Azure SQL: DTU супраць vCore
Арцём Мікуліч | АБАЖУРЫНе так даўно мне давялося перавозіць паўнавартасны SQL Server з віртуальнай машыны ў Azure SQL. Вандроўка выдалася багатай на адкрыцці і натхніла мяне напісаць гэты артыкул.
Дзеля лаканічнасці будзем лічыць, што рашэнне ісці менавіта ў Azure SQL ужо прынятае (мой артыкул пра IaaS vs. PaaS вось тут, пачытайце). Асноўную ўвагу я засяроджу на тым, як выбіраў паміж DTU і vCore з пункту гледжання Performance. Сёння давядзецца паглыбіцца ў дэталі, таму будзьце гатовыя пачуць пра performance тэсты, жалеза, tempdb, execution планы і г.д.

Крок 1 - Выбраць памер
Афіцыйная дакументацыя не дае адназначнага адказу на пытанне, як DTU суадносяцца з vCore і з ядрамі паўнавартаснай віртуальнай машыны”. Усе адказы сыходзяцца да “it depends”, што насамрэч мае сэнс, бо нагрузка ў кожнай сістэме ўнікальная. Тым не менш, можна знайсці наступную формулу для стандартных планаў:
100 DTU ~ 1 vCore.
Арыгінальны сервер працаваў на 4-ох ядрах, а значыць кандыдатамі на тэставанне становяцца:
- Azure SQL Standard 400 DTU.
- Azure SQL General Purpose 4 vCore.
Крок 2 - Выбраць метадалогію тэставання
Я асэнсавана адразу адмовіўся ад ідэі напісання сінтэтычных тэстаў, бо найдакладнейшыя метрыка – гэта тое, як сістэма працуе з сапраўднымі данымі і запытамі. Таму выбар спыніўся на тэставанні існуючых API (http) з замерам часу на апрацоўку запыту. Адзін сцэнар уключаў адпраўку серыі запытаў, кожны з якіх ствараў розную па моцы і характары нагрузку на базу даных.
У межах артыкулу я прысвоіў кожнаму сцэнару імёны, якія адлюстроўваць, што будзе адбывацца з пункту гледжання базы. Пабачыць поўны спіс можна ніжэй.
- Сцэнар 1: Medium SELECTs.
- Cцэнар 2: Large SELECTs.
- Сцэнар 3: Medium UPDATEs.
- Сцэнар 4: Medium INSERTs.
- Сцэнар 5: Large INSERTs.
- Сцэнар 6: Extremely Large INSERTs.
- Сцэнар 7: All-in.
Напрыклад, сцэнар Medium SELECTs уяўляе сабой запыты з некалькімі JOIN, сартыроўкай і фільтрацыяй. Large SELECTs – больш складаны запыт са шматпавярховымі JOIN. З іншага боку, All-in – найскладанейшы сцэнар, які ўключае ўвесь спектр read/write аперацый. Усё астатняе – нешта пасярэдзіне.
Адзін прагон уключаў выкананне кожнага са сцэнароў па чарзе. Пасля гэтага скрыпт выдаляў базу і замяняў яе бэкапам. Пасля некалькіх такіх прагонаў на адным тыпе базы, яе tier замяняўся (напрыклад, з 400 DTU на 4 vCore) і ўвесь працэс паўтараўся.
Крок 3 - Інтэрпрэтацыя вынікаў
Ад тэстаў я чакаў, што DTU пакажа больш сціплыя вынікі ў параўнанні з vCore. Хіба сапраўдныя ядры не ляпшэйшыя за абстрактныя? Да таго ж сам Microsoft пазіцыянуе DTU як рашэнне ў першаю чаргу для невялікіх сістэмаў. Але вынікі апынуліся нечаканымі.
Шчыра скажу, атрымліваць стабільныя вынікі ў Azure няпроста: лічбы могуць адрознівацца на 20-30% у залежнасці ад часу правядзення тэсту (а можа фаза Месяца таксама ўплывае). Тым не менш, сабраныя даныя адлюстроўваюць агульную карціну.
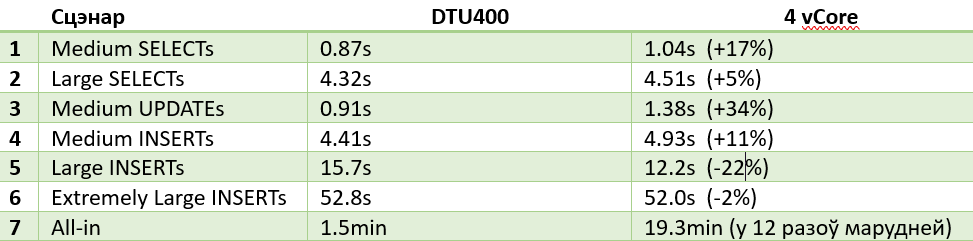
Мой фаварыт 4 vCore выступіў спрэчна: часцей за ўсё ён быў маруднейшы за свайго DTU візаві, але ў некаторых сцэнарах (5, 6) стабільна быў наперадзе. У той жа час самы цяжкі сцэнар (7) паставіў зарэзерваваныя ядры ў тупік: 19.3 хвіліны супраць 1.5! Дэградацыя больш за 12 разоў не ідзе ні ў якую браму. І гэта паўтаралася ў 100% тэстаў.
З дапамогай прафайлера ў Azure Data Studio я выйшаў на адзін з праблемных запытаў. Паглядзіце на частку яго execution плана ніжэй.

