Часть 2. Как делать аудит процессов?
Василий Савунов | https://t.me/data_driven_management
Аудит, который я обычно делаю, включает в себя много исследуемых факторов (осторожно, большой список!):
- Какова стратегия компании на ближайший год? Каковы стратегические цели на квартал?
- Как устроена система целеполагания? Как стратегические цели каскадируются на цели конкретных подразделений? Как осуществляется трекинг движения к целям?
- Как устроена система мотивации? На что она "нацеливает" людей? Что им выгодно делать исходя из данной системы мотивации?
- Какие продукты/проекты находятся в зоне ответственности исследуемого периметра? Каковы их показатели успеха?
- Как устроена система подчинения (оргструктура)?
- Какие есть регулярные встречи которые связывают участников исследуемого периметра (планирование, ежедневные синки, QBR и тд)?
- Какие типы работ присутствуют в деятельности?
- Как выглядит основной Value Stream? Какие подразделения и специалистов он затрагивает? Как он “официально” описан в регламентах, и как он реально выглядит с точки зрения разных ролей и специальностей? Каковы его особенности для разных видов работ?
- Как устроена иерархия работ (эпик - стори - таск)? И есть ли вообще такая иерархия? Каковы основные проблемы на разных этапах Value Stream?
- Каковы временные характеристики всего Value Stream, и разных этапов?
- Каковы основные источники блокеров выполнения задач? Ведется ли такая статистика?
- Как устроена система приоритезации входящего потока? Есть ли Upstream - процесс? Если да, то кто в нем участвует и как он организован? Каковы критерии готовности задачи при переходе из Upstream в Downstream?
- Как определяют “сколько можно взять задач в работу”? Есть ли статистика “вместимости”? Что делают если “не влезает”? Что делают если после планирования прилетает срочная задача от генерального?
- Дополнительно можно исследовать как устроен Deployment Pipeline поставки
Все эти факторы позволяют увидеть общую картинку “в объеме”, затрагивая и стратегический и тактические уровни всей системы управления. Так мы можем избежать ловушки локальной оптимизации, и увидеть как работает вся система.
Интерпретация полученных данных - самое сложное дело. Тут, к сожалению, нужен опыт, и насмотренность. Но в процессе исследования, слушая людей, и сопоставляя их слова с данными, обычно начинает вырисовываться общая картинка, и в какой-то момент все проясняется.
Например, CPO большого продукта жалуется на то, что разработка продукта ведется хаотично, и Владельцы продуктов отдельных под-продуктов, лепят кто во что горазд, не обращая внимание на стратегические годовые цели.
Слушаешь это и думаешь - вот же нехорошие Владельцы продукта!
Начинаешь общаться с людьми и выясняется, что, во-первых, никто и не знает о стратегических целях, потому что все что было сделано CPO для информирования о них - это рассылка презентации с просьбой "ознакомиться". Не было никакого обсуждения, никакой возможности задать вопросы, ну и конечно, не было никакого общего планирования дорожной карты достижения этих целей. То есть людям прислали презентацию со словами "ознакомьтесь" , и все.
Во-вторых, каждый Владелец продукта отвечает за свою P&L и свою бизнес-метрику, от которой у него система мотивации прописана. Естественно, что в этой ситуации они будут заботится только о своём участке, и занимаясь развитием своего под-продукта совершенно не интересуясь планами других Владельцев продукта. CPO не предусмотрел никаких мероприятий для координации планов развития разными под-продуктов. Каждый делает как хочет, а CPO пребывает в иллюзии, что все знают о стратегических целях, и подстраиваются под это.
Очевидно, что в данной ситуации как минимум, отсутствует петля обратной связи, которая позволяла бы увязывать планы Владельцев продуктов со стратегическими целями. Да и систему мотивации надо будет тоже перестроить.
Какие данные могут это подтвердить? Например, можно посчитать, какой процент фич в беклоге каждого подпродукта "бьют" в стратегические цели, и растят целевую бизнес-метрику. Можно взять исторические данные, и проанализировать посмотреть какое соотношение задач было там. Скорее всего мы увидим, что этот процент фич, которые работают на стратегическую цель меньше, чем остальных.
Вот так, постепенно, исследуем разные свидетельства от людей, ищем подтверждение этих слов в данных, и если находим соответствие - это можно считать доказанным фактом.
