Автоматизация и масштабирование инфраструктуры приложений с Docker Swarm и AWS

Вступление
Swarm — один из ведущих инструментов оркестрации и управления кластерами, которым упрощается масштабирование приложений и инфраструктуры. Используя децентрализованные роли и встроенную балансировку нагрузки Swarm, мы обеспечиваем высокую доступность и сверхбыстрое развертывание с минимальными накладными расходами.
Продемонстрируем это.
Что будем создавать?
- Среду Docker Swarm с одним управляющим узлом и тремя рабочими узлами.
- Стек Docker для развертывания 3-уровневой архитектуры приложений с тремя службами Docker: Web/Apache, Node.js и Postgres.

Понадобятся:
- Учетная запись AWS с доступом пользователя IAM.
- Учетная запись Docker Hub.
- Базовые знания о Docker, Docker Compose и командах CLI.
- Знание экземпляров EC2 Amazon и консоли управления AWS.
- Знание файловых систем и команд Linux.
- Доступ к инструменту командной строки.
- IDE, например VS Code.
Ключевые понятия
Узел — это физическая или виртуальная машина, на которой размещается приложение и выполняются различные роли: управляющая или рабочая. Управляющим узлом интерпретируются службы и по всем рабочим узлам распределяются задачи. Выданные управляющим узлом задачи выполняются рабочим узлом.
Задача — это просто контейнер Docker и набор выполняемых в нем инструкций или команд.
Этап 1. Подготовка
Прежде чем переходить к Docker Swarm, настроим серверы/машины для узлов Swarm. Воспользуемся экземплярами EC2 Amazon, виртуальные и локальные машины тоже сгодятся.
Понадобится:
- Один экземпляр EC2 с управляющим узлом.
- Три экземпляра EC2 с рабочим узлом.
Группы безопасности
Для взаимодействия всех узлов в Docker Swarm нужен доступ к определенным портам:

Создадим две группы безопасности: swarm_app_mgr_sg для управляющего узла, swarm_app_wkr_sg для рабочих узлов.
СНАЧАЛА СОЗДАЕМ ГРУППЫ, ЗАТЕМ ДОБАВЛЯЕМ ДЛЯ НИХ ПРАВИЛА ВХОДЯЩИХ ПОДКЛЮЧЕНИЙ. ДЛЯ КАЖДОГО ПРАВИЛА ЗАДАЕМ ИСТОЧНИК ГРУПП БЕЗОПАСНОСТИ MGR/WKR, ДОБАВИТЬ ЕГО К SG ПОТОМ В AWS НЕ ПОЛУЧИТСЯ.
Правила входящих подключений для групп безопасности управляющего узла:
- SSH | TCP | Порт: 22 | Источник: мой IP
- HTTP | TCP | Порт: 80 | Источник: IPv4 везде
- HTTPS | TCP | Порт: 443 | Источник: IPv4 везде
- Пользовательский TCP | TCP | Порт: 8080 | Источник: IPv4 везде
- Пользовательский TCP | TCP | Порт: 2377 | Источник: swarm_app_wkr_sg
- Пользовательский TCP | TCP | Порт: 7946 | Источник: swarm_app_wkr_sg
- Пользовательский UDP | UDP | Порт: 7946 | Источник: swarm_app_wkr_sg
- Пользовательский UDP | UDP | Порт: 4789 | Источник: swarm_app_wkr_sg
Правила входящих подключений для групп безопасности рабочего узла:
- SSH | TCP | Порт: 22 | Источник: мой IP
- HTTP | TCP | Порт: 80 | Источник: IPv4 везде
- HTTPS | TCP | Порт: 443 | Источник: IPv4 везде
- Пользовательский TCP | TCP | Порт: 7946 | Источник: swarm_app_mgr_sg
- Пользовательский UDP | UDP | Порт: 7946 | Источник: swarm_app_mgr_sg
- Пользовательский UDP | UDP | Порт: 4789 | Источник: swarm_app_mgr_sg
Создаем сервер управляющего узла
Если Docker Swarm — это оркестр, то управляющие узлы — дирижеры и администраторы. Их задача — контролировать/распределять службы и задачи между рабочими узлами. Кроме того, управляющими узлами при необходимости узлы добавляются/удаляются, повышаются/понижаются их роли. Это центр администрирования среды приложения.
Обычно для высокой доступности нужно несколько управляющих узлов, но пока хватит одного.
Создадим шаблон запуска EC2 swarm_node_template и к каждому поднимаемому серверу/узлу применим одинаковые настройки.
Настройки шаблона запуска:
- AMI: Amazon Linux 2.
- Type: бесплатный уровень t2.micro, но выбирайте в соответствии с требованиями приложения.
- Key pair: выбирается/создается пара ключей.
- Network: сети, задаются при запуске экземпляров.
- Advanced Details User data: здесь добавляется скрипт bash, по которому при запуске экземпляров устанавливаются, включаются и запускаются Docker и Docker Compose. Скопируйте и вставьте в раздел User details этот скрипт:
sudo yum update -y sudo yum install -y docker #устанавливаем docker compose sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose sudo systemctl enable docker sudo systemctl start docker
На этом шаблоне запустим экземпляр swarm_app_mgr и подключим группу безопасности swarm_app_mgr_sg. Воспользуемся виртуальным частным облаком по умолчанию и подсетью.
Создаем серверы рабочего узла
Тем же шаблоном запустим на рабочих машинах три экземпляра swarm_app_wkr1, swarm_app_wkr2 и swarm_app_wkr3 с группой безопасности swarm_app_wkr_sg:

Этап 2. Создание Swarm
Создадим среду Swarm и присвоим каждому экземпляру EC2 его роль узла.
Присваиваем роль управляющего узла
Сначала подключимся по SSH к экземпляру управляющего узла и, запустив docker --version и docker-compose --version, проверим установленные версии Docker и Docker Compose:

АВТОРИЗУЕМСЯ СО СВОИМ ИМЕНЕМ ПОЛЬЗОВАТЕЛЯ В DOCKER HUB И ПАРОЛЕМ SUDO DOCKER LOGIN.Создадим Swarm и присвоим этому серверу роль управляющего узла:
sudo docker swarm init

Мы получили управляющий узел и направления для создания новых управляющих/рабочих узлов.
IP-адрес — это частный IP-адрес экземпляра. Это важно, потому что управляющему узлу для подключения рабочих узлов нужен статический IP-адрес. Скопируйте ту первую команду.
В ЭТОМ СЛУЧАЕ В SWARM ПРАВИЛЬНЫЙ IP-АДРЕС ОПРЕДЕЛИЛСЯ АВТОМАТИЧЕСКИ, НО ИНОГДА ВЫ НАПРАВЛЯЕТЕСЬ НА «РЕКЛАМУ» IP-АДРЕСА. И ТОГДА ПРИДЕТСЯ СНОВА ЗАПУСТИТЬ КОМАНДУ INIT С ДОПОЛНИТЕЛЬНЫМ ПАРАМЕТРОМ --ADVERTISE-ADDR <YOUR_IP_ADDRESS>.Присваиваем роли рабочих узлов
Скопировав команду, откроем еще три окна терминала и подключимся по SSH к каждому экземпляру рабочих узлов. Вставляем команду, данную от управляющего узла, и получаем подтверждение добавления каждого узла в Swarm:
sudo docker swarm join --token <TOKEN> <MANAGER_IP_ADDRESS>
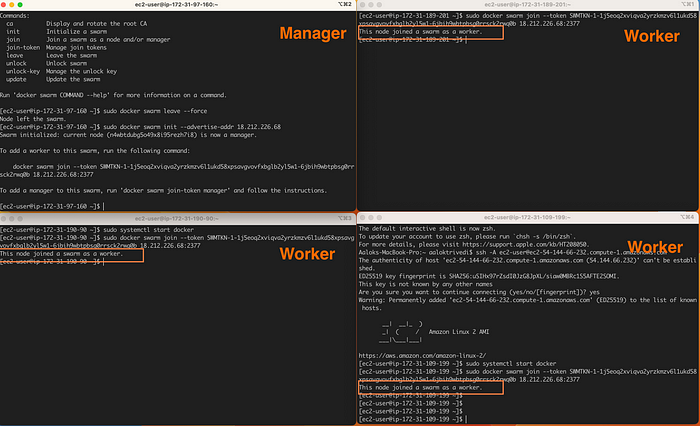
Чтобы просмотреть все узлы с их статусами, в терминале управляющего узла запускаем sudo docker node ls. Звездочкой * обозначается узел, в котором мы сейчас находимся

