ChatGPT как инструмент для поиска: решаем основную проблему (часть 1)
Вышедшая чуть больше месяца назад ChatGPT уже успела нашуметь: школьникам в Нью-Йорке запрещают использовать нейросеть в качестве помощника, её же ответы теперь не принимаются на StackOverflow, а Microsoft планирует интеграцию в поисковик Bing - чем, кстати, безумно обеспокоен СЕО Alphabet (Google) Сундар Пичаи. Настолько обеспокоен, что в своём письме-обращении к сотрудникам объявляет "Code Red" ситуацию. В то же время Сэм Альтман, CEO OpenAI - компании, разработавшей эту модель - заявляет, что полагаться на ответы ChatGPT пока не стоит:
Насколько мы действительно близки к внедрению продвинутых чат-ботов в поисковые системы, как может выглядеть новый интерфейс взаимодействия, и какие основные проблемы есть на пути интеграции? Могут ли модели сёрфить интернет бок о бок с традиционными поисковиками? На эти и многие другие вопросы постараемся ответить под катом.
Данная статья в сущности представляет собой разбор подхода WebGPT (одного из предков ChatGPT), но с большим количеством сопроводительной и уточняющей информации, а также моих комментариев и мнений. Предполагается, что целевая аудитория не погружена глубоко в технические детали обучения языковых моделей, да и в тему NLP в целом, однако статья будет полезна и экспертам этих областей. Сначала будет дано верхнеуровневое описание ситуации и проблем, а затем - более подробное, обильно снабжённое пояснениями потенциальное решение.
Даже если у вас нет знаний в машинном обучении - эта статья будет полезна и максимально информативна. Все примеры проиллюстрированы и объяснены.
План статьи
- Языковые модели и факты;
- А врут ли модели?
- Ответы, подкрепленные источниками и фактами;
- Базовый принцип обучения WebGPT с учителем;
- Шаг обучения WebGPT для продвинутых: готовим данные;
- Шаг обучения WebGPT для продвинутых: учим модель учить модель;
- Регуляризация при обучении WebGPT;
- Альтернатива RL: меняем шило на мыло;
- Метрики и восприятие людьми;
- Заключение.
Языковые модели и факты
Языковые модели, или Language Models (LM), решают очень простую задачу: предсказание следующего слова (или токена, части слова). Через такой простой фреймворк можно решать огромное множество задач: перевод текста, ответы на вопросы, классификация, регрессия (предсказывать слова вроде "3.7" или "0451", если задача сгенерировать вещественное число или код для сейфа), рекомендация, поиск... Даже команды роботам можно давать! Для обученной языковой модели на вход можно подать текст, а она допишет его, сгенерировав продолжение. Самый простой и понятный пример - клавиатура смартфона, предсказывающая по введеному тексту то, что будет написано дальше.
Если вам хочется глубже и в деталях разобраться в принципах работы LMок, то рекомендую начать вот с этих ссылок: раз, два, три.
А что такое токен?
Токен - это символ или набор символов, которые можно подать в языковую модель. Токенизация делается по принципу схлопывания наиболее частых сочетаний символов и повторяется раз за разом до тех пор, пока размер "словаря" (набора токенов) не достигнет предела (50к или 250к, как пример). Часто токены могут представлять собой целые слова, если это - одни из самых популярных слов в языке. Слово "unhappy" можно токенизировать как un+happy, а "don't" - как don + 't (потому что окончание 't, выражающее отрицание, встречается часто).
Токенизация - процесс перевода текста в упорядоченный набор токенов - позволяет представить любой набор символов как набор понятных модели частиц. Иными словами, нейронным сетям так проще работать с текстовой информацией. Языковые модели генерируют по одному токену за раз. В дальнейшем в статье "токен" и "слово" будут упоминаться как взаимозаменяемые.
Посмотреть на примеры токенизации вашего произвольного текста для ChatGPT/WebGPT/GPT3 можно вот тут. Все эти модели используют один и тот же словарь, поэтому и разбиения получаются одинаковыми.
