Автоматизація тестування: Page Object Model
Стаття від нашого QA Lead - Олексія
Автотести представляють собою заскриптовані дії у браузері із певними умовами, що формують собою перевірки (в успішно задовільненій умові і є суть пройденого тесту).
Автоматизатор на низькому рівні абстракції постійно вирішує три задачі: як чітко і стабільно ідентифікувати елемент сторінки, як імплементувати взаємодію із ним та як сформулювати умови перевірки. Ці задачі упродовж часу вирішувалися різними підходами — від прямолінійного написання усього в межах одного файлу до певних паттернів дизайну, які розділяють об’єкти за призначенням. Про один із найбільш усталених і ефективних паттернів, Page Object Model (POM) в цьому дописі і піде мова.
Одразу варто зазначити, що РОМ далеко не єдиний паттерн проектування фреймворку автоматизації, який використовують для вирішення сучасних задач. Радше, він добряче перевірений часом і достатньо універсальний, щоби починати із нього і або зупинятися на ньому, або йти далі до паттернів, що від нього запозичують (наприклад, Screenplay паттерн).
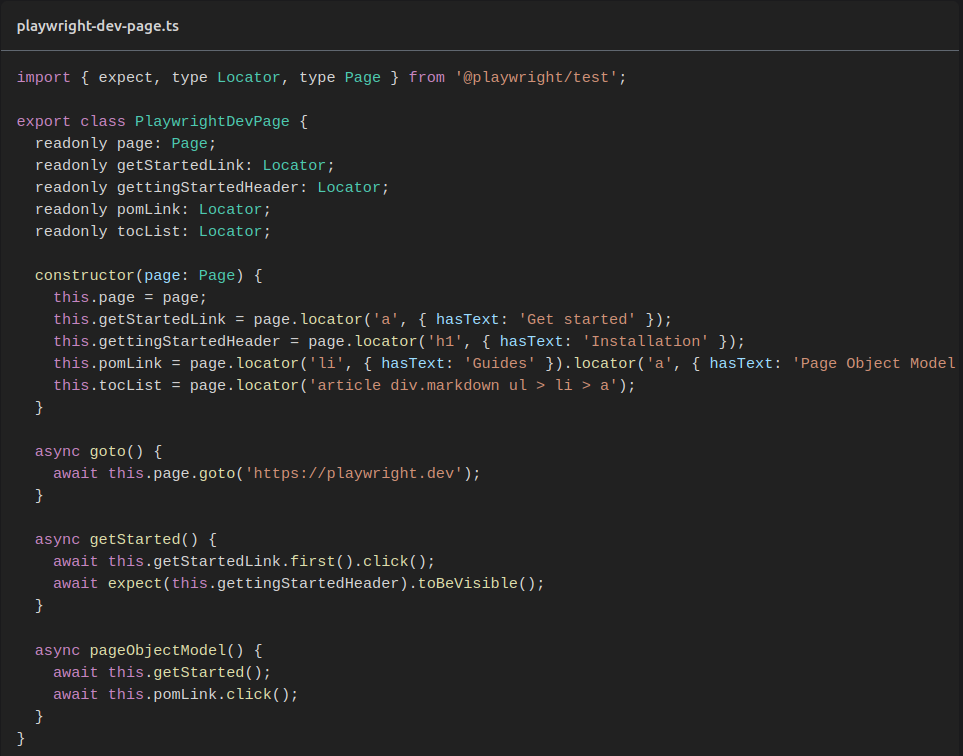
Ідея Page Object Model відображена в його назві. Замість того, щоби звалювати в один файл і опис об’єктів, і опис логіки взаємодії із ними в якості кроків реально тесту, підхід POM пропонує розбити увесь проєкт на фреймворк автоматизації та самі тести. Кожна сторінка має розглядатися як окремий об’єкт — абстракція, що буде описана (наприклад, sign-up-page.ts чи create-listing-page.ts). Якщо сторінки надто комплексні, або якщо певний логічний елемент трапляється у кількох місцях одночасно, об’єктом може виступати не повна сторінка, а якийсь її блок, частина (наприклад, header.ts чи footer.ts).
Ця модель сторінки або елементу міститиме в собі ідентифікацію усіх причетних елементів сторінки (через відповідні селектори або інші механізми, передбачені фреймворком). Ця модель також може містити імплементацію методів — унікальних взаємодій, властивих конкретно для цієї моделі. Це зовсім не обов’язкова частина, оскільки сучасні фреймворки містять в собі багатий інструментарій стандартних взаємодій (клікнути елемент, навести на елемент, написати щось в поле, обрати із дропдауну тощо). І якщо такі методи і будуть присутні, то вони стосуватимуться не окремих елементів, а радше ідей, наприклад, “заповнити дату народження” або “розмістити замовлення”.
