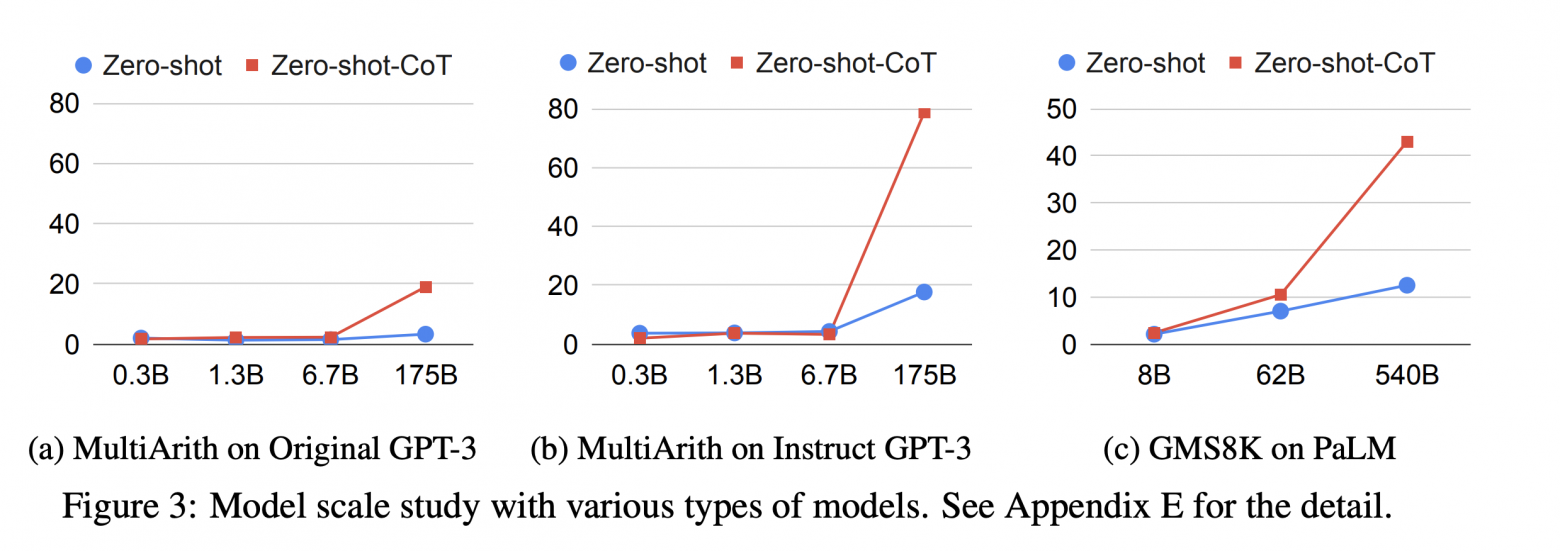
По оси OY указаны метрики на некоторых датасетах. Видно, как добавление всего лишь одной фразы магическим образом существенно увеличивает качество - но только при соответствующих размерах.
Описание (ссылка на телеграм) еще одного примера промптинга для выполнения сложных задач.
На мой взгляд, важны тут две вещи: то, что модель сама формулирует запросы в браузер, и то, что она умеет выписывать ответы во "внешнюю память" (на листочек :) ). Именно с помощью этих двух механизмов и удается на основе цитат сформулировать полный ответ, подкрепленный фактами и источниками.
Итак, человеческие демонстрации собраны, поисковые сессии переведены в текстовую информацию, и теперь можно дообучить уже существующую языковую модель в классическом режиме предсказания следующего слова, чтобы она скопировала поведение реальных людей при поиске ответов. На этапе тренировки модель каждый раз видит, какой Next Action был выполнен человеком, и учится по промпту (текущему состоянию, с цитатами и поисковой выдачей) это следующее действие угадывать. На этапе предсказания же, как было показано на скриншотах выше (блок 7) промпт в конце содержит фразу "Next Action", а модель в режиме генерации текста уже сама отдает команду. Всего для обучения использовалось 6,209 демонстраций (из интересного - публично доступна инструкция для краудсорсеров; оцените полноту описания задачи и действий. Из своего опыта знаю, что собрать данные от разных людей с разными мнениями бывает очень тяжело, данные друг другу противоречат, и тем важнее максимально подробно донести до исполнителей, что от них требуется). Полученную модель назовем BC-моделью, где BC означает Behavioral Cloning (клонирование поведения), потому что она училась повторять за людьми.
