Big data
Capítulo 1. Frente al mar de datos
Página 7 de 16
CAPÍTULO 1
Frente al mar de datos
Introducción
Las últimas décadas han visto un rápido crecimiento en la capacidad de las empresas para explotar los numerosos avances recientes en las TIC, en la investigación operativa (IO) y la modelización estadística, de cara a recopilar y procesar datos de mercado y de operaciones para apoyar sus procesos de toma de decisiones. Como resultado, la analítica de negocios (business analytics) se ha convertido en un campo floreciente para la consultoría y la formación empresarial. Sin embargo, aunque muchas decisiones de algunos gobiernos a menudo vienen apoyadas con métodos tradicionales del análisis de políticas públicas, incluyendo aproximaciones como el análisis de coste-beneficio, pocos departamentos y agencias gubernamentales han logrado, por el momento, aprovechar de forma sistemática las grandes masas de datos disponibles, los hoy llamados big data, y los métodos avanzados de estadística y de aprendizaje automático (machine learning) para obtener evidencias que informen sus decisiones.
Este hecho constituye una interesante novedad desde una perspectiva histórica, ya que los métodos cuantitativos de ayuda a la toma de decisiones han surgido frecuentemente en el sector público. Por ejemplo, la estadística social, que se remonta a Quetelet, se inició en el siglo XIX para apoyar a los gobiernos a partir de la idea de que las regularidades estadísticas proporcionan señales sobre realidades sociales. Del mismo modo, el campo de la investigación operativa nació durante la Segunda Guerra Mundial al servicio de las fuerzas armadas de los Estados Unidos de América y del Reino Unido, y creció rápidamente a partir del desarrollo de distintos métodos de apoyo a la toma de decisiones en problemas militares.
Indudablemente, si lo comparamos con cómo se toman decisiones en el sector empresarial, los responsables de las decisiones públicas se enfrentan a tareas más complejas. Además de las dificultades propias de los problemas del sector privado, los decisores públicos deben enfrentarse a cuestiones adicionales relacionadas con el hecho de tomar decisiones por y para otras personas. Así, los responsables políticos se enfrentan a las cuestiones asociadas a decidir cómo se asignan los recursos públicos, tratándose de determinar “quién obtiene qué, cuándo y cómo”. Puesto que tales recursos son escasos, deben tomarse decisiones complejas, como en la famosa disyuntiva “cañones o mantequilla”. Por otra parte, si nos centramos en el caso de los sistemas democráticos, algunas de las peculiaridades adicionales de la toma de decisiones en el sector público se referirían a que:
El público y/o sus representantes toman las decisiones, dependiendo del grado de participación que se contemple.
Hay funcionarios públicos que, generalmente, se encargan de la gestión de la organización en la que debe tomarse la decisión.
En general, el público es el que financia los análisis previos a la toma de decisiones a través de sus impuestos.
Los impactos de la toma de decisiones afectan a la sociedad en general.
La valoración última de los resultados de una decisión es, típicamente, no solo monetaria sino que incorpora otros objetivos.
Los métodos empleados para informar sobre las decisiones están sujetos al escrutinio público.
Otras cuestiones que diferencian las decisiones públicas frente a las privadas se refieren a la coexistencia de distintos sistemas de valores y culturas en una sociedad, y que tales decisiones pueden verse afectadas por los breves horizontes electorales de los representantes, con el consiguiente riesgo asociado a adoptar una visión demasiado cortoplacista de lo público.
Nuestro objetivo en este libro es, por un lado, describir las técnicas y métodos para el análisis de big data, e ilustrar cómo pueden emplearse por parte de los gobiernos y ciudadanos para un mejor desarrollo de la sociedad.
Analítica para negocios
Ya hemos mencionado cómo en sus orígenes las disciplinas de la estadística y de la investigación operativa provenían del apoyo de la toma de decisiones en políticas públicas. Durante la última década, el crecimiento de la potencia de cálculo y los avances en tecnologías para grandes conjuntos de datos han proporcionado nuevas perspectivas en tales disciplinas, y en otras afines como el aprendizaje automático, lo que ha llevado a una nueva visión denominada analítica (analytics), que ha demostrado ser extremadamente valiosa para ayudar a los responsables de toma de decisiones en áreas de negocios y de la industria.
La analítica puede centrarse en enfoques descriptivos, predictivos o prescriptivos. Típicamente apoya el descubrimiento y la presentación de patrones relevantes en problemas con grandes conjuntos de datos registrados para cuantificar, describir, predecir y mejorar los resultados de una organización. Cuando nos referimos al entorno de negocios se denomina “analítica de negocios”, un término popularizado en los últimos años. A menudo combina métodos de la estadística, la IO, el aprendizaje automático y la informática, junto con disciplinas como la sociología, la psicología y la economía. La evidencia proporcionada por los datos se emplea para recomendar acciones y guiar las decisiones y la planificación en las organizaciones. Sus resultados pueden emplearse como entrada a la toma de decisiones por personas; pero también pueden alimentar sistemas automáticos de ayuda a la toma de decisiones. Por contraste, el ya más tradicional concepto de inteligencia de negocio (business intelligence) tiende a referirse a la extracción de información, la elaboración de informes y la provisión de alertas en conexión con algún problema aplicado de interés.
