Читаем почту mail.ru из python при помощи imap
Автор: Story-tellerПодробно разбираем работу библиотек imaplib и email, открываем ящик и читаем письма (получаем из них всё что есть) на примере mail.ru (хотя в целом, должно работать везде).
Рабочие задачи заставили обратиться к классике - электронной почте, материала довольно много в сети, но подробного развернутого изложения не хватило, делюсь результатами изысканий, кто не сталкивался ещё с этой задачей, надеюсь, будет полезно.
Приступаем:
Нам понадобятся библиотеки:
import imaplib import email from email.header import decode_header import base64 from bs4 import BeautifulSoup import re
Перед началом, из своего аккаунта на mail.ru нужно создать пароль для доступа к ящику. Для этого нужно зайти в настройки выбрать «Все настройки безопасности» и в «Способах входа» выбрать «Пароли для внешних приложений», создаёте пароль.
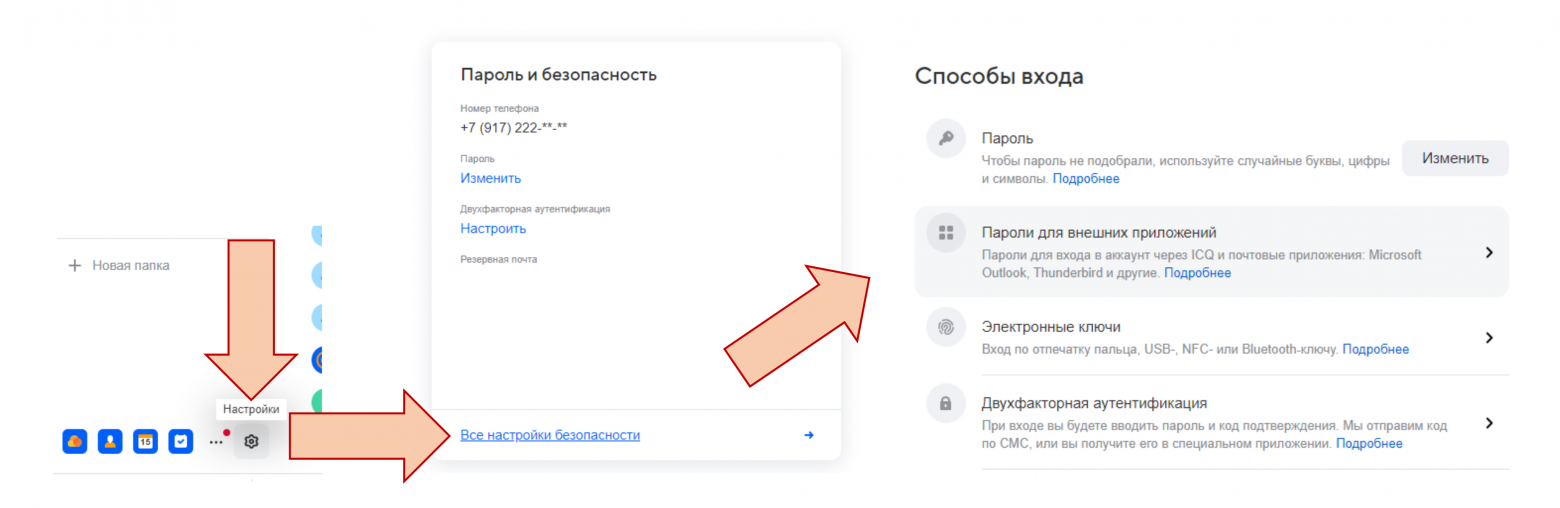
Предварительная подготовка окончена, начинаем писать.
Соединение и аутентификация:
Imap сервер мэйл ру расположен по адресу imap.mail.ru. Логин будет адрес вашего ящика, пароль, мы только что создали.
mail_pass = "пароль от ящика для внешних приложений" username = "адрес_ящика_на@mail.ru" imap_server = "imap.mail.ru" imap = imaplib.IMAP4_SSL(imap_server) imap.login(username, mail_pass)
Если всё прошло хорошо выйдет сообщение: [b'Authentication successful']
Мы зашли в почтовый ящик. Чтобы добраться до писем нужно зайти в папку с ними, по умолчанию входящие это папка INBOX
Посмотреть список всех папок можно командой imap.list()
Получение писем
Чтобы добраться до письма нужно буквально открыть папку и в неё зайти, выполняется так:
imap.select("INBOX")
Возвращает примерно такой кортеж ('OK', [b'19']), первое, это статус операции, второе - количество писем в папке.