Если задуматься, что находится внутри языковой модели, что она выучивает для решения задачи предсказания следующего токена, то условно всё можно разделить на две большие группы: факты/знания реального мира и общеязыковая информация. Ответ на вопрос "В каком году состоялся релиз фильма X?" требует фактической информации, и необходимо быть предельно точным в ответе - ведь ошибка на +-1 год делает ответ неверным. С другой стороны, в предложении "Катя не смогла перейти дорогу, потому что та была мокрой" слово "та" в придаточной части явно относится к объекту "дорога", а не к Кате. Это ясно нам, человекам, и как показывают современные языковые модели - это понятно и им. Но для установления этой связи не нужно знать фактов, только структуру языка.
Проблема в том, что и ту, и другую составляющую модель будет учить одновременно, сохраняя информацию в свои веса (параметры). Отсюда логичный вывод - чем больше модель, тем больше она запоминает (ведь количество общеязыковой информации ограничено). Меморизация может порой удивлять - GPT-3, к примеру, знает точный MD5-hash строки "b", и выводит его по запросу. Но у всего есть пределы, и, к сожалению, в языковых моделях мы пока не научились их определять (хотя работы в этом направлении ведутся). На текущем этапе их (или нашего?) развития невозможно заведомо сказать, знает ли модель что-то, и знает ли она, что она не знает. А главное - как менять факты в ее "голове"? Как их добавлять? Как сделать оценку "количества знаний" (что бы это не значило)? Как контролировать генерацию, не давая модели возможность искажать информацию и откровенно врать?
А врут ли модели?
Именно неспособность ответить на эти вопросы, привела к тому, что демо модели Galactica, недавней разработки компании META, было свернуто. Еще недавно можно было зайти на сайт, вбить какую-то научную идею, а великий AI выдавал целую статью или блок формул по теме. Сейчас он только хранит набор отобранных примеров, ну и ссылку на оригинальную статью. Жила эта модель открыто почти неделю, но, как это часто бывает (привет от Microsoft), в Твиттере произошел хлопок – и демку закрыли (но веса и код остались доступны). Для справки: это была огромная (120 миллиардов параметров, в GPT-3 175B, то есть это модели одного порядка) языковая модель, натренированная на отфильтрованных статьях и текстах, умеющая работать с LaTeX-формулами, с ДНК-последовательностями, и все это с опорой на научные работы. Причина "провала" очень проста и доступна любому, кто понимает принцип генерации текста LM'ками - модель выдает ссылки на несуществующие статьи, ошибается в фактах (как и практически все языковые модели), и вообще с полной уверенностью заявляет нечто, что человек с экспертизой расценит как несусветный бред (но не сразу, конечно, это еще вчитаться в текст надо).
Несколько примеров работы модели Galactica

Разлетевишийся по новостям тред с другими примерами:
Занятен тот факт, что Galactica вышла (и умерла) незадолго до ChatGPT, хотя примеров лжи и подтасовки фактов у последней куда больше (особенно с фактической информацией) - как минимум потому, что модель завирусилась. По некоторым причинам популярность ChatGPT взлетела просто до небес в кратчайшие сроки -
уже на 5й день количество пользователей превысило миллион!

И несмотря на то, что команда OpenAI проделала хорошую работу по улучшению безопасности модели - заученный ответ "я всего лишь большая языковая модель" на странные вопросы даже стал мемом - нашлись умельцы, которые смогли ее разболтать, заставив нейронку притвориться кем-либо (даже терминалом линукс с собственной файловой системой).
Ответы, подкрепленные источниками и фактами
Если упростить все вышенаписанное, то получится, что
Языковые модели врут. Много и бесконтрольно.
Ещё раз, а почему врут?
Языковые модели иногда могут генерировать ответы, содержащие неверную или вводящую в заблуждение информацию, поскольку они обучаются на больших объемах текстовых данных из Интернета и других источников, которые, в свою очередь, могут содержать ошибки или неточности. Кроме того, языковые модели не могут проверять точность обрабатываемой ими информации и не способны рассуждать или критически мыслить, как это делают люди. Поэтому нужно проявлять осторожность, полагаясь на информацию, сгенерированную LMками, и проверять точность любой получаемой информации.
Важно отметить, что в процессе обучения моделей никак не оптимизируется правильность информации. Можно сказать, что оптимизационная задача, которая решается в ходе обучения, не пересекается с задачей оценки точности генерируемых фактов.
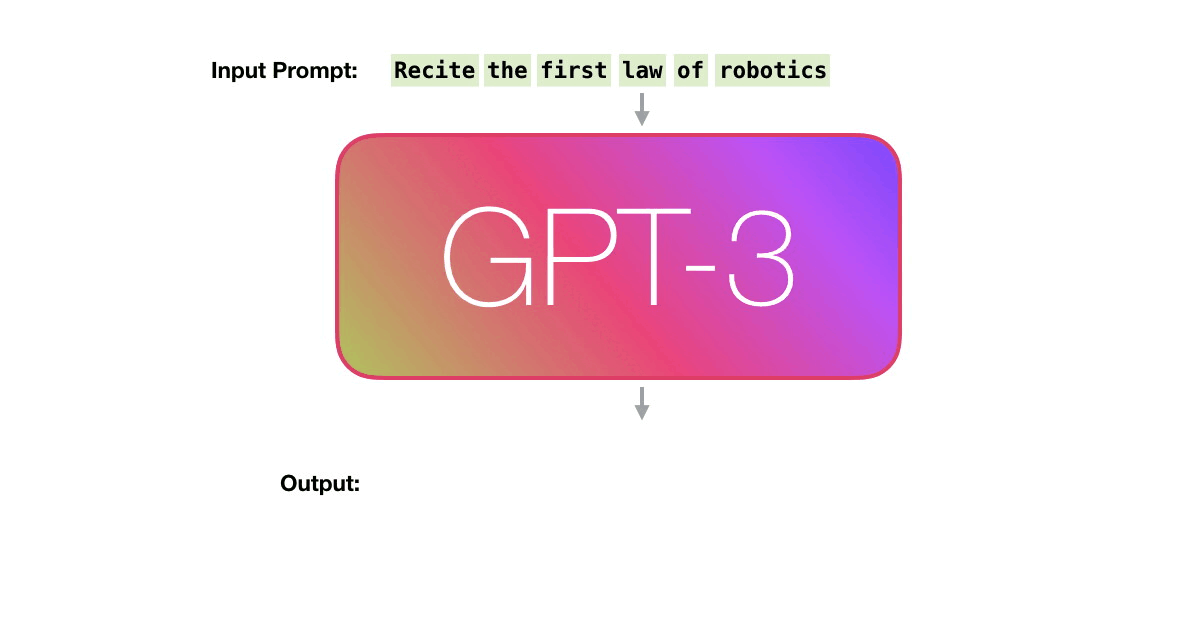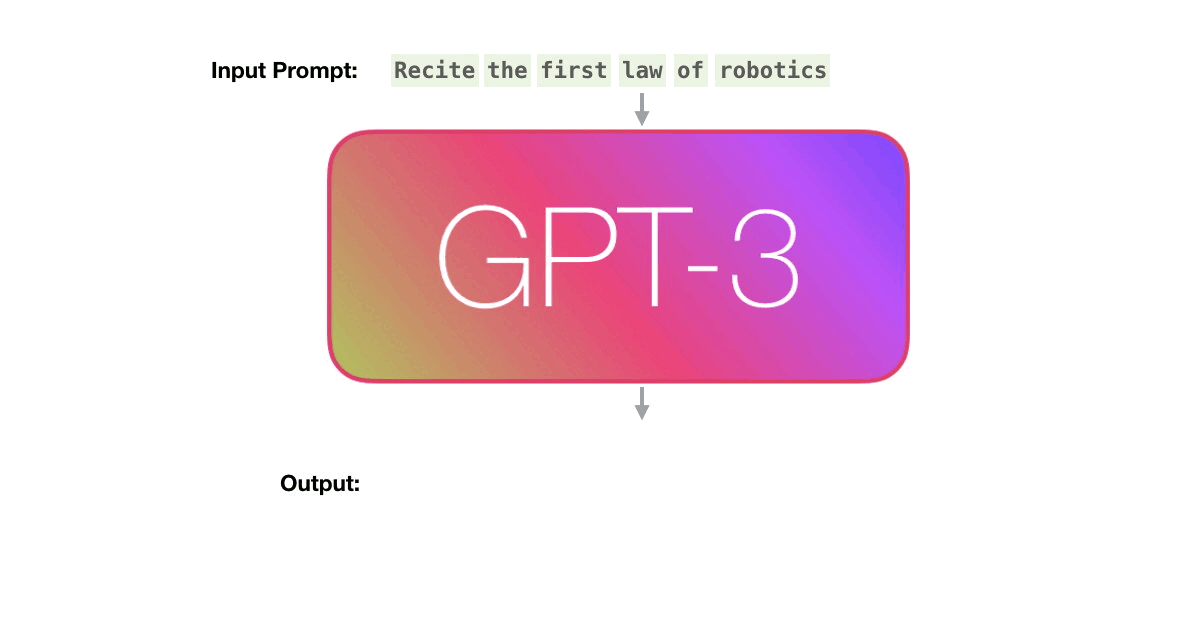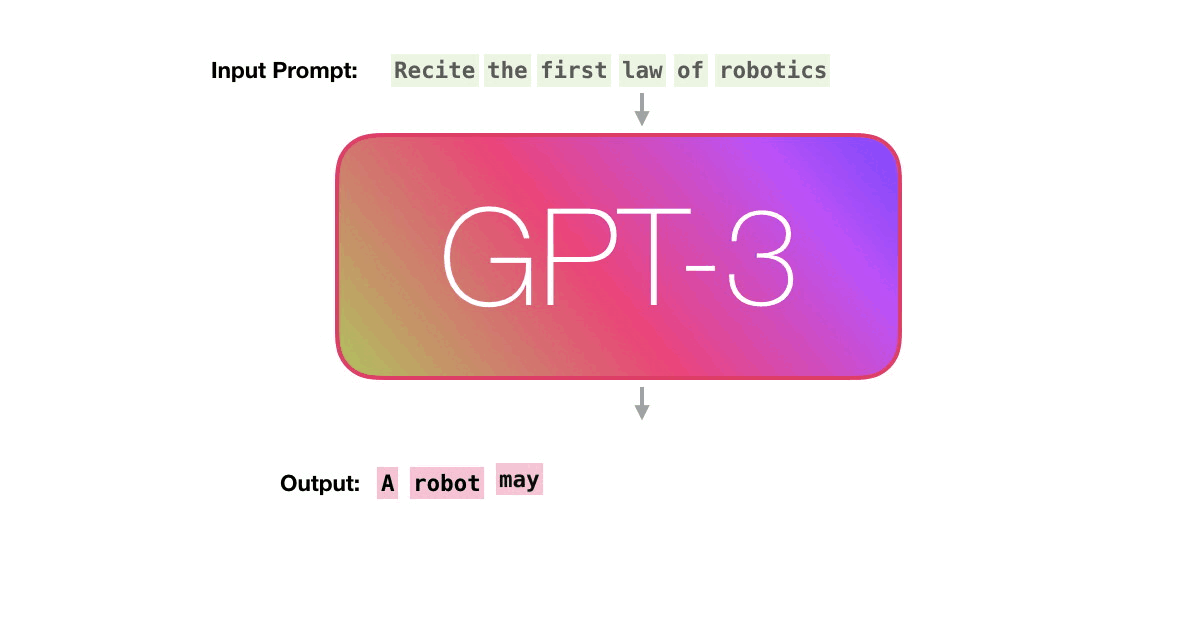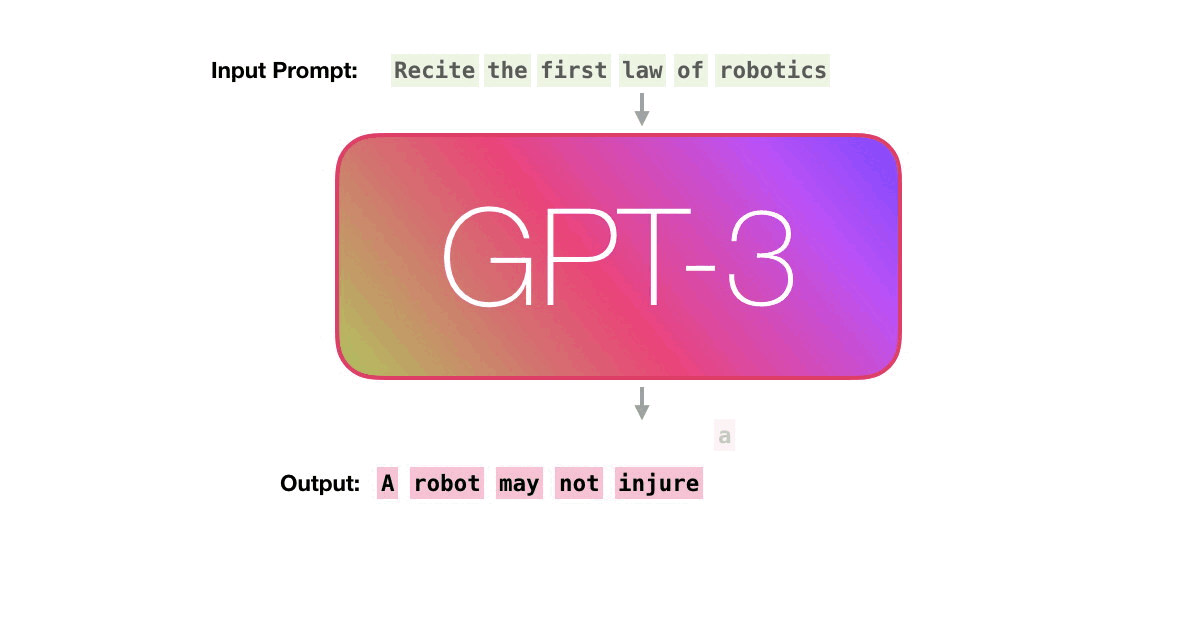
Еще одна причина - это принцип, по которому происходит предсказание. Мы уже обсудили, что такое токен, и что для модели заранее создается словарь токенов, который используется для подачи входного текста. На этапе предсказания (и это же происходит во время обучения) модель выдает вероятности появления каждого токена из словаря в заданном контексте.

Выше на изображении вы можете видеть пример генерации моделью, словарь которой состоит из 5 токенов. В качестве первого слова в предложении LM предсказывает 93% вероятности на появление токена "I", так как с него - среди всех остальных - логичнее всего начать предложение. Далее, как только это слово было выбрано, то есть