Готова ли наша модель?
Шаг обучения WebGPT для продвинутых: готовим данные
На самом деле нет :) эти демонстрации лишь показали модели, как взаимодействовать с браузером, что от модели ожидается в качестве команд к действию (Next Action), и как в общем генерировать запросы в Bing API. Финальная цель - сделать модель, которая оптимизирована под качество ответов (измеренное людским мнением), включая, но не ограничиваясь, правдивостью ответа. Тренировка на демонстрациях же не оптимизирует эту метрику каким либо образом. Обратите внимание, это в целом очень частая проблема в машинном обучении - модели обучаются на какую-то прокси-функцию, которая, как мы верим, сильно скоррелированна с метрикой реального мира. Скажем, можно минимизировать квадрат ошибки предсказания продаж в магазине на следующей неделе, но ведь реальная метрика - это деньги, заработанные или полученные компанией. Не всегда удается достигнуть высокой корреляции между этими двумя вещами. Как же обучить модель напрямую оптимизировать предпочтения реальных людей?
В самом слове "предпочтение" есть что-то, что наталкивают на идею сравнений. Оценить какой-то объект в вакууме (абстрактной цифрой от 1 до 10, например, как это часто бывает с фильмами или играми) куда сложнее, чем отранжировать его относительно другого схожего объекта. Само определение подсказывает: "Предпочтение - преимущественное внимание, одобрение, уважение к одному из нескольких вариантов, желание выбрать один из нескольких вариантов". Тогда, чтобы обучить модель производить ответы, которые наиболее предпочтительны с точки зрения людей, необходимо создать набор пар для сравнения. В контексте ответов на вопросы с помощью поисковой системы это означает, что на один и тот же вопрос предлагается два разных ответа (возможно даже с разным выводом из этих ответов), разные наборы источников, из которых этот ответ собран/сгенерирован.
Такие пары для сравнения (имея обученную на демонстрациях модель) получать очень легко - LMки это алгоритмы вероятностные, как было упомянуто ранее, поэтому можно семплировать действия при генерации команд или ответе на вопрос. Простой пример: модель после получения запроса предсказывает команду "кликни на ссылку 1" с вероятностью 40%, и команду "промотай вниз, к следующему набору ссылок" с вероятностью 37%. Уже на этом этапе доступна развилка в дальнейшей логике поиска информации, и можно запустить эти два процесса в параллель. Таким образом, через сколько-то действий каждая модель придет к ответу, но разными путями. Их мы и предложим сравнить человеку (финальные ответы и подкрепляющие их источники, не пути).

При оценке каждого из двух ответов используются следующие критерии:
- Содержит ли ответ неподкрепленную источниками информацию?
- Предоставлен ли ответ на основной вопрос?
- Присутствует ли дополнительная полезная информация, которая не требуется для ответа на вопрос?
- Насколько ответ последователен, и есть ли в нем ошибки цитирования источников/самого себя?
- Сколько нерелевантной информации в тексте ответа?
По этим критериям ответы сравниваются, и человек выбирает из 5 обобщённых опций, которые используются в качестве разметки на следующем этапе обучения (А сильно лучше Б, А лучше Б, А и Б одинаковые, А хуже Б, А сильно хуже Б). Полная инструкция для исполнителей также доступна. Интересный факт: исполнители не обязаны делать проверку фактов, указанных в источниках, процитированных моделью. Получается, люди оценивают то, насколько хорошо модель умеет опираться на уже предоставленные факты (размещенные на страницах в интернете), без факт-чеккинга.
