Channel Attention
DeepSchoolАвторы: Ксения Рябинова, Марк Страхов
Редакторы: Александр Гончаренко, Тимур Фатыхов
Давайте теперь поближе рассмотрим типы механизмов внимания.
При исследовании сверточных нейросетей было замечено, что каждое ядро в свертке ищет определенный паттерн во входной карте признаков. То есть в каждом канале выходного тензора закодирована информация о наличии определенного паттерна. Поканальный механизм внимания учится оценивать важность каждого канала, ведя себя как своеобразный селектор объектов, - поэтому и говорят, что поканальный механизм внимания отвечает на вопрос “На что обращать внимание?” Схематическое отображение этого процесса представлено на рисунке 3.
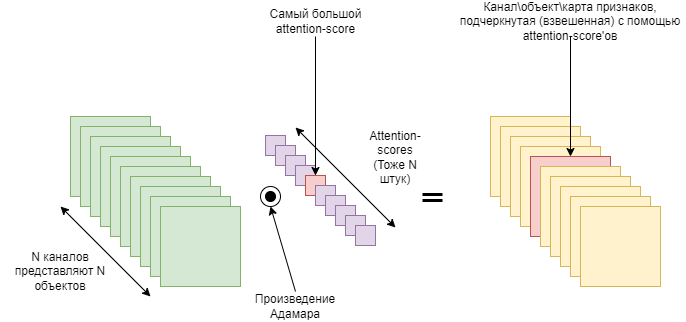
В примере на рисунке 3, самый большой attention-score подчеркнет (обратит внимание на) самый важный канал, а оставшиеся маленькие attention-score’ы ослабят сигналы из менее важных каналов. Остается вопрос, а как нам получить attention-score’ы для умного взвешивания? Одна из первых работ на эту тему — Squeeze-and-Excitation Networks или SENet. Ее мы и рассмотрим далее.
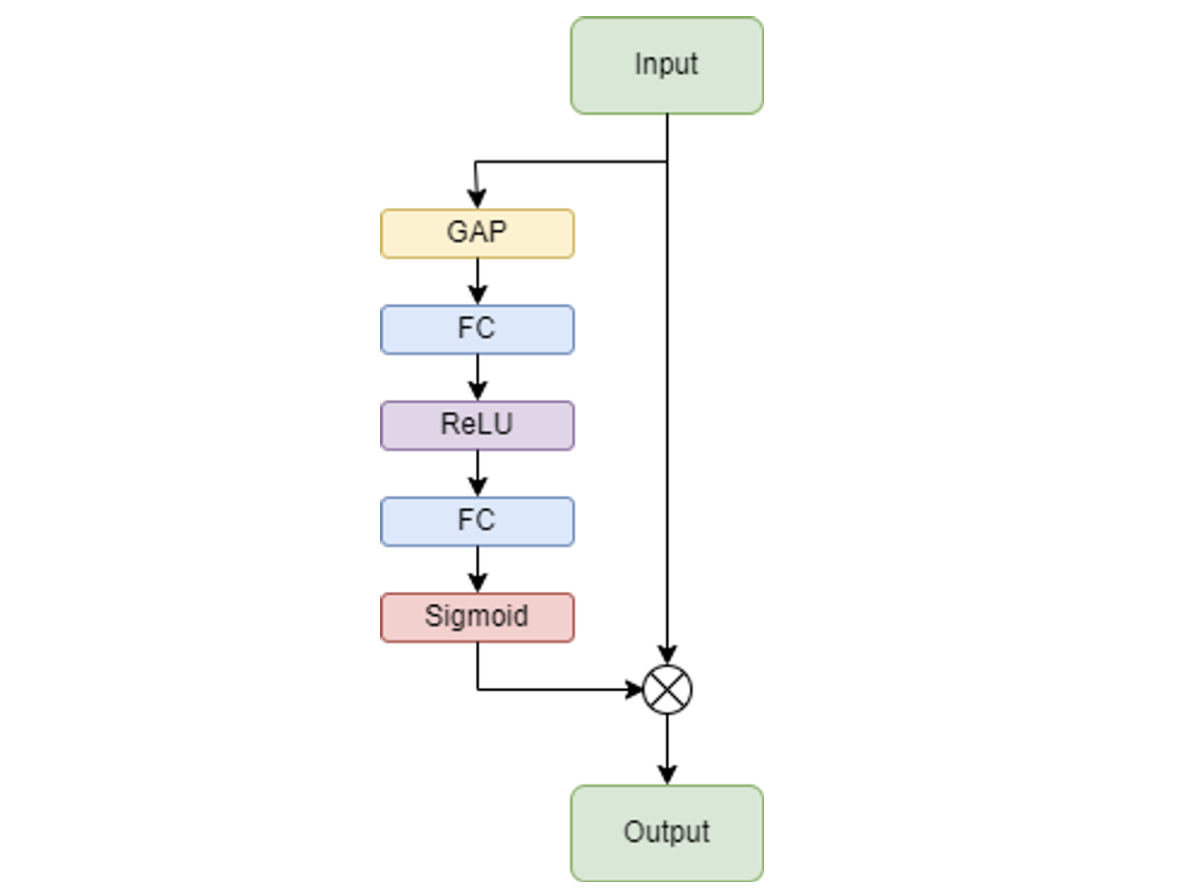
Основной составляющей SENet является Squeeze-and-excitation (SE)- блок, который агрегирует информацию из каждого канала и оценивает зависимости между ними.
