Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
https://t.me/reading_ai, @AfeliaN🗂️ Project Page
📄 Paper
Main idea
This paper is devoted to investigating if LDM contains inside its internal representation some geometrical scene quality. The authors found, that the internal activations of the LDM encode linear representations of both 3D depth data and a salient-object/ background distinction. These representations appear surprisingly early in the denoising process.
Pipeline
The authors used Probing Classifiers to interpret the representation learned by LDM model.
Two different tasks were considered:
- discrete binary depth
- continuous depth
Binary depth: salient object and background
To investigate discrete binary depth representations inside the LDM the intermediate output was extracted from its self-attention layer l at sampling step t. A linear classifier is trained on this output to predict pixel-level logits.

The Metric for segmentation performance - Dice coefficient.
Continuous relative depth information
Similarly the output from self-attention layers was extracted and a linear regressor was trained on them to predict the MiDaS relative depth map.

The regressor was trained using Huber loss. Some additional experiments with regularizers were conducted, but they had a negative impact on probing.


The sizes of attention blocks:

Implementation details
Dataset: for the experiment a synthesized dataset was used. 1000 images were generated from latents and corresponding prompts using pre-trained Stable Diffusion.
Models:
- Diffusion model: Stable diffusion
- Depth estimation: MiDaS
- Binary depth: TRACER
Results

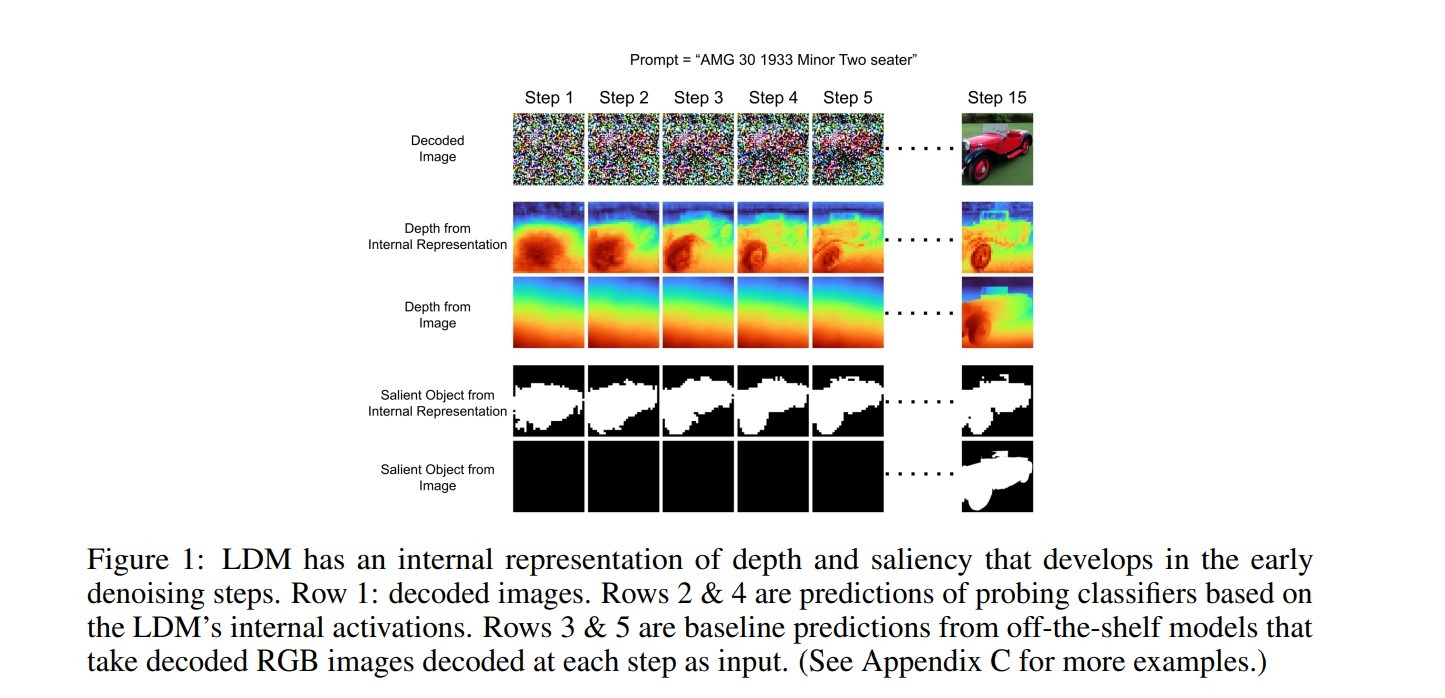

Interesting facts:
- For both probing tasks, the performance difference between successive denoising steps vanished after step 5. High probing performance at the early steps suggests an exciting behavior of LDM: the depth dimension develops at a stage when the decoded image still appears extremely noisy to a human.
- Deeper representation gives more information (except bottleneck)
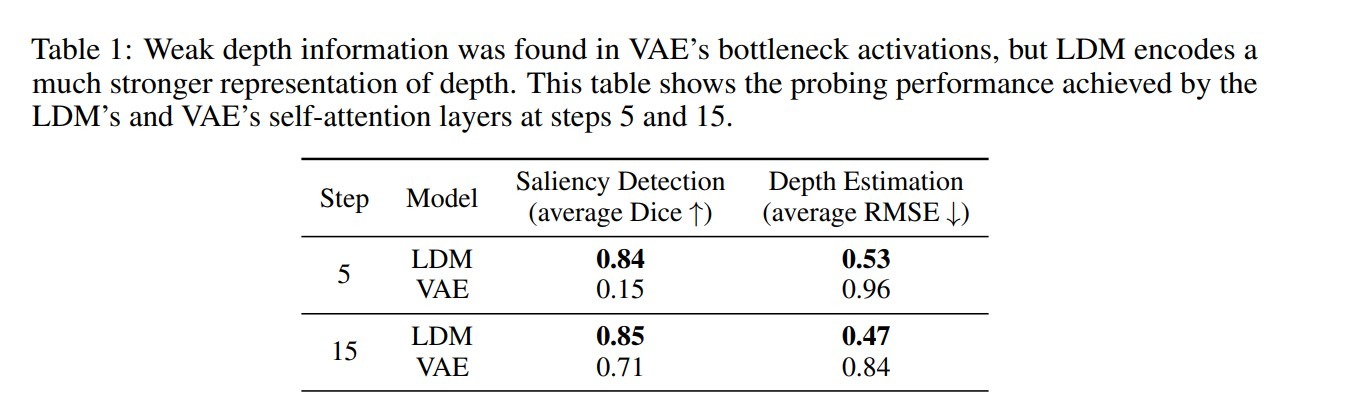
What if VAE contains knowledge?

Intervention experiment
If changing the depth representation, with the same prompt and initial input, will lead to a corresponding change in apparent depth in the output image?
When translating the object’s representation, the authors used a modified salient object mask d as the reference.

The intervention then modifies the LDM’s representation so the probing classifier’s output, if using a modified representation as input. This is achieved by updating the internal representation ϵθ(l,t) using gradients from the probing classifier

As the result of such intervention:

