Антипаттерны тестирования ПО. Часть 2
https://habr.com/ru/post/358178/Это часть 2.
Часть 1 читать тут https://telegra.ph/Antipatterny-testirovaniya-PO-CHast-1-07-13
Антипаттерн 5. Тестирование внутренней реализации
Больше тестов — всегда хорошо. Верно?
Неверно! Ещё нужно убедиться, что тесты на самом деле правильно структурированы. Наличие неправильно написанных тестов наносит двойной ущерб:
- Сначала они тратят драгоценное время разработчика при написании.
- Затем они тратят ещё больше времени, когда приходится их переделывать (при добавлении новой функции).
Строго говоря, тестовый код похож на любой другой код. В какой-то момент потребуется рефакторинг, чтобы постепенно его улучшать. Но если вы регулярно меняете существующие тесты при добавлении новых функций, то ваши тесты тестируют не то, что должны.
Я видел, как компании запускают новые проекты и думают, что на этот раз всё сделают правильно — они начинают писать много тестов, чтобы покрыть всю функциональность. Через некоторое время добавляют новую функцию, а для неё нужно изменить несколько существующих тестов. Затем добавляют ещё одну функцию и обновляют ещё больше тестов. Вскоре объём усилий на рефакторинг/исправление существующих тестов фактически превышает время, необходимое для реализации самой функции.
В таких ситуациях некоторые разработчики просто сдаются. Они заявляют, что тесты — пустая трата времени, и отказываются от существующего набора тестов, чтобы полностью сосредоточиться на новых функциях. В некоторых исключительных случаях даже релизы задерживаются из-за непрохождения тестов.
Конечно, здесь проблема в плохом качестве тестов. Если они постоянно нуждаются в рефакторинге, то налицо слишком тесная связь с основным кодом. К сожалению, чтобы выявить такие «неправильно» написанные тесты, требуется определённый опыт.
Изменение большого количества существующих тестов при появлении новой функции — это только симптом. Настоящая проблема в том, что тесты проверяют внутреннюю реализацию, а это всегда сценарий катастрофы. В нескольких руководствах по тестированию ПО делается попытка объяснить эту концепцию, но мало кто демонстрирует её на ясных примерах.
В начале статьи я обещал, что не буду говорить о конкретном языке программирования, и сдержу обещание. Здесь иллюстрации показывают структуру данных вашего любимого языка. Думайте о них как о структурах/объектах/классах, которые содержат поля/значения.
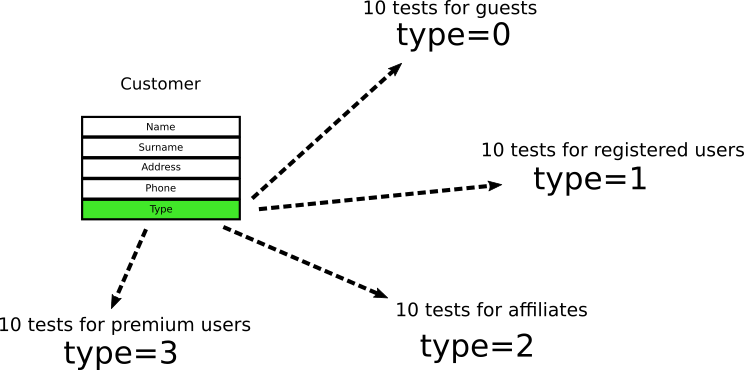
Допустим, объект Customer в приложении интернет-магазина выглядит следующим образом:

Тип Customer принимает только два значения, где 0 означает «гость», а 1 означает «зарегистрированный пользователь». Разработчики смотрят на объект и пишут десять юнит-тестов для проверки «гостей» и десять для «зарегистрированных пользователей». И когда я говорю «для проверки», то имею в виду, что тесты проверяют это конкретное поле в этом конкретном объекте.
Проходит время, и менеджеры принимают решение, что для филиалов необходим новый тип пользователя со значением 2. Разработчики добавляют ещё десять тестов для филиалов. Наконец, добавлен ещё один тип пользователя под названием “premium customer" — и разработчики добавляют ещё десять тестов.
На данный момент у нас 40 тестов в четырёх категориях, и все они проверяют эти конкретные поля. (Числа вымышленные, пример только для демонстрации. В реальном проекте может быть десять взаимосвязанных полей в шести вложенных объектах и 200 тестов).
Если вы опытный разработчик, то можете представить дальнейшее развитие событий. Приходят новые требования:
- Для зарегистрированных пользователей нужно сохранять ещё электронную почту.
- Для пользователей в филиалах нужно сохранять ещё название компании.