WebGPT не сёрфят
Как во время обучения, так и во время генерации ответов WebGPT имеет прямой доступ к сети Интернет - однако все заимодействия ограничены возможностью отправки запросов в единственное API. Это позволяет модели давать актуальные ответы на широкий круг вопросов, но потенциально создает риски как для пользователя (некорректные ответы), так и для других юзеров. Например, если бы у модели был доступ к веб-формам/веб-редакторам, она могла бы исправить данные в Википедии, чтобы создать надежную ссылку с указанием источника конкретного ложного факта. Даже если бы люди-демонстраторы не вели себя подобным образом во время сбора тренировочных данных, такое поведение, скорее всего, было бы подкреплено и закреплено во время обучения, если бы модель наткнулась на него случайно. Подробнее про эксплуатацию несовершества среды и фунцкции награды см. ниже.
Более мощные модели могут представлять серьёзные риски. По этой причине авторы статьи считают, что по мере расширешния возможностей обучаемых моделей бремя доказательства безопасности при предоставлении доступа к системам реального мира должно лежать на плечах людей - даже во время процедуры тренировки.
Авторы подчеркивают, что это проблема для будущих исследований и статей. Я добавлю, что её абсолютно точно необходимо будет решить перед переносом аналога WebGPT в продакшен - например, добавить рейтинги доверия сайтам; указывать, что источник ненадежный; учиться фильтровать источники по агрегированной информации (4 сайта указывают дату, отличную от выбранного источника? тогда этот факт как ненадежный, и не используем в цитировании); наконец, оценка верности факта самой моделью: насколько вероятно, что обычная LM дала бы тот же ответ?
Заметка про надежность сайтов и фактов
Вообще, оценка правдивости ответа и надежность источников - вещь нетривиальная. Некоторые вопросы требуют того, чтобы оценщик разбирался в узкой области (программирование, медицина, языковедение). Даже с опорой на источники и интернет можно столкнуться с неочевидной проблемой - достаточно мощная модель будет выбирать источники, которые, по ее мнению, люди сочтут убедительными, даже если они не отражают реальные факты. Таким образом, нейросеть может "взломать" наше восприятие, и подкидывать ложную информацию, но под красивой и аккуратной обёрткой - а мы и не заметим.
Еще стоит рассмотреть вопрос психологии - ответы с указанием источников всегда кажутся более авторитетными. Это идёт вразрез с фактом, что сами модели всё еще могут делать простейшие ошибки.
Теперь, когда мы обсудили, как собрать данные предпочтений, чтобы "выровнять" нашу модель относительно намерений пользователей во время поиска информации, поговорим про принцип обучения. Проблема с предпочтениями и сравнениями в том, что процесс разметки таких данных занимает много времени. Нужно погрузиться в каждый вопрос, ответ, проанализировать источники, выставить оценки. Получение большого количества данных либо займет много времени, либо будет стоить огромных денег. Но что если нам не нужно размечать каждую пару? Что если мы, как инженеры машинного обучения, научим другую модель сравнивать пары ответов за людей?
Шаг обучения WebGPT для продвинутых: учим модель учить модель
В предшествующих исследованиях OpenAI было эмпирически выяснено, что модели в целом хорошо предсказывают реакции людей и их оценки в задачах, связанных с генерацией комплексных ответов. Вырисовывается следующая схема, которая является ключевой для обучения по обратной связи от людей (human feedback):
- Генерируем набор пар для сравнения, используя модель, обученную на демонстрациях (она уже умеет "серфить" интернет, писать запросы и "кликать" по ссылкам, то есть выдавать соответствующие команды в виде текста);
- Размечаем пары с использованием людей;
- Тренируем другую модель предсказывать разметку людей (какой ответ из пары получит более высокий ответ) на парах из п.2. Назовем такую модель Reward Model (RM). Она принимает на вход вопрос и финальный сгенерированный ответ (без промежуточных шагов вроде прокрутки браузера), а выдаёт одно вещественное число (оно еще называется наградой, или Reward - по историческим причинам). Чем больше это число - тем выше вероятность того, что человек высоко оценит этот ответ по сравнению с остальными. Можно считать, что это условный ELO-рейтинг, как в шахматах;
- Обучаем основную модель (BC) на основе оценок от модели из п. 3; По сути LM учится решать задачу "как мне поменять свой сгенерированный ответ так, чтобы получить большую оценку RM?";
- Повторяем пункты 1-4 итеративно.