подано в модель, предсказания меняются (потому что меняется контекст - у нас появилось слово "I"). И так итеративно языковая модель дописывает предложение "I am a student".
Но в вышеописанной логике мы всегда выбираем слово с наибольшей вероятностью. Однако существуют несколько стратегий семплинга (выбора) продолжения. Можно всегда брать слово с наибольшей вероятностью - это называется greedy decoding, то, что изображено выше. А можно производить выбор согласно вероятностям, выданным моделью. Но тогда легко представить ситуацию, что несколько разных токенов получили высокие вероятности - и по сути выбор между ними происходит случайно, по результату броска монетки. И если модель ошибется в одном важном токене - в имени, дате, ссылке или названии - то в последующей генерации она не имеет способа исправить написанное. Поэтому ничего не остается, кроме как дописывать бредовые ложные факты. Еще хуже, если во время выбора токена пропорционально вероятностям мы выбрали редкий токен с низкой вероятностью. Подобное происходит редко (в среднем с той частотой, что и предсказана моделью). Такое слово почти наверняка плохо смотрится в тексте, но что поделать - зато описанный принцип семплинга позволяет генерировать более разношерстные текста. Более детальный гайд про методы генерации, их плюсы и минусы (и еще один).
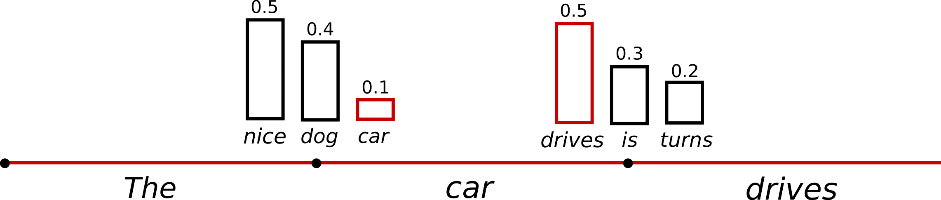
На картинке выше первым словом, подающимся в модель, был токен "The". Для него слово "nice" по каким-то причинам получило оценку 50%, а "car" - лишь 10%. Но если мы выберем слово "car", то логично изменить вероятности последующих слов. И эти вероятности меняются после каждого дописанного токена.