En la industria, el énfasis en el área de la analítica se ha puesto en resolver problemas relacionados con el análisis de conjuntos de datos masivos y complejos, frecuentemente en entornos muy cambiantes, más allá de la evolución y el desarrollo de sistemas de planificación empresarial y los almacenes de datos convencionales. Tales conjuntos de datos suelen denominarse big data y se caracterizan por tres rasgos típicos de los negocios que emplean sistemas transaccionales online:
Grandes volúmenes de datos generados. Como ejemplos, Walmart acumula más de 2,5 petabytes por hora de transacciones de clientes; Facebook recoge 300 millones de fotos y 2,7 millones de likes por día.
Gran heterogeneidad de los datos generados, que pueden provenir de fuentes tales como mensajes de blogs, imágenes en redes sociales, correos electrónicos, archivos PDF, datos geoespaciales, lecturas de sensores en una ciudad o señales GPS en teléfonos móviles. De hecho, hoy en día podríamos contemplarnos cada uno de nosotros como generadores permanentes de datos a partir de las interacciones con nuestros smartphones.
Datos generados a gran velocidad. En muchos casos, la velocidad de generación tiende a ser más importante que el volumen disponible, en el sentido de que se deben tomar decisiones, teniendo que evaluarse la información, a partir de los datos obtenidos, todo ello en tiempo real.
Así pues, disponemos de una cantidad cada vez mayor de información digitalizada proveniente de dispositivos y sensores cada vez más baratos. En consecuencia, nos enfrentamos a una nueva era en la que hay una enorme cantidad de datos digitales —el mar de datos— sobre numerosos temas de interés potencial para una empresa o un gobierno. Sin embargo, con bastante frecuencia dicha información es altamente desestructurada y difícil de gestionar y, a veces, poco relevante, aportando poco valor.
El análisis de estos tipos de datos no estructurados, o no muestreados, constituye un reto importante en la industria y ha dado lugar a nuevos paradigmas como la ciencia de datos y la ingeniería de datos. Los datos no estructurados difieren de los que lo son en que su formato es muy variable y no pueden almacenarse en bases de datos relacionales tradicionales sin un esfuerzo significativo que conlleve transformaciones complejas de los mismos. Se emplean así bases de datos NoSQL (not only SQL) más escalables, siendo un ejemplo MongoDB, Cassandra o CouchDB. Gestionar tales masas de datos requiere marcos que permitan realizar cálculos paralelizables a gran escala, como MapReduce y su implementación Hadoop, que facilita el procesamiento distribuido sobre conjuntos más pequeños de datos. Finalmente, necesitamos también infraestructuras de almacenamiento que faciliten el resumen de datos y sus análisis, como Hive. Dentro de estos desarrollos tecnológicos, deberíamos mencionar Python como el actual lenguaje principal de programación con propósito numérico, así como R, para inferencia y predicción.
Además de los avances tecnológicos, también hay nuevas clases de métodos de análisis que permiten la extracción de información de conjuntos masivos de datos. Estos van más allá de las técnicas tradicionales, como los modelos de regresión, los de series temporales, basados por ejemplo en modelos dinámicos lineales o los clasificadores de k vecinos más cercanos; llegando a métodos más recientes como los árboles de clasificación y de regresión, los conjuntos de máquinas (ensemble methods), las máquinas de soporte vectorial (support vector machines) o las redes neuronales profundas. Con frecuencia, estos requieren nuevas implementaciones como en el caso de la biblioteca en R biglm para la regresión lineal en lugar del tradicional lm. Otro ejemplo es Mahout, que facilita la clasificación y el análisis de conglomerados sobre Hadoop. La mayor parte de los algoritmos más usados en aprendizaje automático están implementados en bibliotecas de código abierto en los lenguajes de programación más utilizados en ciencia de datos, como scikit-learn (python), caret (R), MLLib (Apache Spark), etc., cuyas versiones se actualizan con frecuencia para incluir nuevos desarrollos o mejoras en rendimiento. El análisis de redes sociales, con orígen en la sociología, y otros métodos analíticos de estructuración y extracción de significado, como los mapas cognitivos, también están ganando importancia cuando nos enfrentamos a datos provenientes de redes sociales. Las herramientas de inteligencia artificial (IA) para el procesamiento de lenguaje natural también están experimentando un desarrollo considerable en los últimos años.