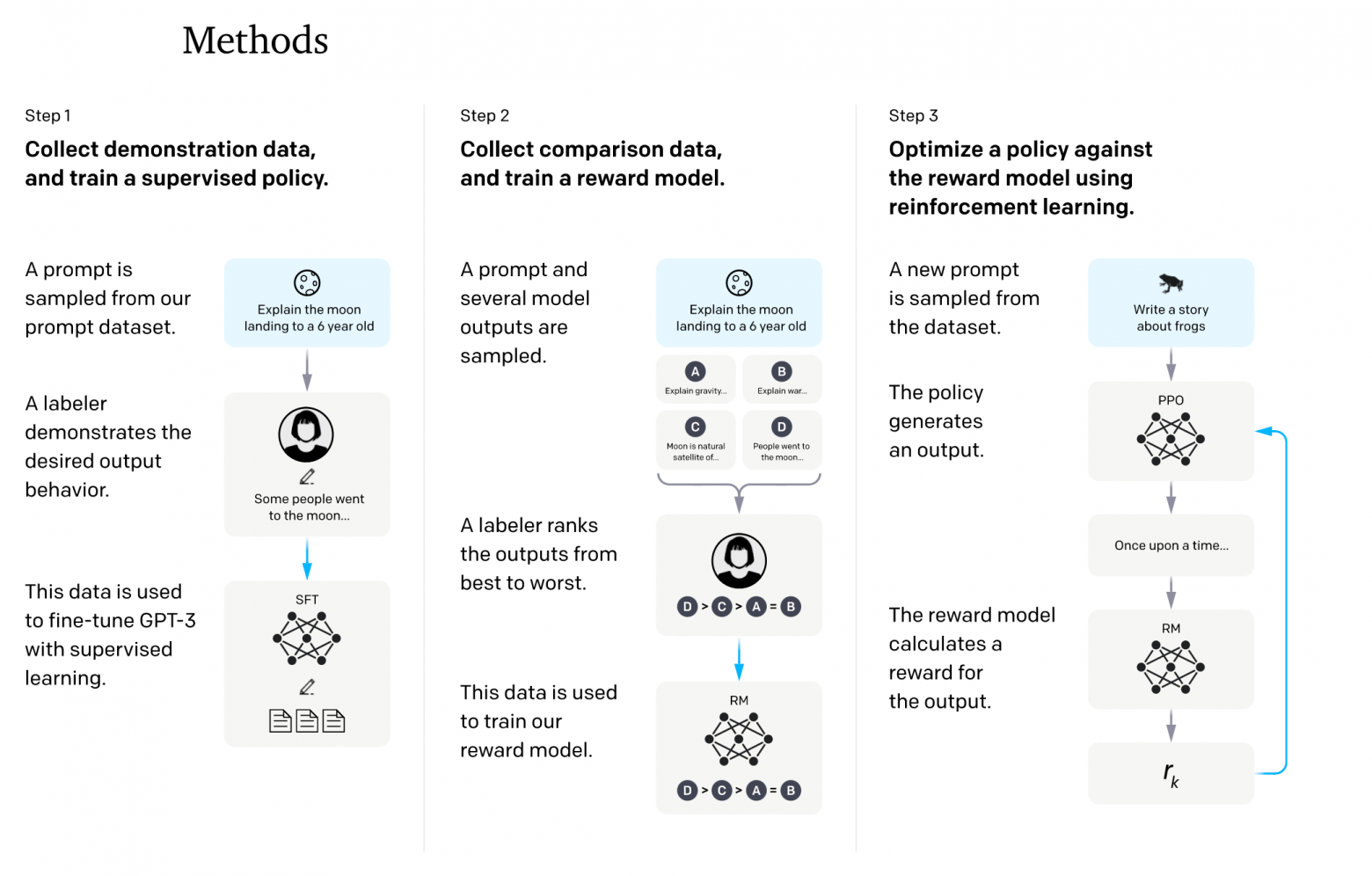
Step 2 в центре: собираем ответы текущей модели (п.1 в плане), размечаем (п.2), тренируем RM (п.3)
Step 3 справа: на новых данных производим оценку новых пар сгенерированных ответов, дообучаем WebGPT (п.4)
Этот пайплайн имеет две ключевые особенности. Во-первых, его можно повторять итеративно, улучшая именно текущую модель, со всеми ее минусами и плюсами. Если LM в какой-то момент начала обманывать, или использовать несуществующие факты (дефект обучения) - это будет заметно на разметке людьми, и соответствующие ответы получат низкие оценки. В будущем модели будет невыгодно повторять подобное (возникнет negative feedback). А во-вторых, и это просто прекрасно - используя RM из пункта 3, мы можем сгенерировать оценки для куда большего количества пар (и гораздо быстрее), чем если бы это делали люди. Следите за руками: берем любые доступные вопросы из интернета, из датасетов или даже специально заготовленные, на которых модель еще не обучалась, генерируем ответы, оцениваем их автоматически, без привлечения людей, и уже на основе этих оценок дообучаем основную WebGPT. Если люди могут за, скажем 10,000$ разметить 5,000 пар за неделю, то 1 землекоп RM может за день отранжировать десятки и сотни тысяч пар ответов фактически за копейки.
Каким методом производить обучение в таком необычном случае?
В машинном обучении выделяют несколько "царств" (или скорее направлений) алгоритмов обучения. Детали меняются от одной классификации к другой, где-то происходит обобщение по конкретным критериям, но практически всегда и везде упоминается три основных подхода:
- Обучение с учителем (Supervised Learning) - когда есть размеченные данные, и нужно научиться на их основе обобщать знания на генеральную совокупность всех объектов. Сюда относятся модели для классификации, регрессии (предсказание числовых величин);
- Обучение без учителя (Unsupervised Learning) - когда разметки нет, но хочется каким-то образом извлечь знания из данных. Популярный пример - разнообразные кластеризации и выделение когорт;
- Обучение с подкреплением (Reinforcement Rearning, RL) - когда есть некоторые особенности получения данных, и их качество зависит от самого подхода. Именно методы из этой категории учатся играть в шахматы, в го и любые компьютерные игры (чтобы получить данные - надо играть, и чем выше уровень игры, тем лучше данные).

Как легко догадаться по описанию пайплана обучения WebGPT - нам подходит третий вариант. RL методы взаимодействуют со средой (или окружением, environment), посылают в нее выбранные действия, получают обновленное состояние (описание мира), и пытаются найти лучшую стратегию. Очень часто система получения награды, которую и старается максимизировать алгоритм, недоступна: для игры го нельзя сказать, является ли в моменте одна позиция выигрышнее другой (ведь партию можно доиграть по-разному); в игре Minecraft вообще почти не ясна связь деревянной кирки и добычи алмаза - по крайней мере до тех пор, пока сам игрок один раз не пройдет путь от начала и до конца. Поэтому в мире обучения с подкреплением используют моделирование награды, и это в точности то, для чего мы обучали Reward Model - предсказывать предпочтения человека. Таким образом снижается требование к количеству реальных взаимодействий со средой (людьми-разметчиками с почасовой оплатой) - ведь можно опираться на выученную из предоставленной разметки закономерность.
