Бот, который советует фильмы по настроению используя ChatGPT без подключения к API

Это небольшая история появления бота @chtoposmotrbot, который задает пользователю вопросы, на которые можно ответить "да" или "нет" и по ним предлагает подходящие фильмы. База фильмов, отсортированных по 58 критериям была собрана с помощью пары нехитрых манипуляций c ChatGPT. Такой подход позволяет создавать продукты на основе разного рода искусственных интеллектов изначально коммерчески более жизнеспособными, минуя конские расходы за пользование официальным API (в моем случае это $20 единоразово против $10,000 в месяц для расчетных 100 тысяч пользователей). Как всегда, приведенный в материале бот сделан на конструкторе и без умения в программирование, в общем, в лучших традициях формата "сможет каждый".
Пару слов о самой идее
Для моего технического невежества, появление ChatGPT привело как к несколько оторванному от реальности ощущению того, что теперь можно использовать его буквально как "API от всего на свете", так и пониманию, что теперь можно в своих скромных интернет-изобретениях выдавать ценность значительно бОльшую, относительно той, которую я мог бы сам бы соорудить логикой в конструкторе, ну, просто потому, что под капотом моего следующего концепта может таиться уже в сотни раз более мощная начинка. Ну просто бери потребность человека и заряжай ее в ChatGPT и вуаля!
Примерно с такой мыслью я опустился до того, чтобы попросить бездушную машину посоветовать мне кино. Идея заключается в том, что у человека может быть желание посмотреть кино и получить эмоции, но оно не может быть сформулировано, примерно также, как когда хочешь есть, но не знаешь, что, и в таком случае можно выбрать подходящее блюдо отсекая не подходящие по примерно такой древовидной модели. Для фильмов:
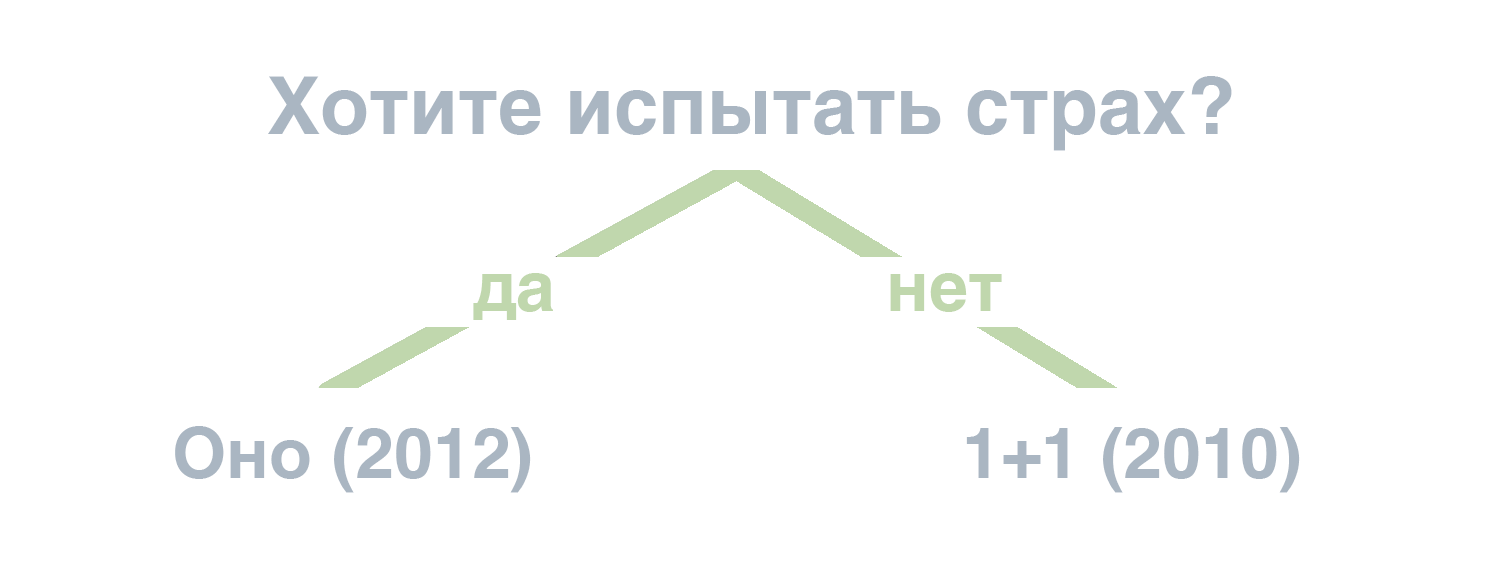
В качестве референса взял игру "акинатор", где компьютер угадывает любого персонажа, которого ему загадает пользователь, вот я и подумал, а что если ChatGPT угадает загаданный мною фильм, только что это за фильм, знать не буду даже я сам. А поскольку уникальность предложения будущего бота должна заключаться в том, что выдаваемая ценность насколько это возможно больше потраченных усилий, то здесь решил ограничить требуемые действия от пользователя выбором между "да" и "нет":