В сложных и запутанных случаях, чтобы лучше увидеть взаимосвязи разных факторов, я использую Casual Loop Diagram. Этот инструмент позволяет увидеть деструктивные самоусиливающиеся циклы, которые приводят к постоянной деградации всей системы. Зная, как устроены эти циклы, можно придумать контрмеры, которые сбалансируют негативные проявления этого цикла, или даже обратят его вспять.
Какие источники информации я обычно использую при проведении аудита:
- Интервью со стейкхолдерами, регулярным менеджментом, рядовыми сотрудниками
Не смотря на то, что данные собранные таким образом, будут носить субъективный характер, и зависеть от точки зрения того, с кем я разговариваю, при правильном использовании, это один из самых ценных источников информации. Обычно, в ходе этого этапа, общаясь с разными людьми я перепроверяю полученную информацию, и вычленяю то общее, о чем говорят все. С другой стороны, расхождения в рассказах разных ролей тоже интересны, так как позволяют увидеть одно и то же с разной стороны и увидеть "гэпы" во взаимопонимании, целях и ожиданиях разных ролей. Очень интересно наблюдать, какие дополнения и изменения вносят в видении Value Stream разные роли.
Интервью позволяют понять “куда надо копать”, и чему надо искать подтверждение в данных:
- Стейкхолдеры укажут на проблемы стратегического характера и расскажут как устроен бизнес и каковы метрики успеха.
- Менеджеры расскажут про то, как они видят рабочий процесс, и что, по их мнению, в нем “сбоит”. Подскажут с кем стоит дополнительно пообщаться для более глубокого погружения. Поведают о системе мотивации и KPI по которым меряют успех.
- Рядовые сотрудники расскажут про невидимые для менеджеров детали, которые могут быть очень важными для общего понимания картины. А собранные вместе рядовые представители разных функций, помогут нарисовать картинку реального течения потока ценности (value stream) - так как он есть, а не так, как он красиво изображён на утвержденных схемах бизнес-процесса. - Изучение документов, регламентов, должностных инструкций, схем
Как правило, это наименее информативная часть аудита. Редко в какой компании регламенты выполняются именно так как написаны, а люди работают по должностной инструкции. Тем не менее, эти документы могут дать точку отсчета для исследования - что ожидается от разных ролей, кто кому формально подчиняется, какие формы отчетности изначально заложены в систему. - Анализ данных таск-трекера
Один из наиболее трудоемких, но интересных для меня этапов исследования.
Делаем выгрузку данных о времени перехода задач по статусам, за 3-6 месяцев и начинаем крутить-вертеть эти данные, выделяя разные кластеры, строя CLD диаграммы, анализируя пропускную способность, и вычленяя наиболее часто повторяющиеся проблемы.
Какие задачи преследует этот этап:
a) Найти подтверждение тем сигналам, которые мы услышали во время интервью. И здесь наиболее сложным является вопрос - какая метрика поможет вам понять, действительно ли имеет место та или иная проблема или нет?
Например, если менеджер жалуется нам на качество, то какая метрика позволит нам понять, действительно ли эта проблема есть, и каков ее масштаб? Возможно, стоит посмотреть на прирост количества багов с production-сервера после релиза, еще лучше, если мы можем связать баги с конкретной user story. в рамках реализации которой этот баг появился. Да и просто изменение соотношения багов и продуктовых задач за определенный период. В общем, подбор таких метрик - само по себе отдельная задача.
b) Выявить и подтвердить на данных “тактико-технические характеристики” рабочего процесса.
Как минимум, будет полезно узнать:
- Вероятный Customer Lead Time (сколько ждет заказчик) и Lead Time (время выполнения задачи) - это даст возможность подтвердить или опровергнуть тезис о том, что “Delivery работает медленно”.
- Каково вероятное время ожидания задачи в очереди (First Touch Time), перед тем как она будет взята в работу Delivery? Это поможет выровнять ожидания заказчиков относительно времени начала работ;
- Каково соотношение времени прохождения задачей этапов Upstream и Downstream? Вполне может оказаться, что процесс подготовки и выбора задач длится дольше, чем процесс реализации;
- Каково соотношение частоты поступления задач в очередь Delivery (Demand) и пропускной способности Delivery (Throughput)? И в дополнение к этой метрике интересно посмотреть на динамику прироста размера очереди на вход в Delivery - если очередь постоянно растет, значит, Demand явно превосходит Throughput. Throughput покажет предел производственных возможностей рабочего процесса - сколько он способен переварить в единицу времени, и когда “пихать” в него больше задач бесполезно.