За долгие годы развития направления RL было придумано множество алгоритмов, с разными трюками и ухищрениями (чаще всего - под конкретные типы задач, без возможности обобщиться на любые произвольные цели). Иногда для успешного обучения нужно вручную конструировать принцип оценки действий модели - то есть вручную указывать, что, например, действие А в ситуации Б нанесет урон вашему персонажу, и тот получит меньшую награду. Все это плохо масштабируется, и потому ценятся стабильные методы, выступающие в роли швейцарского ножа. Они хорошо обобщаются, не требуют тончайшей настройки и просто работают "из коробки".
Один из таких методов - Proximal Policy Optimization, или PPO. Он был разработан командой OpenAI в 2017м году, и как раз соответствовал требованиям простого прикладного инструмента, решающего большой спектр задач. Мы не будем погружаться в детали его работы, так как по этой теме можно прочитать не то что отдельную лекцию - целый курс. Общий смысл алгоритма в том, что мы обучаем модель-критика, которая оценивает наш текущий результат, и мы стараемся взаимодействовать со средой лучше, чем в среднем предсказывает критик. Критик в оригинале очень похож на описанную раннее Reward Model.
Сам же алгоритм был протестирован командой OpenAI на разнообразных задачах, включая сложную компьютерную игру, требующую кооперации нескольких игроков (или моделей) и далёкий горизонт планирования - DotA 2. Полученная модель (с некоторыми игровыми ограничениями) выигрывала у чемпионов мира - более подробно об этом можно прочитать в официальном блоге (даже записи всех игр доступны!).

Важное замечение по Reward Model для графиков ниже по статье: часто по оси OY будет Reward Value (оно же RM Score). Для удобства сравнения, во всех случаях предсказания RM были стандартизированы, то есть из предсказанного значения вычитали среднее по всем генерациям (поэтому среднее значение теперь равно нулю; и больше нуля - значит лучше среднего), и полученную разность делили на стандартное отклонение (поэтому в большинстве случаев Reward находится в интервале [-1; 1]). Однако основная логика сохраняется - чем больше значение, тем лучше оценен ответ.
В такой постановке задачи оптимизации очень легко переобучить модель под конкретную Reward Model, а не под оценки разметчиков, под общую логику. Если это произойдет, то LM начнет эксплуатировать несовершества RM - а они обязательно будут, как минимум потому, что количество данных, на которых она тренируется, очень мало (суммарно на всех итерациях оценено порядка 21,500 пар, но для тренировки доступно 16,000), и её оценка не в точности повторяет оценки людей. Можно представить случай, что RM в среднем дает более высокую оценку ответам, в которых встречается какое-то конкретное слово. Тогда WebGPT, чрезмерно оптимизирующая оценку RM (вместо людской оценки, как прокси-метрику), начнет по поводу и без вставлять такое слово в свои ответы. Подобное поведение продемонстрировано в другой, более ранней статье OpenAI, с первыми попытками обучения моделей по обратной связи от людей:

Поэтому очень важно подойти основательно к процессу итеративного обучения двух моделей.
Заметка про актуальность проблемы
Так считает и сама OpenAI - аккурат перед выходом ChatGPT была опубликована статья с глубоким анализом процесса излишней оптимизации под RM: Scaling Laws for Reward Model Overoptimization. В ней исследователи пытаются разобраться, как долго можно тренировать LM-модель относительно RM, без добавления новых данных от людей, чтобы не терять в качестве генерации, и в то же время максимально эффективно использовать существующую разметку. Интересно то, что эксперименты ставятся по отношению к другой, второй RM (Gold на графике ниже), которая выступает в роли "реальных людей" - и экспериментально показывается, что ее оценка начинает с какого-то момента падать, хотя по основной RM, на основе которой тренируется аналог WebGPT, виден рост. Это демонстрирует ровно описанный выше эффект овероптимизации, переобучения, когда оценки RM перестают соответствовать ощущению людей-разметчиков.