En cualquier caso, los datos parecen ahora más accesibles a los gestores, que tienen una gran oportunidad para tomar mejor sus decisiones utilizándolos para aumentar sus ingresos, reducir sus costes, mejorar el diseño de sus productos, detectar y prevenir el fraude o la mejora de la participación de clientes a través del marketing personalizado. Esto ha conducido a un nuevo concepto de empresa que toma decisiones basadas en la evidencia, con ejemplos claros como Google, Facebook, Amazon, Walmart y algunas de las líneas aéreas más avanzadas.
Analítica para políticas públicas
Las mismas cuestiones mencionadas en relación con la disponibilidad y el posible uso de datos se están encontrando en el contexto de las políticas públicas, como por ejemplo en los casos de los ingresos hospitalarios, de los registros médicos electrónicos, de los datos meteorológicos, de la venta de propiedades o de los datos procedentes de cámaras de vigilancia o de posicionamiento de teléfonos móviles, entre muchas otras fuentes que pueden ser tremendamente útiles para numerosos departamentos gubernamentales. Además, estas fuentes coexisten con otras más tradicionales procedentes de sistemas prediseñados de recopilación masiva de datos, como los censos, los documentos de recaudación de impuestos o los distintos sondeos que realizan los gobiernos.
Así, podríamos pensar en aplicar la analítica para apoyar la toma de decisiones en la elaboración de políticas públicas, lo que lleva, de forma natural, al concepto de analítica para políticas (policy analytics). Sin embargo, cuando se realiza una búsqueda de ese término vemos que aparecen solo un par de empresas con nombre relacionado (Policy Analytics, Public Policy Analytics) y empresas como Oracle, Booz-Allen-Hamilton o IBM que han incluido el término dentro de su cartera de actividades. Carnegie Mellon tiene también una sección de analytics dentro de su programa de políticas públicas. Pero, como mencionamos en la introducción, pocas decisiones gubernamentales se benefician ya del aprovechamiento sistemático de grandes masas de datos y técnicas avanzadas de modelización.
Por comparación con las aplicaciones industriales, no es difícil vislumbrar las enormes aplicaciones potenciales que tendrían en problemas como examinar la distribución de los patrones de sucesos de salud, el desarrollo racional de planes para infraestructuras, el empleo del conocimiento sobre comportamientos para promover la eficiencia energética, el desarrollo de servicios personalizados de gobierno, la mejora de la experiencia en visitas turísticas, la identificación de barrios con servicios sociales inadecuados o el diseño de ciudades inteligentes, entre otros muchos.
El camino que nos espera
En este libro haremos una revisión de los conceptos, tecnologías y metodologías propias del big data y una reflexión a través de ejemplos reales y potenciales sobre cómo este fenómeno puede ayudar, y también perjudicar, en la toma de decisiones y políticas públicas dirigidas a mejorar nuestras sociedades. Así, en las siguientes páginas responderemos a preguntas como ¿por qué han empezado a ser relevantes estas disciplinas en tiempos recientes?, ¿cuáles son las principales tecnologías y metodologías empleadas en ciencia e ingeniería de datos?, ¿por qué hay un predominio, por el momento, de estas disciplinas en el sector privado?, ¿qué fuentes de datos, de origen público y privado, son relevantes en la toma de decisiones públicas?, ¿en qué campos de aplicación en política pública podríamos emplear la ciencia de datos?, ¿qué aspectos éticos y de privacidad deberíamos tener en cuenta en un proyecto big data aplicado al sector público?, ¿qué efectos laborales está teniendo la automatización de tareas y la inteligencia artificial en la transformación de sectores productivos?, ¿cómo pueden ayudar los métodos de ciencia de datos en las distintas fases del ciclo de análisis de las políticas públicas?
Figura 1
Posicionamiento interdisciplinar de la ciencia de datos según estudiamos en este libro.
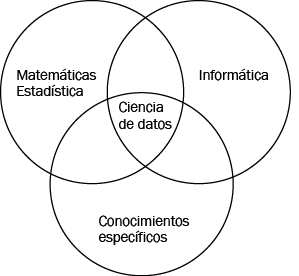
El libro viene estructurado en torno a una visión de la ciencia de datos como sinergia de disciplinas de tipo estadístico-matemático, informático y de conocimientos específicos del campo de aplicación que nos incumba.
Así, en el capítulo 2 hacemos una revisión introductoria a las tecnologías del big data. Después, presentamos de forma concisa las metodologías principales de aprendizaje automático y estadística para predicción en presencia de big data. Los siguientes tres capítulos se refieren a aplicaciones específicas: el capítulo 4 cubre aplicaciones en política y administración públicas; después en sanidad, y, finalmente, en ciberseguridad. Por último, concluimos discutiendo aspectos éticos y sociales del big data y presentando una mirada al futuro de aplicaciones del big data para la mejora de la sociedad.