ЕСЛИ ЗАПУСТИМ ЭТУ ЖЕ КОМАНДУ В ТЕРМИНАЛЕ РАБОЧЕГО УЗЛА, ПОЛУЧИМ СООБЩЕНИЕ ОБ ОШИБКЕ:
ERROR RESPONSE FROM DAEMON: THIS NODE IS NOT A SWARM MANAGER. WORKER NODES CAN’T BE USED TO VIEW OR MODIFY CLUSTER STATE. PLEASE RUN THIS COMMAND ON A MANAGER NODE OR PROMOTE THE CURRENT NODE TO A MANAGER. (РЕАКЦИЯ НА ОШИБКУ ОТ ДЕМОНА: «ЭТО НЕ УПРАВЛЯЮЩИЙ УЗЕЛ SWARM. РАБОЧИЕ УЗЛЫ НЕ ИСПОЛЬЗУЮТСЯ ДЛЯ ПРОСМОТРА ИЛИ ИЗМЕНЕНИЯ СОСТОЯНИЯ КЛАСТЕРА. ЗАПУСТИТЕ ЭТУ КОМАНДУ В УПРАВЛЯЮЩЕМ УЗЛЕ ИЛИ ПОВЫСЬТЕ РОЛЬ ТЕКУЩЕГО УЗЛА ДО УПРАВЛЯЮЩЕГО).ТАК ЗАДУМАНО: ВСЕ АДМИНИСТРИРОВАНИЕ И ОРКЕСТРАЦИЯ ВЫПОЛНЯЮТСЯ ТОЛЬКО С УПРАВЛЯЮЩИХ УЗЛОВ.
ДОПОЛНИТЕЛЬНЫЙ БОНУС: ЧТОБЫ ЛЕГЧЕ РАСПОЗНАВАТЬ, ЧТО ЕСТЬ ЧТО, Я ПОМЕНЯЛ ИМЕНА ХОСТОВ ДЛЯ КАЖДОГО УЗЛА. ВОТ КАК ЭТО ДЕЛАЕТСЯ.
Другие терминалы рабочих узлов больше не понадобятся, поэтому закрываем их или сворачиваем.
Теперь узлы Swarm готовы к работе.
Этап 3. Создание стека Swarm
Базовая среда настроена, определим и развернем архитектуру приложения. Приложение настраивается на трех уровнях.
- Уровень фронтенда/веба: на веб-серверах Apache, 10 реплик.
- Уровень бэкенда/приложения: на Node.js, 4 реплики.
- Уровень бэкенда / базы данных: на Postgres, 1 реплика.
У НАС НЕТ ФАКТИЧЕСКОГО ИСХОДНОГО КОДА ПРИЛОЖЕНИЯ ДЛЯ РАЗВЕРТЫВАНИЯ, НО ПРОЦЕСС ТОТ ЖЕ.
И это декларативный процесс, где нужно только определить ресурсы и конечный результат. Все остальное, в том числе что нужно для достижения этого результата, — забота Swarm.

