Attention Mechanism
Laisky Caipublished at: https://t.me/laiskynotes/161
时间线
- 1943 年提出人工神经网络;
- 2014 年发表深度学习(AlexNet);
- 2015 年 Bahdanau 提出 Attention 机制优化 RNN;
- 2015 年 OpenAI 成立;
- 2017 年 Google 发表 Transformer,提出不需要 RNN,只要 Attention 就够了;
- 2017 年 OpenAI 发布基于 transformer 的 gpt-1;
- 2019 年 gpt-2;2020 gpt-3;2022 ChatGPT
可以看出,自从深度学习被提出和广泛应用以来,神经网络的发展就进入了快车道。
RNN
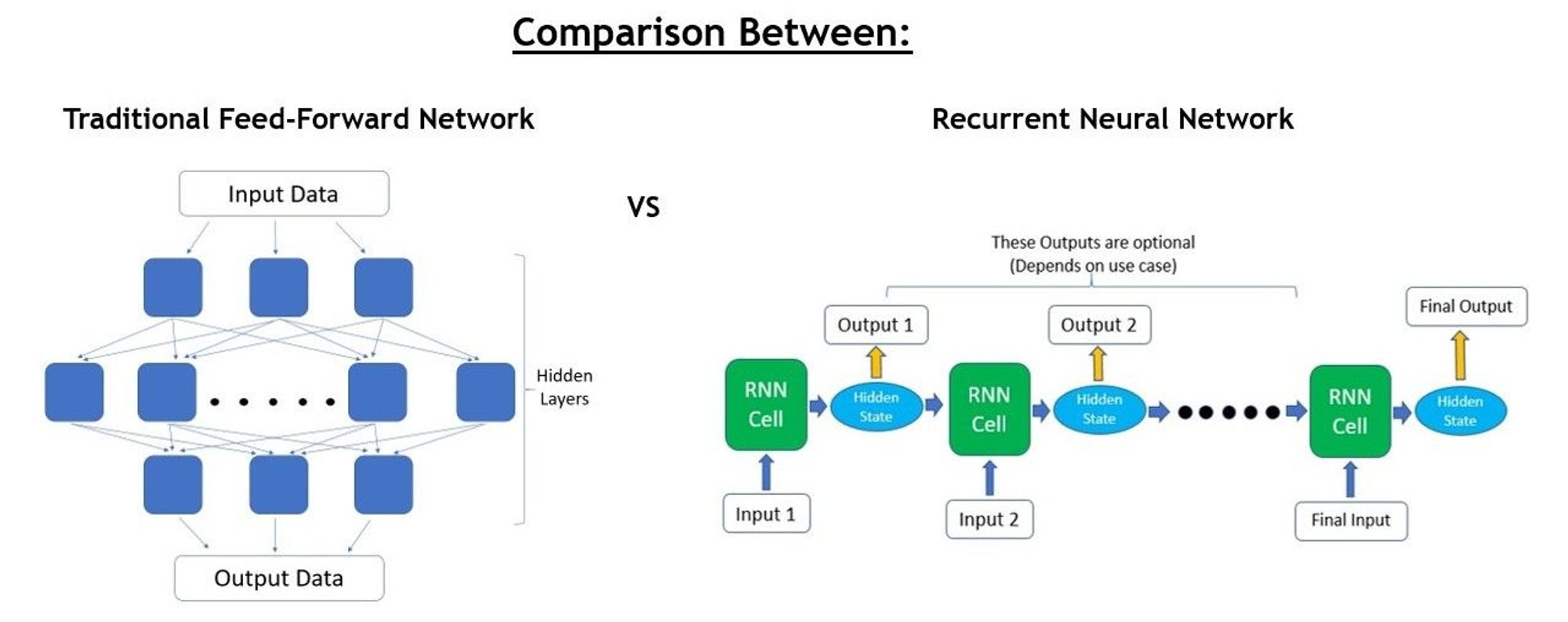
传统神经网络是单向推理,一次输入,一次输出。
RNN 是多轮迭代,计算网络称为 RNN Cell,每次读取输入的一部分(如一个词),推理后得出 output 的一部分和一个中间结果(hidden state)。然后进入下一轮迭代,hidden state 会和 input 融合后作为后续的输入。不断重复这一过程直到全部推理结束。