Если подводить итог этой части, то можно сказать просто: у модели есть выбор сгенерировать "19..." или "18..." в ответ на вопрос про даты. И эти выборы примерно равновероятны, +-10%. Дело случая - выбрать неправильное начало года, и всё. Одна ошибка - и ты ошибся.
Настолько много, что META решает отключить свою модель, а люди в Twitter высказывают недовольство подлогом фактов и нерелевантными ссылками. Мы не замечаем несовершества моделей в режиме болталки, но это критично важно для поисковых систем (напомню, что мы рассматриваем языковые модели в контексте их внедрения в Bing/Google/другие поисковые движки). Как мы уже обсудили, есть два типа данных - факты и языковая информация. В контексте поиска логично разделить их, и научить модель работать с чем-то вроде Базы Данных Фактов. Я вижу к этому два принципиально разных подхода:
- Создать отдельное хранилище, с которым модель умеет работать каким-либо образом. Хранилище поддерживает быстрое точечное изменение фактов, их добавление;
- Научить модель пользоваться интерфейсами реального мира, подобно человеку. Это может быть браузер, поисковое API, исполнение скриптов, etc.
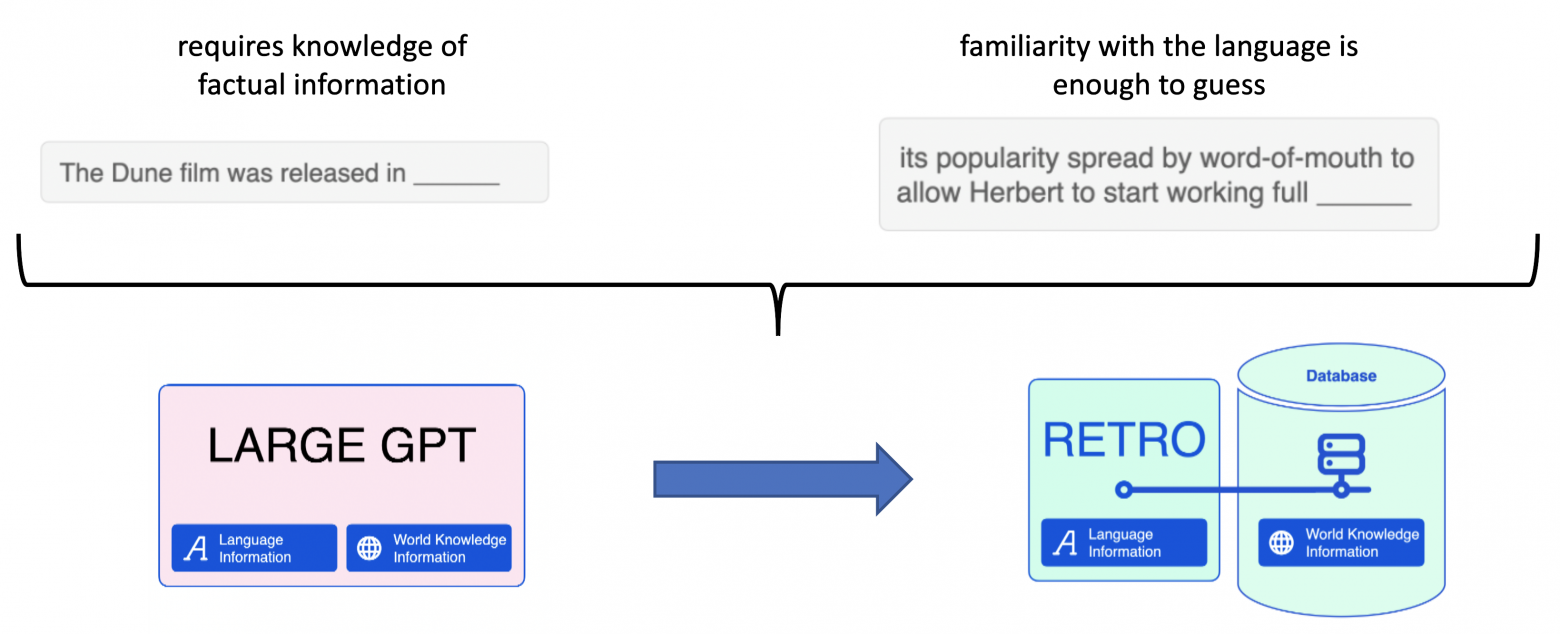
Дальше в статье сфокусируемся на втором подходе. Отмечу, что первый зародился примерно в 2019м году с выходом статьи kNN-LM, и получил активное развитие от команды DeepMind в лице архитектуры RETRO. Про обе этих статьи у меня есть детальные видео-лекции с разбором: part 1, part 2. Про этот подход далее говорить не будем.