Мы определяем все узлы, службы, образы, тома и параметры развертывания, на Swarm — балансировка нагрузки и распределение служб/контейнеров между доступными узлами.
При сбое задачи, например экземпляра службы/контейнера, в Swarm она автоматически завершается и ей на замену создается новая для восполнения общего количества объявленных реплик.
Если случается сбой узла или он становится недоступен, необходимые службы и контейнеры перераспределяются между доступными узлами. Этим объясняется такая высокая доступность и отказоустойчивость Swarm.
Docker Compose
Конечно, службы и задачи создаются отдельно с помощью команд Docker CLI, но это муторно и времязатратно. Лучше создадим с Docker Compose Swarm-стек и оркестрируем всю архитектуру одним файлом и одной командой.
Стек создается из файла docker-compose.yml. Все то же самое, что и в Docker Compose, но в дополнение к службам, портам, томам и сетям с помощью стека определяются параметры развертывания. Мы указываем число реплик для каждой службы, ограничения на размещение, политики перезапуска, политики отката и многое другое.
Но закончим с предисловиями, пора за работу.
Так же подключаясь по SSH к управляющему узлу, создадим новый файл docker-compose.yml или клонируем репозиторий Github с файлом compose внутри.
Напомним: это базовая структура файла compose. У нас имеется четыре службы* и две мостовые сети для фронтенда и бэкенда:
version: "3.8"
services:
web:
node:
db:
visualizer:
networks:
frontend:
driver: bridge
backend:
driver: bridge
volumes:
version: "3.8"
services:
web:
image: httpd:2.4.55
ports:
- 80:80
networks:
- frontend
deploy:
replicas: 10
placement:
constraints: [node.role == worker]
restart_policy:
condition: on-failure
node:
image: node:19-alpine3.16
networks:
- frontend
- backend
command: ["sleep", "10000"] # это только для принудительного сохранения контейнера запущенным, ведь фактического кода приложения нет
deploy:
replicas: 4
placement:
constraints: [node.role == worker]
restart_policy:
condition: on-failure
db:
image: postgres:15.2
volumes:
- db-data:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=mypass
networks:
- backend
deploy:
replicas: 1
placement:
constraints: [node.role == worker]
restart_policy:
condition: on-failure
visualizer:
image: bretfisher/visualizer
ports:
- 8080:8080
stop_grace_period: 1m30s
networks:
- frontend
volumes:
- /var/run/docker.sock:/var/run/docker.sock
deploy:
placement:
constraints: [node.role == manager]
networks:
frontend:
driver: bridge
backend:
driver: bridge
volumes:
db-data:
*Я ВКЛЮЧИЛ ЧЕТВЕРТУЮ СЛУЖБУ VISUALIZER — ОТЛИЧНЫЙ ИНСТРУМЕНТ РАЗРАБОТКИ, КОТОРЫМ ВИЗУАЛИЗИРУЕТСЯ ЛАНДШАФТ И РАБОТОСПОСОБНОСТЬ СЛУЖБ ВСЕХ УЗЛОВ.
Сосредоточившись только на архитектуре, а не на фактическом коде приложения, я сделал файл Compose довольно простым. Дополняйте его и делайте надежнее для задач своего приложения.
Единственный обязательый параметр развертывания — replicas. Мы также объявили для каждой службы ограничения на размещение: они распределяются только по рабочим узлам. Если бы этого объявления не было, задачи распределялись бы и по управляющему узлу.
Файл Compose готов.
Этап 4. Развертывание стека
Развернуть Swarm-стек очень просто.
Это делается в командной оболочке управляющего узла командой docker stack delpoy с указанием с помощью -c файла Compose. Затем добавляется файл Compose и имя стека swarm_app:
sudo docker stack deploy -c docker-compose.yml stack_name

Вот приложение и развернуто… по крайней мере, для разработки.
Службы в стеке просматриваем этой командой:
sudo docker stack services stack_name

Подробнее все задачи/контейнеры просматриваем этой командой:
sudo docker stack ps stack_name

В выделенной области показана работа Swarm в реальном времени. Похоже, некоторые задачи службы node.js завершились, вероятно, из-за команды sleep, но немедленно заменились запущенной задачей.
Если перейти на любой из общедоступных IP-адресов узла Swarm, мы должны увидеть сайт Apache в реальном времени:

Visualizer
Теперь самое интересное. Перейдем в ту неожиданно появившуюся четвертую службу visualizer, развернутую в управляющем узле с портом 8080 manager_node_public_IP:8080:

Я работаю с пользовательскими интерфейсами, и этот дашборд очень полезен для понимания того, что происходит. С visualizer мы в реальном времени видим контейнеры, распределенные по рабочим узлам.
Смоделируем сбой узла. В консоли управления AWS останавливаем один из серверов рабочего узла и возвращаемся в visualizer:

Поскольку один из узлов стал недоступен, в Swarm задачи перераспределились на другие доступные узлы. При этом количество реплик для каждой службы осталось неизменным.
Поздравляю, мы выполнили оркестрацию и развертывание высокодоступной, отказоустойчивой архитектуры веб-приложения с Docker Swarm.