Теперь нужно узнать номер письма, а их как минимум два – порядковый номер в папке и UID, который тоже привязан к порядку номеров в папке, но уже не изменяется (ещё есть Message-ID).
Метод search библиотеки imaplib возвращает порядковый номер писем в ящике от первого до последнего.
Письма расположены в ящике по порядку номеров. Если выполнить поиск без каких-либо параметров, получим список номеров писем.
imap.search(None, 'ALL')
>>('OK', [b'1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19'])
Можно убедиться, что писем действительно 19.
Поиск можно осуществлять и более предметно: аргумент "UNSEEN" вернёт, все номера непросмотренных писем:
imap.search(None, "UNSEEN")
В ответ получим порядковые номера непрочитанных писем примерно такой: ('OK', [b'12 16 19']) первый аргумент - это статус операции, далее идёт список битов с номерами писем.
Стоит иметь ввиду, что, если удалить какое-то письмо, то все номера сдвинутся. Т.е. для задачи чтения новых писем этот момент не принципиальный, а вот если нужно будет возвращаться к сообщениям, можно получить их UID, неизменяемый номер. Для этого нужно использовать метод IMAP4.uid(command, arg[, ...])
imap.uid('search', "UNSEEN", "ALL")
Для тех же самых писем мы получим уже другие номера: ('OK', [b'14 24 28']), т.е. порядковый номер письма 12, а uid - 14, 16 - 24 и 19 - 28. С uid уже можно осуществлять более сложные операции - хранить, обращаться, они будет именно за теми письмами в которых вы их получите.
Получаем письмо и извлекаем часть информации о нём
Зная номер письма теперь его можно наконец-то получить.
res, msg = imap.fetch(b'19', '(RFC822)') #Для метода search по порядковому номеру письма
res, msg = imap.uid('fetch', b'28', '(RFC822)') #Для метода uid
Номер надо передавать строчкой str(num) или байтами, инты, не пройдут.
После этой операции в почтовом ящике письмо будет отмечено как прочитанное.
В ответ получим кортеж байтов, в первом будет содержаться порядковый номер, стандарт и ещё какое-то число.
Во втором слоте кортежа, будет наш будущий объект email. Извлекаем письмо при помощи метода message_from_bytes библиотеки email :
msg = email.message_from_bytes(msg[0][1])
Тип объекта msg будет email.message.Message. Непосредственно из него, не заглядывая внутрь можно извлечь почти всё кроме текста письма и вложений (текст иногда тоже можно извлечь).
letter_date = email.utils.parsedate_tz(msg["Date"]) # дата получения, приходит в виде строки, дальше надо её парсить в формат datetime letter_id = msg["Message-ID"] #айди письма letter_from = msg["Return-path"] # e-mail отправителя print(type(letter_date), type(letter_id), letter_id, type(letter_from)) <class 'tuple'> <class 'str'> <1662997113.166751447@f221.i.mail.ru> <class 'str'>
Тут всё просто.
Получение From и Subject, первые сложности
From и Subject запрашиваются также msg["From"], сложности с ответом. Если они полностью написаны латиницей, то извлекаются они также как и предыдущие. Но есть ещё вариант если письмо пришло без темы или поля "От" или "Тема" написаны кириллицей.
msg["Subject"] # тема письма написана кириллицей и закодирована в base64 '=?UTF-8?B?RndkOiDQn9GA0LjQs9C70LDRiNC10L3QuNC1INCyINC90L7QstGL0Lkg0KI=?=\r\n =?UTF-8?B?0LXRhdC90L7Qv9Cw0YDQuiDQsiDRgdGE0LXRgNC1INCy0YvRgdC+0LrQuNGF?=\r\n =?UTF-8?B?INGC0LXRhdC90L7Qu9C+0LPQuNC5IMKr0JjQoi3Qv9Cw0YDQusK7INC40Lw=?=\r\n =?UTF-8?B?0LXQvdC4INCRLtCg0LDQvNC10LXQstCwINC4INCc0LXQttC00YPQvdCw0YA=?=\r\n =?UTF-8?B?0L7QtNC90YvQuSBTdGFydHVwIEh1Yg==?='
Это кодировка MIME + Base64, можно расшифровать вручную, нужный текст находится между символов =? и ?= и дальше base64.b64decode().decode().Или можно воспользоваться методом decode_header, который импортируем из email.header:
decode_header(msg["Subject"]) [(b'Fwd: \xd0\x9f\xd1\x80\xd0\xb8\xd0\xb3\xd0\xbb\xd0\xb0\xd1\x88\xd0\xb5\xd0\xbd\xd0\xb8\xd0\xb5 \xd0\xb2 \xd0\xbd\xd0\xbe\xd0\xb2\xd1\x8b\xd0\xb9 \xd0\xa2\xd0\xb5\xd1\x85\xd0\xbd\xd0\xbe\xd0\xbf\xd0\xb0\xd1\x80\xd0\xba \xd0\xb2 \xd1\x81\xd1\x84\xd0\xb5\xd1\x80\xd0\xb5 \xd0\xb2\xd1\x8b\xd1\x81\xd0\xbe\xd0\xba\xd0\xb8\xd1\x85 \xd1\x82\xd0\xb5\xd1\x85\xd0\xbd\xd0\xbe\xd0\xbb\xd0\xbe\xd0\xb3\xd0\xb8\xd0\xb9 \xc2\xab\xd0\x98\xd0\xa2-\xd0\xbf\xd0\xb0\xd1\x80\xd0\xba\xc2\xbb \xd0\xb8\xd0\xbc\xd0\xb5\xd0\xbd\xd0\xb8 \xd0\x91.\xd0\xa0\xd0\xb0\xd0\xbc\xd0\xb5\xd0\xb5\xd0\xb2\xd0\xb0 \xd0\xb8 \xd0\x9c\xd0\xb5\xd0\xb6\xd0\xb4\xd1\x83\xd0\xbd\xd0\xb0\xd1\x80\xd0\xbe\xd0\xb4\xd0\xbd\xd1\x8b\xd0\xb9 Startup Hub', 'utf-8')]
Он также возвращает кортеж значений, нам нужно нулевое, собственно «Тема» письма, она уже декодирована в экранированные последовательности Unicode, осталось перевести символы в читаемый текст:
decode_header(msg["Subject"])[0][0].decode() 'Fwd: Приглашение в новый Технопарк в сфере высоких технологий «ИТ-парк» имени Б.Рамеева и Международный Startup Hub'
Если темы письма нет, msg["Subject"] вернет NoneType.
Всё это можно проделать и несколькими другими способами, например, получить тему письма можно так:
imap.fetch(b'19', "(BODY[HEADER.FIELDS (Subject)])")
Но, как по мне, вариант, который приведен до этого, более понятен.
Всё что можно было получить не погружаясь дальше мы получили, переходим к тексту и вложениям.
Наконец-то текст письма! А, нет ещё придётся повозиться
Чтобы продолжить нам нужно получить из объекта email.message.Message его полезную нагрузку, методом msg.get_payload().
И как нам любезно сообщает документация к библиотеке email результат может быть:
- простым текстовым сообщением,
- двоичным объектом,
- структурированной последовательностью подсообщений, каждое из которых имеет собственный набор заголовков и собственный payload.
Чтобы сразу разобраться с этим вопросом применяется метод .is_multipart(), который собственно и подсказывает, как дальше быть с письмом. Т.е. сразу определить третий вариант, который является самой настоящей матрёшкой.
Пойдём по-порядку. Если мы получили простое текстовое сообщение... Нет, оно конечно-же никакое не простое, а закодированное в base64, но тут вроде всё просто, берем и декодируем и… можем получить, например, HTML-код, который уже почти читается, но тоже его лучше почистить (поэтому и BeautifulSoup в библиотеках).
Двоичный объект переводим в текстовый, и тут делаем тоже что и в первом случае.
is_multipart() == True или структурированная последовательность подсообщений
Если полученный объект состоит из группы других объектов начинаем итерировать. Проход по частям можно сделать простым циклом:
payload=msg.get_payload()
for part in payload:
print(part.get_content_type())
multipart/alternative
application/pdf
Но тут есть подвох, полученные части тоже могут составными, т.е. циклы нужно усложнять. Сильно упрощает этот вопрос метод walk
for part in msg.walk():
print(part.get_content_type())
multipart/alternative
text/plain
text/html
application/pdf
Встречаются письма, в которых некоторые из этих составных частей тоже составные. Приведенный выше код из документации иллюстрирует именно такой случай.
Обычный проход дал результат по двум объектам, которые собственно и вернулись в результате выполнения .get_payload(), а .walk() дает четыре объекта, дело в том, что она распаковывает составные части вложений. Если тоже самое исполнить стандартным способом получиться примерной такой код:
payload=msg.get_payload()
for part in payload:
print(part.get_content_type())
if part.is_multipart():
level=part.get_payload()
for l_part in level:
print(l_part.get_content_type())
Возвращаемся к получению писем. Чтобы разобраться тут нам понадобится RFC2045.
Каждый объект email снабжён заголовками, которые расскажут о богатом внутреннем мире объекта и соответственно подскажут средства его извлечения. Обычно в первой части payload хранится текст письма, а в остальных вложения. Но это не обязательно, может быть тип multipart и без вложений.