- Какой этап является “узким местом” в рабочем процессе? Это зачастую, интуитивно многим понятно, но не решается годами. Однако, когда наглядно показываешь стейкхолдерам этот факт на данных, часто у них в голове что-то щелкает, и они, наконец, принимают решение о необходимости расшить это узкое место - за счет оптимизации внутренних процессов, или добавив ресурсов.
Как анализировать данные из таск-трекера?
Конечно можно попробовать воспользоваться теми графиками и инструментами анализа, которые "из коробки" предоставляются в таск-трекере, но по моему опыту, лучше делать выгрузку данных в Excel и "крутить" их самостоятельно.
Так можно найти гораздо больше интересной информации и неожиданных открытий.
Что должно быть в выгрузке в Excel?
Ответ: время перехода задач между статусами.
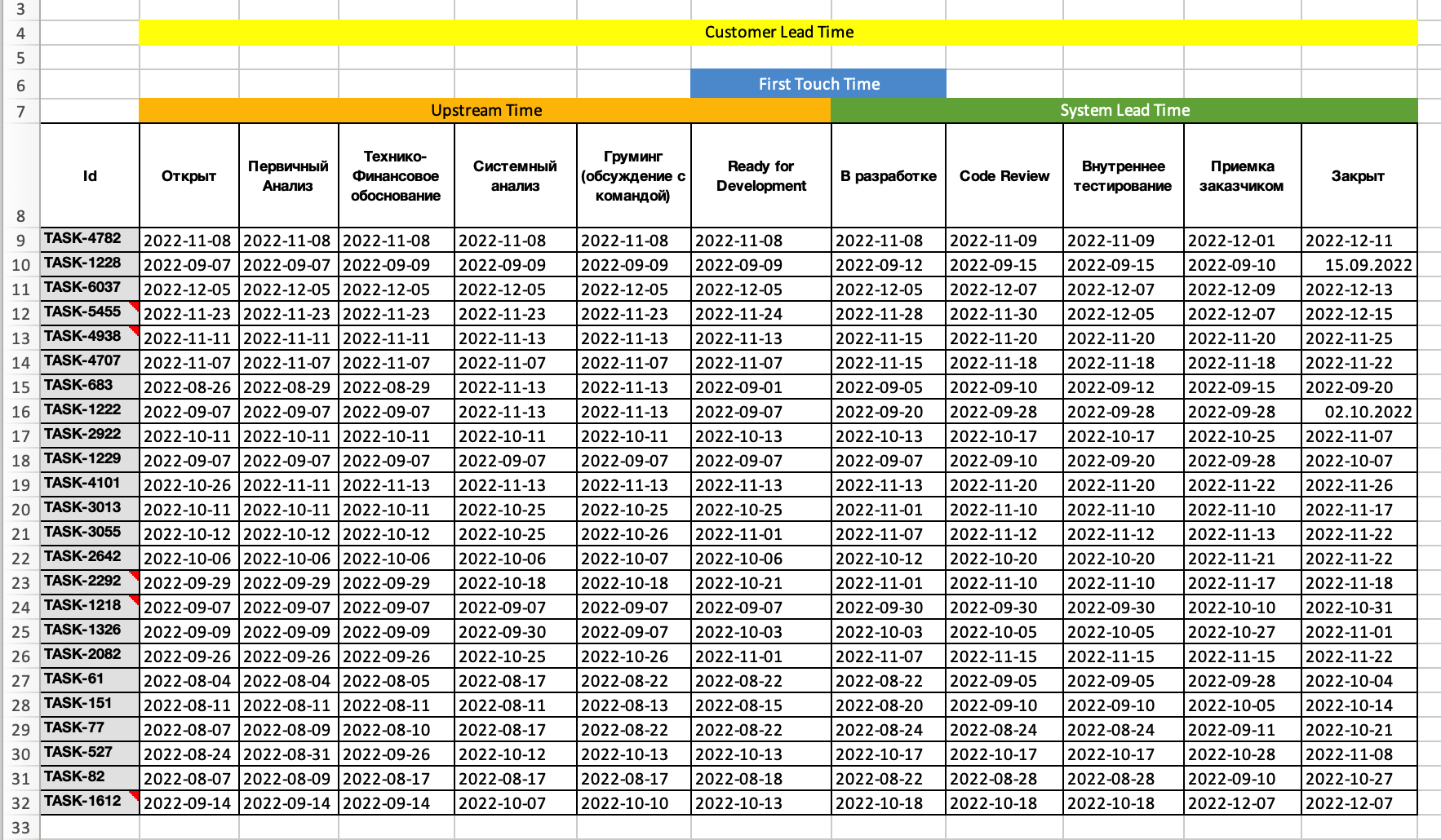
И тут нас часто ждет подводный камень: что делать если задача несколько раз "прыгала" вперед и назад по статусам, или даже перепрыгивала какие-то статусы, не заходя в них? К сожалению, такое бывает нередко.