Акрамя таго, што сартыроўка доўжылася 74 секунды, у вочы кідаецца жоўты клічнік. Вось дэталёвы тэкст папярэджання.

Гэта сведчыць пра тое, што рухавік SQL падчас сартыроўкі выгрузіў даволі вялікі датасэт (880Mb) у часовую базу tempdb, іншымі словамі - на жорсткі дыск (SSD). Негледзячы на тое, што сучасныя SSD нашмат хутчэйшыя за класічныя HDD, яны ўсё адно маруднейшыя за аператыўную памяць. З-за гэтага і прасеў performance!
Наступным крокам я паглядзеў, як з той жа самай аперацыяй спраўляецца 400 DTU. Я чакаў, што пабачу нейкі іншы execution plan, але зноў памыліўся. План супадаў цалкам з тым, што я бачыў у 4 vCore: па структуры, па коштах і па адзнаках. Але было адно маленькае выключэнне.

На той самай сартыроўцы няма ніякага папярэджання, то бок аперацыя без праблем выканалася ў аператыўнай памяці. Як след – 5 секунд замест 74!
Я ўзброіўся данымі тэстаў і ад імя кліента схадзіў на сустрэчу з прадстаўніком Azure, які замацаваны за праектам. На жаль, я не атрымаў жаданага тлумачэння, чаму DTU адольвае нагрузку, а vCore не. Адказ можна падсумаваць як “дакладна перавесці DTU у Cores і наадварот немагчыма”, а таксама, што “ў вашым выпадку варта выбраць 6 vCore”.
Я прыйшоў да высновы, што DTU мае ўбудаваны механізм аўтаматычнага маштабавання памяці, што ў пікавы момант дае крыху больш рэсурсаў у параўнанні з фіксаваным vCore. Гэта ўрэшце рэшт дазваляе аператыўцы “вывезці” той запыт, у той жа час калі vCore выкідвае белы сцяг і ідзе па tempdb.
Высновы
У гэтым benchmark я аддаю перамогу Azure SQL 400 DTU. Нягледзячы на маруднасць у некаторых тэстах ён забяспечвае трывалую працу сістэмы. Мне пашанцавала эксперыментальна патрапіць на сапраўдны crashing point, калі vCore робіць падножку, а DTU “падстаўляе плячо”. Гэта цікавы досвед - амаль як у славутай перадачы MythBusters.
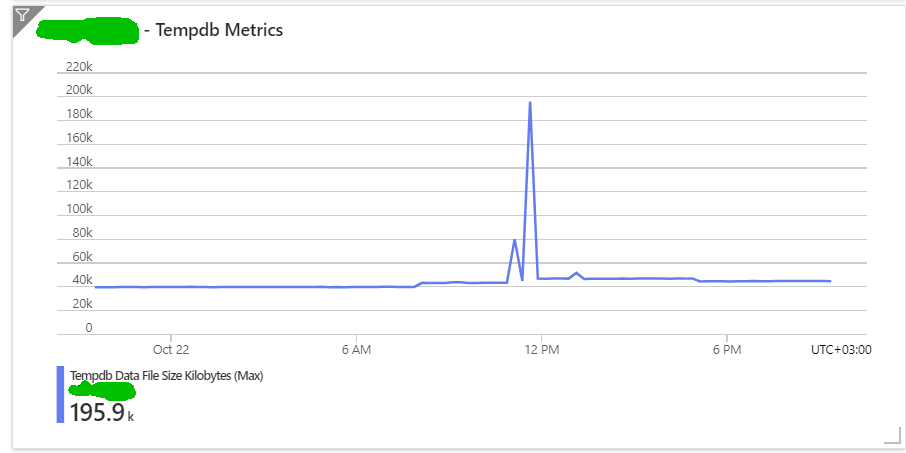
Яшчэ адзін карысны вынік у тым, што пасля тэстаў стала зразумела, якія табліцы/запыты патрабуюць неадкладнай увагі. Акрамя гэтага я дадаў у маніторынг памер tempdb, каб адсочваць такія праблемы на прадакшэне.
P.S.
“Дзеля навукі” я прагнаў тэсты яшчэ на 6 vCore і 800 DTU (версіі 600 няма), якія паказалі амаль аднолькавыя вынікі, на 10-15% лепшыя за DTU 400. Без дэградацыі ў складаных сцэнарах - відавочна з-за большага аб'ёму памяці.