После десятка таких попыток стало понятно, что ChatGPT будет справляться чуть лучше, если ему давать несколько примеров при запросе, тем более, что я плюс/минут понял, какие вопросы мне бы хотелось видеть. Забегая немного вперед, для удобства работы со списком вопросов, я попросил показывать результат сразу в виде массива:
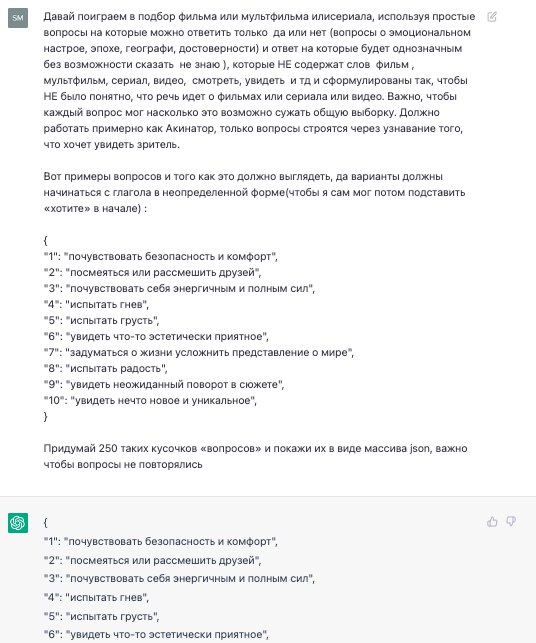
Из полученных вперемешку 250 вопросов я отобрал 58. Теперь, казалось бы, будет достаточно отправлять через API ChatGPT список вопросов с указанием ответа(да/нет) к каждому и в ответ будет прилетать список фильмов, но здесь я столкнулся с тем, что такой подбор для одного пользователя будет стоить около $0,1 — ситуация такова, что чем больше нагружаешь ChatGPT текстом, тем больше будь добр заплатить. На предполагаемые мною 100 тысяч пользователей это будет означать затраты до $10,000 в месяц, что даже при ежедневной публикации рекламных записей по рыночной стоимости около $50 за пост в боте с такого размера аудиторией едва ли покроет 15% расходов сам ChatGPT.
Дорого, обидно и скорее всего неокупаемо. C этой мыслью я походил несколько дней, а потом подумал, а почему бы не попытаться выкачать из ChatGPT сразу готовую базу фильмов и бесплатно работать с ней, плюс это бы решило возможную проблему следующего порядка с количеством запросов в минуту.
В поисках такого решения задал ChatGPT вопрос о том, сможет ли он выдать мне несколько фильмов с указанием 58 критериев по каждому, которые я бы мог сложить в свою собственную базу. Да, сразу же в виде массива:

Здесь на деле оказалось еще и то, что лимиты на количество символов в получаемом от ChatGPT результате не вмещают больше 6 фильмов в рамках одного ответа:

Где-то в соседнем окошке спросил у ChatGPT о том, сколько фильмов должно быть в базе для того, чтобы сортировку прошла хотя бы одна кинолента и получил в ответ число 1,500. Это 250 таких запросов — именно столько будет нужно для хоть какой-то корректной работы будущего бота. Опять же, память у ChatGPT как у рыбки и на каждые 300 фильмов для базы, уникальных удается выудить всего 40-50. Для решения этой задачи я разбил запросы по фильмам на три десятка категорий, в которых названия фильмов начинаются с конкретной буквы и так по порядку: "А", "б", "в", "г"...