Обычно в таких случаях я беру время первого попадания в статус "слева" и последнюю дату перехода в статус "справа", чтобы нивелировать влияние "прыжков".
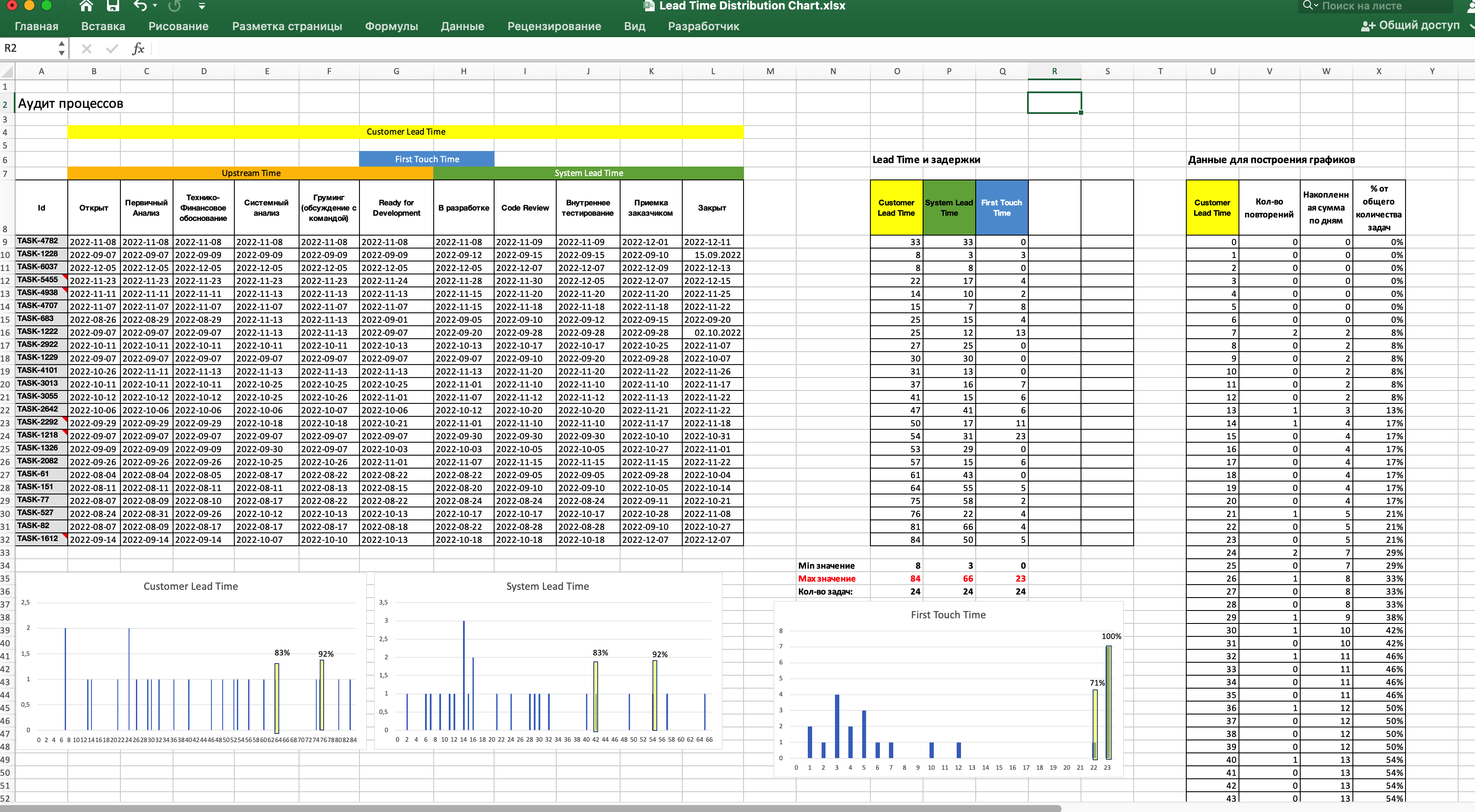
И вот на основе этих данных составляем аналитику, строим Lead Time Distribution Chart по разным частям Value Stream и получаем разные метрики: Customer Lead Time, Upstream Lead Time, First Touch Time, System Lead TIme.