Идея предоставить модели доступ в Сеть давно будоражит умы человечества - третий "Терминатор" со Скайнетом вышел 20 лет назад. Главное, что такой подход будет мимикрировать под процесс, который выполняет человек при поиске информации. В идеале для каждого тезиса или вывода, который пишет модель в своем ответе, можно найти и указать референс, источник, в котором модель "подсмотрела" его. Конечно, за скобками остается вопрос надежности источников, тем более в современном то интернете, но сама идея научить нейросеть сёрфить Веб кажется интересной. На новом примере попробуем посмотреть, как это может выглядеть:
Пример ответа на вопрос, какая река из двух длиннее

Обратите внимание, что по ходу работы запросы меняются, и поисковая выдача обновляется.
Вопрос: Which river is longer, the Nile or the Yangtze?
Ответ: The Nile is longer than the Yangtze River.[1][2][3] The Nile runs 6,650 kilometers (4,130 miles) between Lake Victoria and the Mediterranean Sea.[2] The Yangtze River runs 6,300 kilometers (3,915 miles) from its source in the Tanggula Mountains in Qinghai to the East China Sea.[3]
References:
- World's Longest Rivers | Amazon, Nile & Mississippi Rivers | Live Science (www.livescience.com)
- Nile - Wikipedia (en.wikipedia.org)
- Yangtze River Length - 6,300 Kilometers (3,915 Miles) (www.travelchinaguide.com)
- How Long is the Yangtze River? Yangtze River's Length (www.chinatraveldiscovery.com)
Не буду нагонять интригу - демонстрация поиска ответа на вопрос выше выполнена WebGPT, а не человеком. Команда OpenAI разработала подход, который сможет решать задачу long-form question-answering (LFQA), в которой текст длиной порядка одного-двух параграфов генерируется в ответ на открытый вопрос.
Что за LFQA?
Открытые вопросы, или open-ended questions - это вопросы, на которые нельзя ответить «да» или «нет» или статичным предзаготовленным ответом. Открытые вопросы формулируются как утверждение, требующее более продолжительного ответа. Эти вопросы поощряют размышления, дискуссии и выражение мнений и идей. Обычно они начинаются с вспомогательных слов "what", "how", "why" или "describe".
Long-form question-answering (LFQA) включает в себя создание подробного ответа на открытый вопрос.
Больше примеров работы модели можно найти по этой ссылке - сайт предоставляет удобный UI для демонстрации процесса поиска ответа.

Но как именно научить языковую модель выполнять поиск ответов на вопрос? Как мы выяснили выше - они всего лишь продолжают написанное, генерируя по токену за раз. Во время процедуры предобучения такие модели видят миллионы текстов, и на основе них учатся определять вероятности появления того или иного слова в контексте. Если же модели вместо обычного человеческого языка показывать, скажем, код на разных языках программирования - для нее задача не изменится. Это все еще предсказание следующего токена - названия переменной, метода, атрибута или класса. На этом принципе основана другая GPT-like модель Codex. Обучение новому языку или новым типам задач (перевод, сокращение текста - суммаризация, выявление логических связей) - всё это достижимо при дообучении модели, если подобранны правильные данные и они "скармливаются" модели в понятном формате (с изображениями такая модель работать не будет - просто не ясно, как их перевести в текст).
Об авторе
Статья подготовлена и написана Котенковым Игорем (@stalkermustang).