И теперь, чтобы получить по 40-50 фильмов для каждой буквы, потребуется сделать в сумме 1500 запросов, учитывая, что на полную обработку каждого запроса уходит порядка 1 минуты, на создание минимальной базы из 1500 фильмов уйдет 25 часов. Звучит намного приятнее, чем $10,000 в месяц, не правда ли?
А главное, что этот процесс можно автоматизировать с помощью любой программы-автокликера(программа для автоматического повторения действий мышкой и клавишами), в моем случае на MacOS это был встроенный "Automator", который я и загрузил повторять это действие по 50 раз вручную заменяя букву в запросе каждый час:
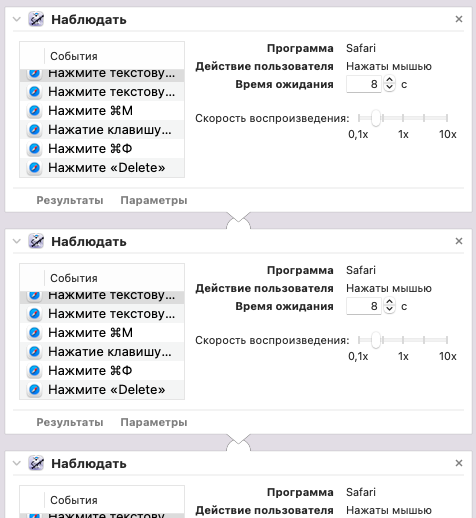
Через пару дней неспешной автоработы и отдыха от ноутбука, занятого своими автоматическими делами, я получил 1500 ответов с примерно 9000 фильмами, а количество значений по критериям составило в сумме около 522,000. И даже не смотря на то, что после фильтрации повторов в базе оказалось на порядок меньше уникальных кинолент, полагаю, что подобный результат вручную лично для меня был бы просто физически недостижим без использования ChatGPT, хотя бы по той причине, что только для просмотра всех этих фильмов потребовалось бы около года, не говоря уже о какой-то классификации.
Как это работает в получившемся боте
Полученный список в виде массива я загнал в бота и теперь в зависимости от каждого ответа пользователя на вопрос, фильмам в этом списке присваиваются баллы: если пользователь хочет смешной фильм, то комедии "Мы миллеры" присваивается +1 балл. Чем больше баллов у фильма, тем выше он в итоговом списке, который увидит пользователь. И хотя, на деле все чуть более замороченней, но если совсем в двух словах, то работает это именно так.
Здесь мне наверное стоило бы извиниться перед читателем за отстутствие подробного описания настройки компонентов в конструкторе, но увы, это момент исключительно технической реализации, уступающий в значимости общему подходу, плюс, в конструкторе есть техподдержка, да и сам ChatGPT помогал мне в работе с массивами, да и вообще, не сильно хотелось бы растягивать статью скриншотами конструктора, что будут интересны едва ли 5% читателей.