Если рабочкя доска в трекере содержит колонки-накопители задач (буферы), то мы можем посчитать соотношение времени задержек, и времени работы. Увидеть на каком этапе задержки превалируют.
Так же можно посчитать пропускную способность - сколько задач в месяц переходят в колонку "Готово". И сопоставить ее с Demand - количство задач в месяц, которые переходят в колонку "Ready For Development" (или какой-то другой накопитель задач перед поступлением в Delivery).
Дальше можно копаться еще глубже, выявлять дополнительные срезы данных, которые уточняют эту картинку - по типам работ, по классам обслуживания, по исполнителям, по заказчикам, по часто повторяющимся словам в заголовке задачи и тд и тп.
Все это вручную делать довольно затруднительно, поэтому ниже я опишу разные инструменты, которые я использую для анализа данных.
Вот что я использую для анализа данных:
- Excel
Самый простой инструмент для начала анализа. Правда, нужно будет немного помучаться с расчетом Lead Time, так как это требует рутинной copy-paste работы, и аккуратности. По этой ссылке я оставил пример Excel-таблицы, которая позволяет строить CLD-диаграммы на основе данных выгрузки из таск-трекера. Алгоритм расчета не сильно сложный, но подготовка данных для построения Lead Time Distribution Chart - довольно муторный процесс. Особенно тяжко, когда нужно обработать данные по десятку подразделений. Нужно быть аккуратным с диапазонами ячеек при использовании формул, а то результаты будут ошибочными. Построение Lead Time Distribution Chart в Excel у меня занимает в среднем 10-15 минут. Если я еще хочу построить диаграмму распределения Customer Lead Time, First Touch Time, Upstream Lead Time - то на все может уйти до одного часа. Если вам нужно сделать все “по красоте”, чтобы презентовать эти данные заказчикам - то времени может уйти и больше.
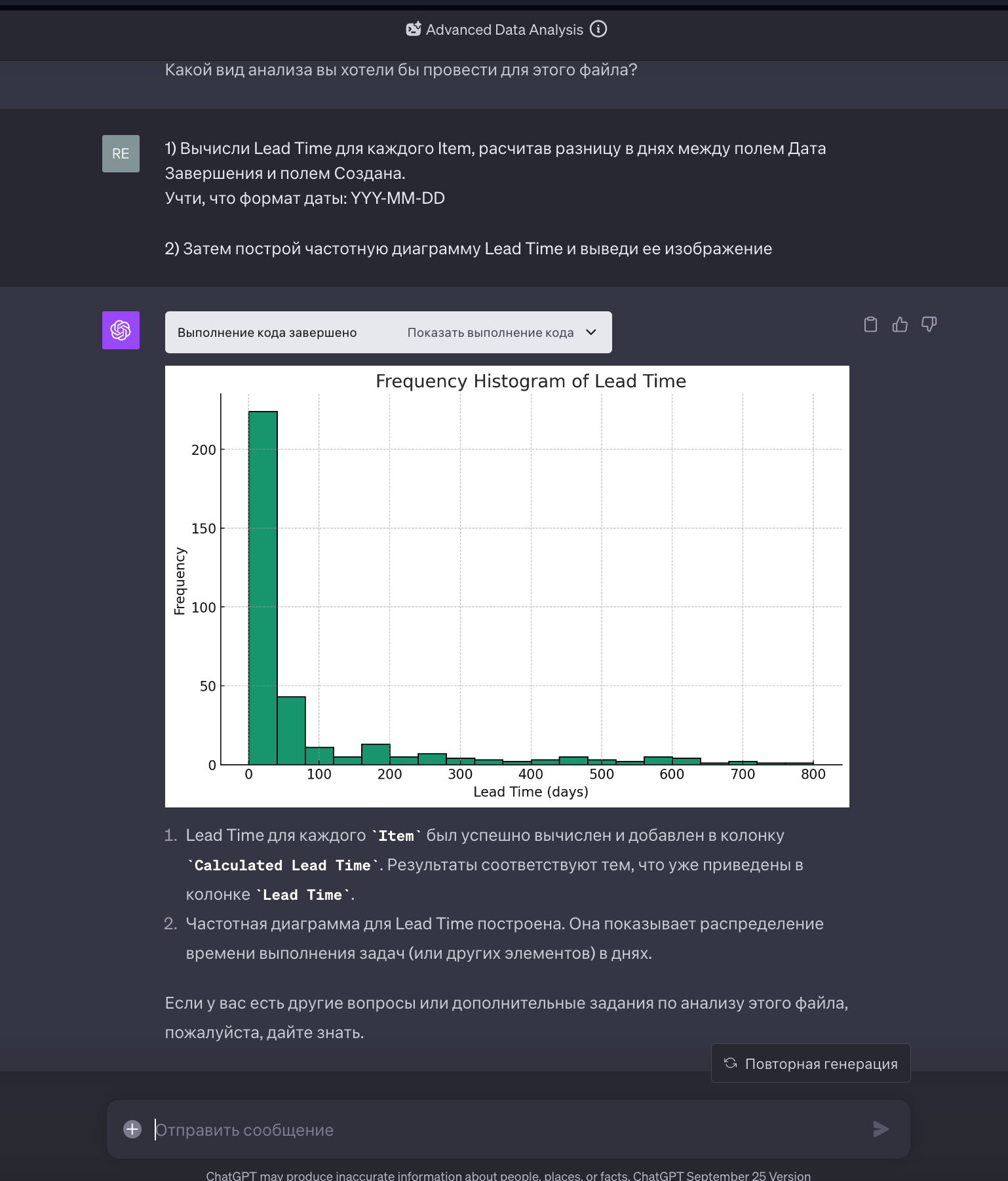
- ChatGPT с плагином Advanced Data Analysis