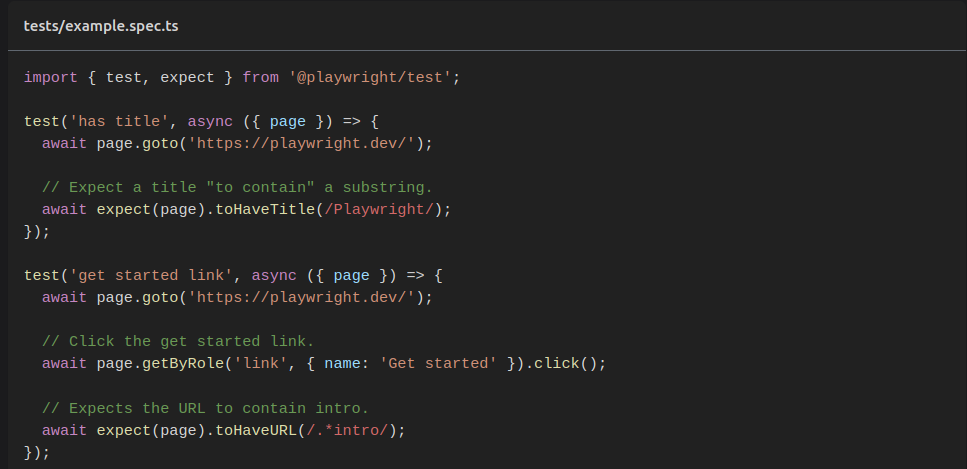
Описавши таким чином усе, що сторінка у собі містить, та що на ній можна робити на рівні ідей, ми переходимо до написання самих тестів. Тести з вмістилища всього перетворюються на послідовність звернення до описаних нами же елементів та дій. Таким чином ми лише комбінуємо та параметризуємо готові елементи, як того вимагають задачі. Перевірки, тобто умови, інколи також включають до моделей, але частіше вони є надто унікальними та непередбачуваними, тому їх імплементують вже в рамках написання тестів.
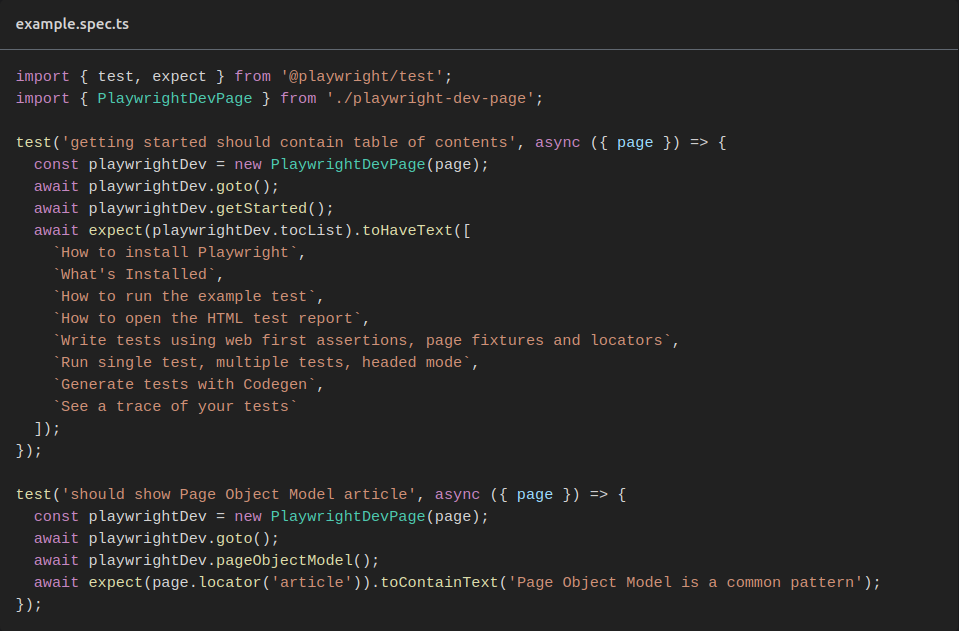
Перш за все, РОМ допомагає винести усю логіку за тести, що суттєво спрощує підтримку. 10 простеньких тестів підтримувати не так складно, але якщо їх сотні, що за різною логікою працюють з одними й тими ж сторінками, вносити зміни у кожен стає надто довго. Можна сказати, що РОМ — це слідування принципу розробки Don’t Repeat Yourself (DRY): ми виносимо однакові логічні структури в окремий файл, на елементи та методи якого посилаємося у тестах. Будь-які зміни у логіці чи структурі сторінки коштуватимуть нам змін в одному місці, а не в десяти.
В свою чергу, це сприяє масштабуванню фреймворку автоматизації. Якщо ростиме проект, то і фреймворк разом із ним, а цей паттерн значно спростить розширення бази автотестів.
Також РОМ сприяє декларативності, себто зрозумілості написаних тестів, оскільки замість довжелезних локаторів, блоків if та for він оперує читабельними назвами елементів та методів типу loginField, createListing тощо.
Детальніше про РОМ можна почитати у статті на guru99, на toolsqa чи в документації webdriver.