А вот как выглядит получившийся бот(t.me/chtoposmotrbot):
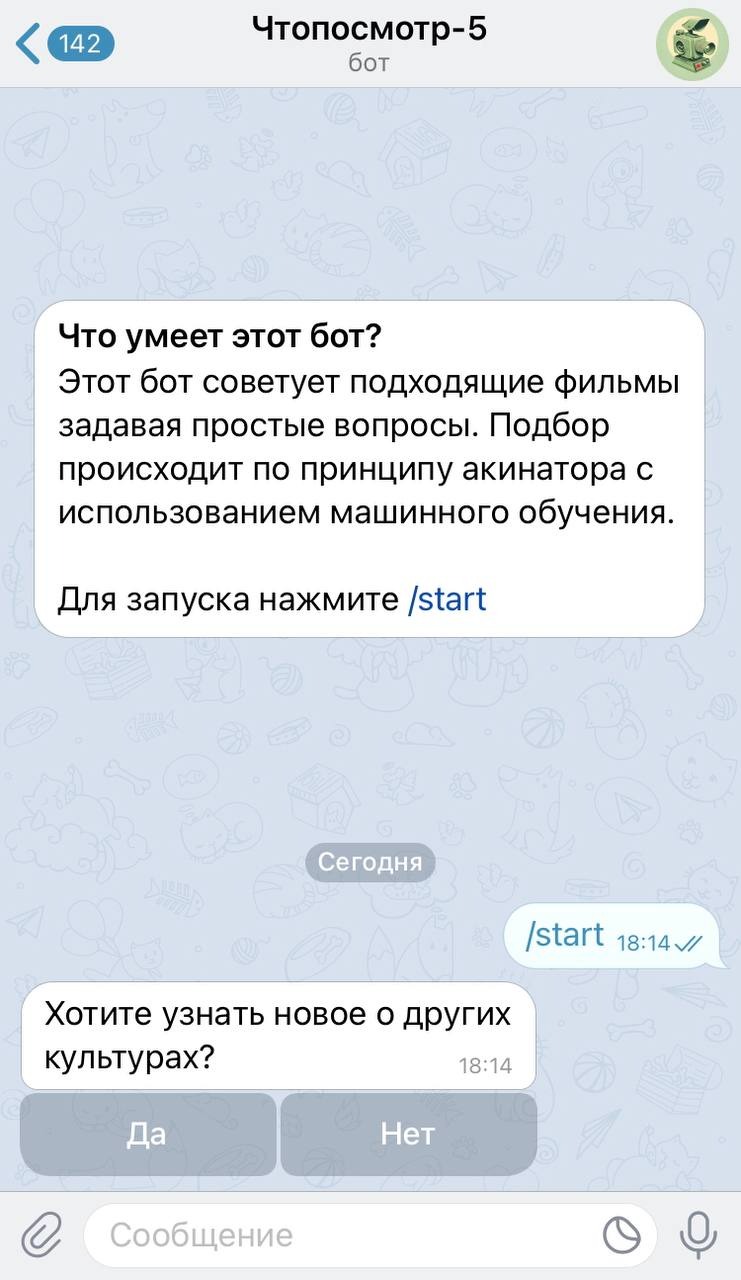
Да, пользователь отвечает не на все 58 вопросов, а на случайные из 7-15 штук(чтобы повторное пользование ботом не раздражало одинаковостью вопросов) и конечный результат для пользователя представляется следующим образом:
Получается, что человек меняет несколько кликов и всего минуту своей жизни на дюжину фильмов, отобранных для него искусственным интеллектом. И даже 10% совпадения с потенциальным желанием пользователя будет достаточно, чтобы ему пришелся по вкусу хотя бы один фильм и полученная ценность превзошла приложенные усилия.
Плюс, указанный процент совпадения с пожеланиями пользователя здесь работает на изначальное понижение ожиданий от результата, на тот случай, что если фильм с заявленной 30% подходимостью окажется на 100% интересен пользователю, то это повысить ценность бота в моменте, когда человек уже досмотрит фильм, ну а в случае не попадания в предпочтения, что поделать... там же было написано, что 30%.
Вывод
Ипользуя ChatGPT подобным образом можно как находить потребности для будущих проектов с ранее не существовавшим уникальным предложением, так и получать массивы отсторированных данных для создания или улучшения продуктов в духе "что поесть?", "чем заняться?", "куда поехать на отдых?" и так далее. Оболочка в виде бота/сайта/приложения будет лишь интерфейсом для выбора, а основную ценность будут составлять вытащенная всеми правдами и не правдами база чего либо, отсортированная по нужным параметрам, на которую вы бы потратили или миллион лет за компом или десяток другой тысяч долларов.
Кстати, картинку для логотипа бота мне любезно нарисовал другой искусственный интеллект за пару минут:


Такие дела.
Другие мои эксперименты как всегда можно посмотреть вот тут: t.me/larkenization