Плагин позволяет загрузить файл с данными и по запросу пишет python-код с использованием библиотеки pandas для анализа данных. Потом сам его выполняет и выводит готовый результат. Это может сильно сократить время на превращение “сырых” данных в таблицу для построения Lead Time Distribution Chart.
Но тут надо быть осторожными и перепроверять все результаты, которые выдает ChatGPT. Потому что при написании кода, он строго говоря, не думает о том, что он делает, он использует вероятностные модели, которые говорят ему, что при таком запросе от клиента наиболее часто пишут именно такой код, с такими функциями, обработчиками, модулями и тд. На моей памяти было, когда ChatGPT несколько раз неверно строил диаграммы, или путал расчет 80%-й вероятности с расчетом 80% - перцентиля. А это вообще говоря, не одно и то же. ChatGPТ - как умный ребенок. Делает по аналогии, но не всегда верно. И иногда на “голубом глазу” делает ошибки в алгоритме, утверждая, что так и надо. Приходится ловить его за руку, и требовать исправить.
- Orange3 Data Mining
Opensource платформа для анализа данных, у которой “под капотом” python и библиотека pandas. По сути, это инструмент визуального программирования, в которой можно составить цепочку виджетов обработки данных, скормить ему Excel-исходник с данными по времени перехода задач между статусами, и он произведет желаемый анализ. С помощью этого инструмента можно проявить в данных закономерности, которые бывает очень сложно увидеть человеческим глазом, потому что требуется проанализировать много записей и найти в них повторяющиеся паттерны. Так же доступны алгоритмы машинного обучения, которые могут дать возможность еще глубже проанализировать имеющиеся данные.

Итоги второй части:
- Чтобы избежать ловушки локальной оптимизации, следует собирать данные как на стратегическом, так и на тактическом уровне, чтобы понять как устроена вся сложная система, которую мы собрались анализировать
- Основные способы добычи информации, это интервью, документы и анализ данных из таск-трекера
- Инструменты для анализа данных из таск-трекера, это : Excel, ChatGPT с плагином Advanced Data Analysis и Orange3 Data Mining