Итак, методы:
- get_content_type()
- get_content_maintype()
- get_content_subtype()
Типы делятся на одиночные (discrete-type) и составные (composite-type) к одиночным (это наш пункт назначения) могут относится: "text" / "image" / "audio" / "video" / "application" / extension-token, к составным: "message" / "multipart" / extension-token (RFC 2045), это надо разворачивать.
Нас интересует текст, поэтому проходимся по payload с условием part.get_content_maintype() == 'text'
for part in msg.walk():
if part.get_content_maintype() == 'text' and part.get_content_subtype() == 'plain':
print(base64.b64decode(part.get_payload()).decode())
Подтип бывает нескольких видов, plain и html (других пока не видел). В сообщении может встречаться как один из них, так и оба, поэтому отбираем нужный вариант при помощи условий.
В случае если подтип это html, возвращаемся к bs4, или регам (это после декодирования из base64).
Текст получен, можно переходить к вложениям.
payload.get_content_disposition() == 'attachment'
Вложения ловятся в частях письма также как и текст, по условию get_content_disposition() == 'attachment'.
get_content_type() сообщит нам тип вложения (/ "image" / "audio" / "video" / "application" /) и более конкретную разновидность его, например application/pdf. Также в заголовке содержится и название файла. Если название не латиницей, то добро пожаловать в MIME + Base64.
for part in msg.walk():
print(part.get_content_disposition() == 'attachment')
False
False
False
False
True
Результат для четырёх частей приведенного выше письма. С именами файлов вложений тоже придётся повозиться
for part in msg.walk():
if part.get_content_disposition() == 'attachment':
print(part.get_filename())
print(base64.b64decode('=0L/QtdGC0LDQvdC6LnBkZg==').decode())
print(decode_header(part.get_filename())[0][0].decode())
=?UTF-8?B?0L/QtdGC0LDQvdC6LnBkZg==?=
петанк.pdf
петанк.pdf
Сами файлы вложений тоже тут, лежат зашифрованные никого не трогают.
for part in msg.walk():
if part.get_content_disposition() == 'attachment':
print(part)
Content-Type: application/pdf; name="=?UTF-8?B?0L/QtdGC0LDQvdC6LnBkZg==?="
Content-Disposition: attachment; filename="=?UTF-8?B?0L/QtdGC0LDQvdC6LnBkZg==?="
Content-Transfer-Encoding: base64
Content-ID: <18336a9fbb54fb78aa51>
X-Attachment-Id: 18336a9fbb54fb78aa51
JVBERi0xLjYNJeLjz9MNCjEgMCBvYmoNPDwvTWV0YWRhdGEgMiAwIFIvT0NQcm9wZXJ0aWVzPDwv
RDw8L09OWzkgMCBSXS9PcmRlciAxMCAwIFIvUkJHcm91cHNbXT4+L09DR3NbOSAwIFJdPj4vUGFn
ZXMgMyAwIFIvVHlwZS9DYXRhbG9nPj4NZW5kb2JqDTIgMCBvYmoNPDwvTGVuZ3RoIDMzNTYzL1N1
YnR5cGUvWE1ML1R5cGUvTWV0YWRhdGE+PnN0cmVhbQ0KPD94cGFja2V0IGJlZ2luPSLvu78iIGlk
PSJXNU0wTXBDZWhpSHpyZVN6TlRjemtjOWQiPz4KPHg6eG1wbWV0YSB4bWxuczp4PSJhZG9iZTpu
czptZXRhLyIgeDp4bXB0az0iQWRvYmUgWE1QIENvcmUgNy4yLWMwMDAgNzkuMWI2NWE3OSwgMjAy
...
Но разбор этой части, пожалуй уже совсем другая история.
Вместо заключения
Зачем же это всё нужно, тем более не затронуты многие аспекты и вопросы. Очень просто, всё это можно завернуть в простенький бот и со спокойной душой удалить почтовое приложение с телефона и читать новые письма прямо в мессенджере.
Если кому-то надо, пользуйтесь на здоровье: https://github.com/Sstoryteller2/mail_reader
Если про более практичное применение, например, автоматизация подтверждения прочтения и запуск счётчиков дедлайнов для ответов, и не только и многое что другое, конечно же начинается с получения доступа к ящику.
Здесь же есть пошаговый ноутбук со всеми примерами. Надеюсь будет полезно, сэкономит время на чтение документации и разбор кейсов.
Библиография:
- email.message: Representing an email message
- RFC 2045
- email.header: Internationalized headers
- imaplib — IMAP4 protocol client