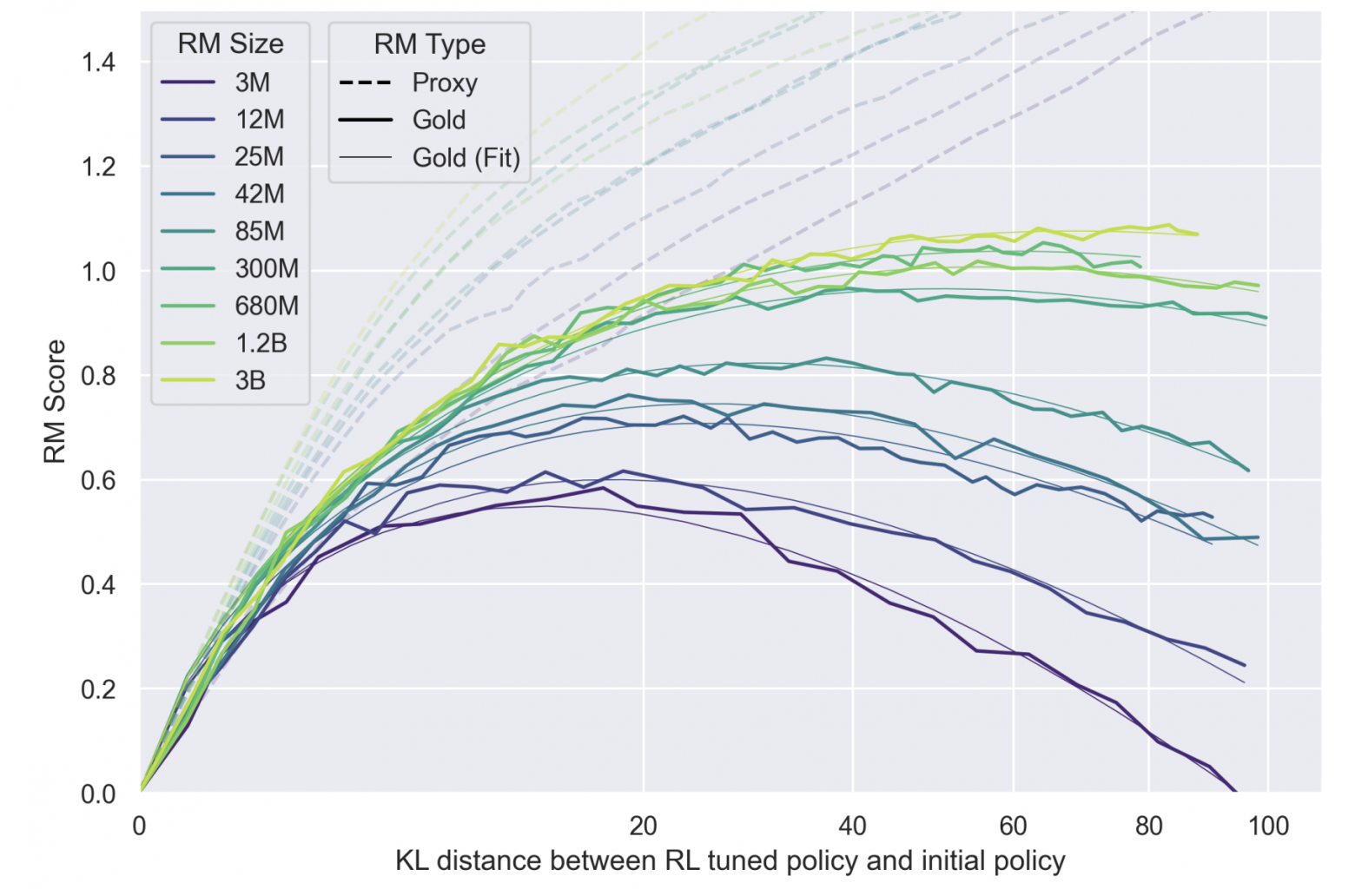
По оси OX - длительность обучения модели (измеренная в отклонении предсказаний от исходной модели, обученной на демонстрациях. Чем больше отклонение - тем дольше учится модель, при прочих равных). По оси OY - оценка RM. Пунктирные линии - оценки основной RM, сплошные - оценки "настоящей" RM, имитирующей оценки людей (не дообучается в процессе эксперимента). Обратите внимание, что ось OY начинается в нуле - потому что это среднее значение оценки Reward после стандартизации (формулу и процесс см. выше). Чем выше RM Score, тем больше модель "выигрывает" в оценке своих ответов относительно исходной модели.