(某种意义上,这个 hidden state 有点像 n-grams)
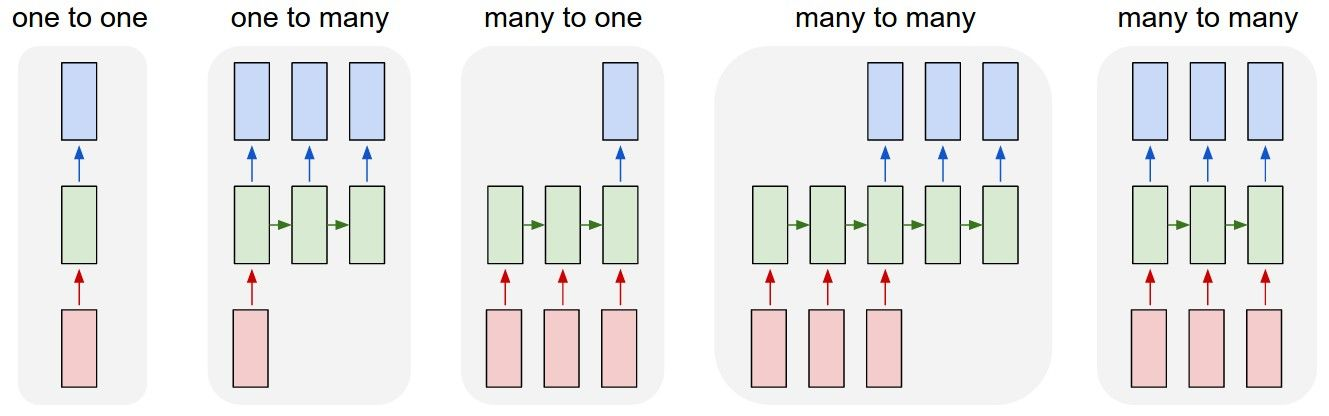
RNN 的 Cell 设计使其输入、输出的长度具有很大的灵活性,可以像普通网络一样单次输入单次输出,也可以多次输入多次输出。而 hidden state 的设计使得每一次输出都可以学习到之前的上下文信息,使其非常适合处理序列问题(sequential problems),如文本翻译。
RNN 的结构也在不断迭代,比如最常见的 seq2seq(专职处理输入的 encoder & 专职处理输出的 decoder)结构,此处略去。
Attention Mechanism
RNN 的缺点是,每一轮的输出,只接收了上一轮的 hidden state,当输入比较长时,RNN Cell 可能会遗忘更早的上下文信息。简而言之,RNN 负责输出的 decoder 缺乏全文上下文意识,而更关注于邻近的前几个词。
2015 年德国科学家 Bahdanau 提出了注意力机制(Attention)。
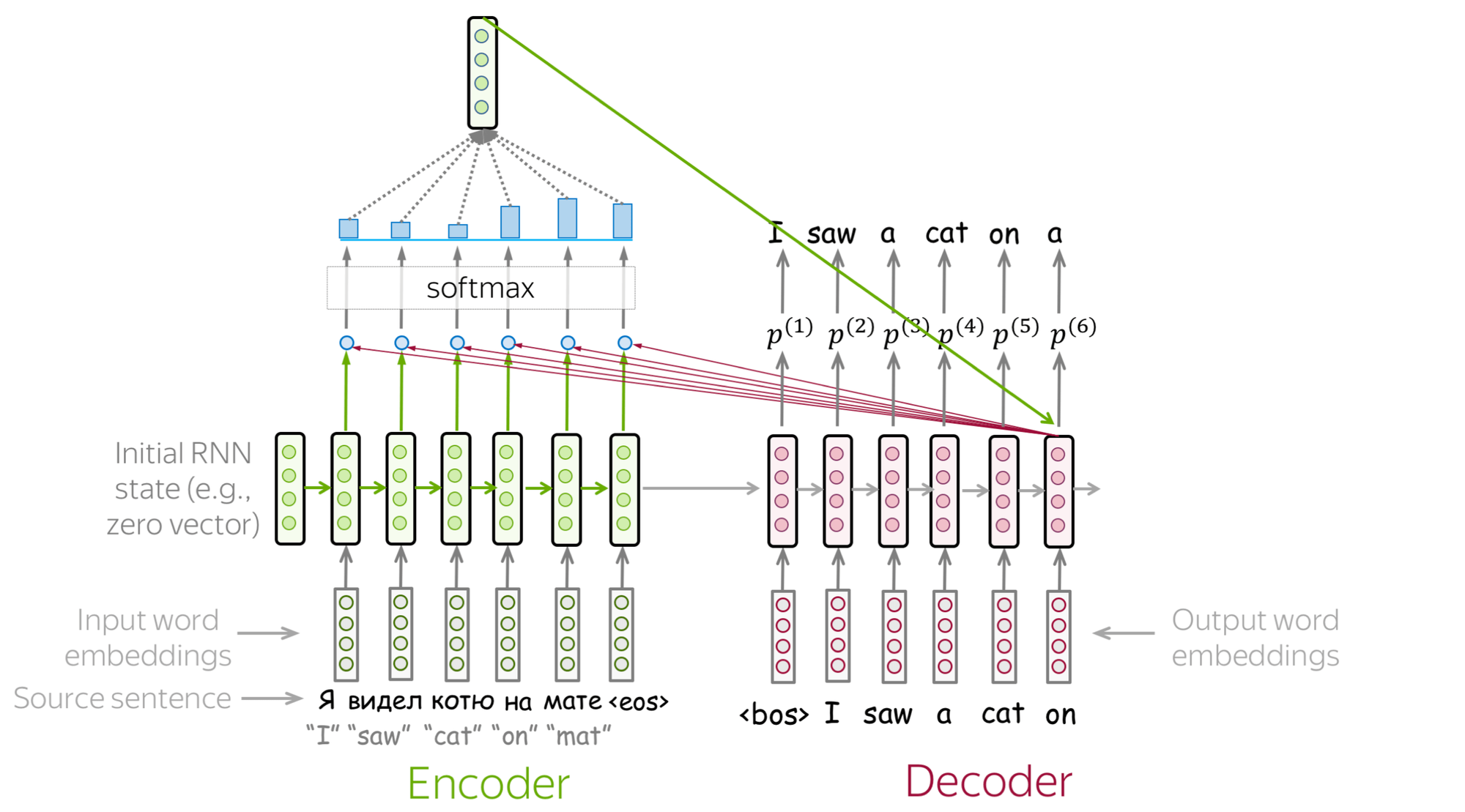
简而言之,attention 就是在 RNN 原来的架构外,给每一个 decoder cell 额外生成了一个 context vector 作为输入,也就是说 decoder cell 在生成 output 时会综合三个信息来源:input(当前词)、hidden state(前几个词) 和 context vector(全文相关信息)。
这个 context vector 就是 attention 的核心,它通过为所有的 input 计算相关权重,然后摘取重要信息(注意力所在)为当前 output 生成量身定做的 context vector,使得 decoder cell 具有了能够纵览全文且选择性专注于任何重点片段的能力。大幅提高了 RNN 处理长文的能力。
Transformer
然而后来 Google 发现,其实根本不需要 RNN,纯粹只靠 attention 就足够了,一系列 attention heads 的组合就可以产生非常好的输出,这就是 transformer。也是那篇著名论文名字的来源《Attention Is All You Need》。
(一个优化 RNN 的东西判了 RNN 死刑,但也不一定,说不定还会反转)
然后就是大家目前所看到的,transformer 力大砖飞,大杀特杀,LLM 如日中天。
但是这条路能走多远?拭目以待吧。