SE-блок делится на два модуля: squeeze и excitation. Squeeze-модуль агрегирует информацию с помощью global-average-pooling слоя, который “сжимает” каждую карту признаков в одно число, усредняя пиксели. То есть если на входе в Squeeze-модуль было C каналов, то на выходе будет C средних. Excitation-модуль с помощью FC-слоев с ReLU и сигмоидой на конце отображает эти C средних в attention-score’ы. Затем, каждый канал во входном тензоре взвешивается поэлементным произведением (произведением Адамара) между входным тензором и сформированными attention-score’ами.
Схематичное изображение блока представлено на рисунке 4.
В виде формул это выглядит примерно следующим образом:
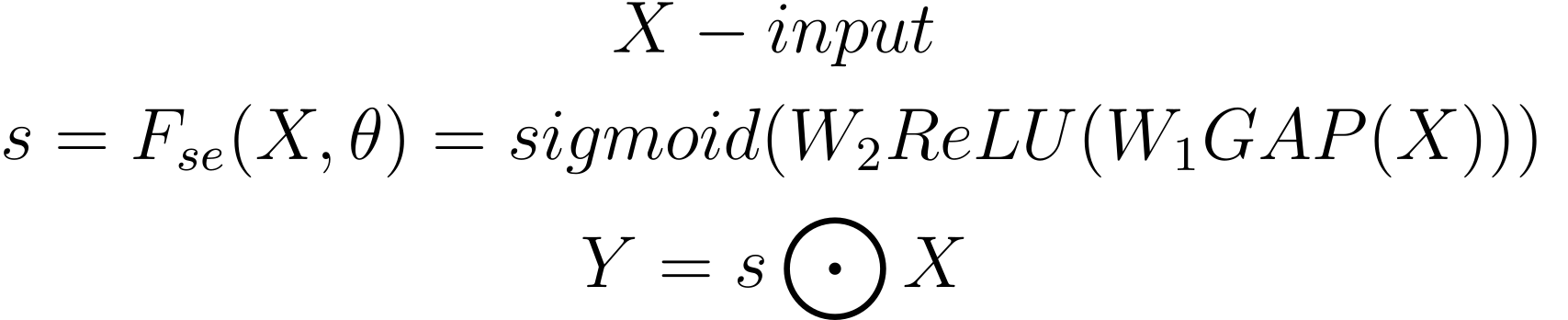
Переводя это на нашу общую формулу, можно получить следующее:
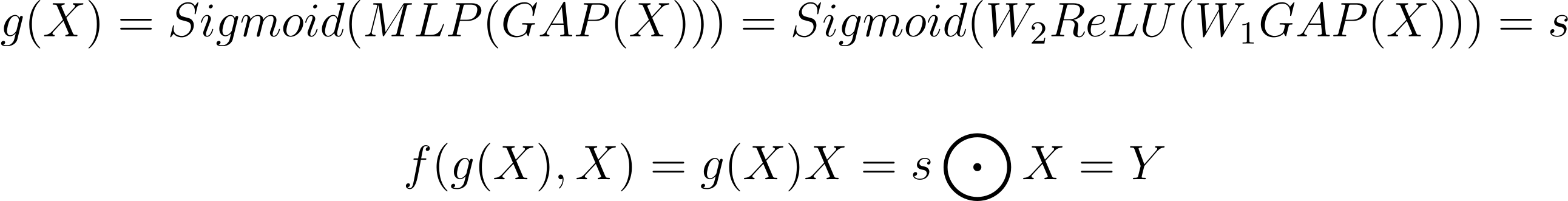
Верхнеуровнево, SE-блок играет роль выделения важных каналов, подавляя при этом шумные ненужные каналы. Однако у блоков SE есть недостатки. В squeeze-модуле используется global-average-pooling слой, который является слишком простым для сбора сложной глобальной информации. А в excitation-модуле FC-слои увеличивают вычислительную сложность модели. В более поздних работах предпринимаются попытки улучшить squeeze-модуль (например, GSoP-Net), или уменьшить сложность модели за счет улучшения excitation-модуля (например, ECANet) или улучшить их одновременно (например, SRM).
В коде SE-block может быть реализован следующим образом:
import torch
from torch import nn
from typeguard import typechecked
from torchtyping import TensorType, patch_typeguard
patch_typeguard()
FeatureMap = TensorType["batch", "channels", "height", "width", float]
class SEBlock(nn.Module):
"""Implements paper's SEBlock."""
@typechecked
def __init__(
self,
n_features: int,
scale_factor: int | float,
) -> None:
"""
Parameters:
in_features: The number of input features;
scale_factor: Scale factor for the number of
intermediate features in excitation module.
"""
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
num_intermediate_features = int(in_features // scale_factor)
self.excitation = nn.Sequential(
nn.Linear(in_features, num_intermediate_features, bias=False),
nn.ReLU(inplace=True),
nn.Linear(num_intermediate_features, in_features, bias=False),
nn.Sigmoid(),
)
@typechecked
def forward(self, tensor: FeatureMap) -> FeatureMap:
"""
Perform forward pass of SEBlock.
Parameters:
tensor: Input features.
Returns:
Scaled features.
"""
batch_size, channels, *_ = tensor.size()
# SE-modules branch.
branch_input = self.squeeze(tensor).view(batch_size, channels)
attention_scores = self.excitation(branch_input).view(
batch_size,
channels,
1,
1,
)
# Scale input feature map with attention scores.
return attention_scores * tensor
F = torch.randn(16, 128, 7, 7)
se = SEBlock(in_features=128, scale_factor=4)
output = se(F)
assert output.shape == F.shape
SENet модели уже реализованы в timm, так что вы можете просто взять их оттуда:
import timm
# List all avaliable SE-Resnets.
timm.list_models("*ser*")
# Your awesome SE-ResNet-18.
seresnet = timm.create_model("seresnet18")