Видно, что пунктирные линии показывают рост, так как мы оптимизируем их предсказания напрямую. В это же время оценки "настоящие", полученные как будто бы от людей, падают - при чём тем быстрее, чем меньше размер RM. Так, оптимизация против самой "толстой" модели на 3 миллиарда параметров не приводит к деградации - оценка выходит на плато. Второй интересный вывод - чем больше параметров в RM (чем светлее линия), тем выше средняя оценка модели, полученная обучением против такой RM. Это, конечно, не открытие - мол, бери модель потолще, и будет обучаться лучше - однако подтверждает тезис о том, что переобучения при тренировке RM на разметку людей не происходит (при правильном подходе и гиперпараметрах), а еще позволяет численно оценить эффект прироста в качестве генерации.
Курьёзные случаи эксплуатации неидеальности условий награды
С методами в RL есть одна проблема - они очень эффективны в эксплуатации уязвимостей среды. Они пойдут на любые меры, чтобы получить как можно большую награду (максимизируют Reward). Некоторыми подобными примерами мне захотелось поделиться с вами, для наглядности:
Предположим, у вас есть двуногий собаковидный робот, ограниченный вертикальной плоскостью, то есть он может бегать только вперед или назад. Цель – научиться бегать. В качестве награды выступает ускорение робота. Нейросеть должна управлять сокращением мышц, чтобы контролировать движение. Что может пойти не так?
Произошел "reward hacking", или взлом принципа начисления награды. Со стороны это действительно может выглядеть глупо. Но мы можем это сказать только потому, что мы можем видеть вид от третьего лица и иметь кучу заранее подготовленных знаний, которые говорят нам, что бегать на ногах лучше. RL-алгоритм этого не знает! Он видит текущее состояние, пробует разные действия и знает, что получает какое-то положительное вознаграждение за ускорение. Вот и все! Если вы думаете, что в реальной жизни такого не бывает, то...

Более простой пример, когда ожидания могут не совпадать с получаемым поведением. Пусть есть балка, закрепленная на вращающемся шарнире в двумерной плоскости. Модель может давать команды вращать балку по часовой стрелке или против. Всего два действия. Задача - держать балку в стабильном сбалансированном положении и выше нижней половины. Всё очень просто - ставим её идеально вертикально, и готово!
Или не совсем готово. Мы не штрафуем алгоритм за приложение излишних усилий. Мы не формулируем задачу как "выровняй балку наименьшими усилиями". Почему бы тогда не держать её на весу, постоянно прокручивая шарнир по часовой стрелке? Великолепная стратегия, просто, блин, чудесная, если я правильно понял. Надёжная как швейцарские часы. Больше примеров и рассуждений можно найти тут.
И последнее - блогпост OpenAI про модели для игры в прятки, где были найдены и выучены очень сложные паттерны действий. Сами по себе эти действия не являются "обманами" среды или функции награды (Reward), но служат ответами на изменившееся поведение оппонента, эксплуатируя его предсказуемость. Враг закрылся в углу стенами? Принесу лестницу и перелезу. Соперник несет лестницу? Превентивно отберу её. И так далее, и так далее... Видео с объяснением:
Интересный факт про RL-подход: для улучшения сходимости, а также уменьшения количества необходимых данных при общей процедуре обучения, авторы раз в несколько шагов добавляли 15 эпизодов генерации финального текстового ответа по уже набранным источникам информации. Это позволяет писать более связные и консистентные ответы, и наилучшим образом (с точки зрения Reward Model, то есть почти человеческой оценки) использовать источники и текст из них.
Об авторе
Статья подготовлена и написана Котенковым Игорем (@stalkermustang).