- Премиум-пользователям теперь начисляются бонусные баллы.
Объект клиента изменяется следующим образом:
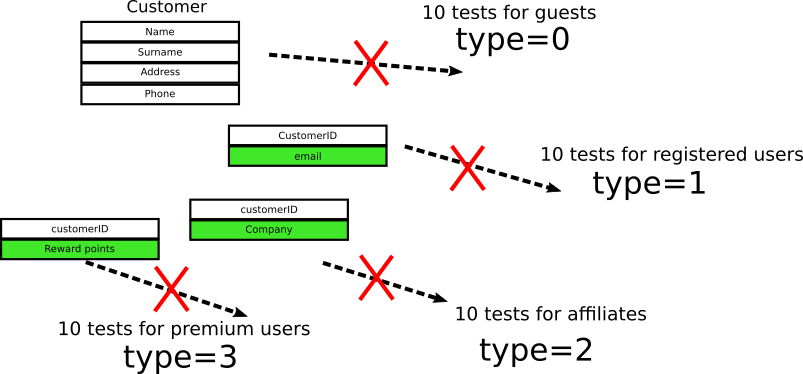
Теперь у нас четыре объекта, связанные с внешними ключами, а все 40 тестов сразу ломаются, потому что проверяемое ими поле больше не существует.
Конечно, в этом тривиальном примере можно просто сохранить существующее поле, чтобы не нарушать обратную совместимость с тестами. В реальном приложении такое не всегда возможно. Иногда обратная совместимость по сути означает, что нужно сохранить и старый, и новый код (до/после новой функции), что сильно раздует его. Также обратите внимание, что сохранение старого кода просто ради юнит-тестов — само по себе явный антипаттерн.
Когда такое происходит в реальной ситуации, разработчики просят дополнительное время на исправление тестов. Затем менеджеры проектов заявляют, что юнит-тесты — пустая трата времени, потому что они мешают внедрению нового функционала. Потом вся команда отказывается от набора тестов, быстро отключив сбойные тесты.
Здесь основная проблема не в тестировании, а в качестве тестов. Вместо внутренней реализации следует тестировать ожидаемое поведение. В нашем простом примере вместо тестирования непосредственно внутренней структуры объекта нужно в каждом случае проверять точное бизнес-требование. Вот как следует реализовать те же тесты:
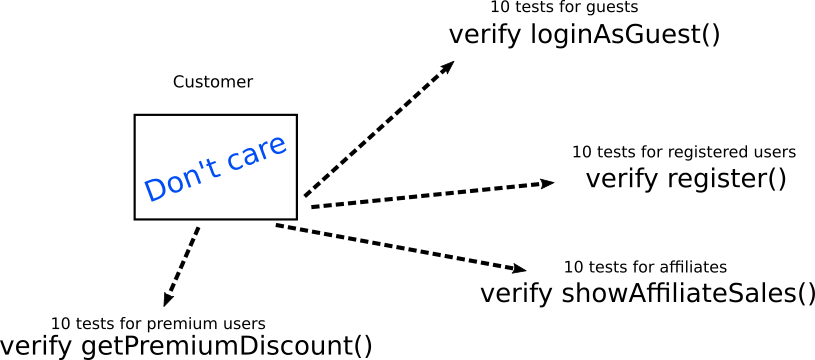
Здесь тесты вообще не проверяют внутреннюю структуру объекта. Они проверяют только его взаимодействие с другими объектами/методами/функциями. Если необходимо, другие объекты/методы/функции следует имитировать. Обратите внимание, что каждый тип теста напрямую соответствует конкретному бизнес-требованию, а не технической реализации (что всегда является хорошей практикой).
При изменении внутренней реализации объекта код верификации тестов остаётся прежним. Может измениться только код настройки для каждого теста, который должен централизованно храниться в одной вспомогательной функции createSampleCustomer() или в чём-то подобном (подробнее см. антипаттерн 9).
Конечно, теоретически сами верифицированные объекты могут измениться. На практике же нереально одновременное изменение loginAsGuest(), register(), showAffiliateSales() и getPremiumDiscount(). В реалистичном сценарии потребуется рефакторинг десяти тестов вместо сорока.
Подводя итог, если вы постоянно исправляете существующие тесты по мере добавления новых функций, это означает, что ваши тесты тесно связаны с внутренней реализацией.
Антипаттерн 6. Чрезмерное внимание покрытию тестами
Покрытие кода — любимая метрика в индустрии. Между разработчиками и менеджерами проектов идут бесконечные дискуссии по поводу необходимого покрытия кода тестами.
Все любят говорить о покрытии, потому что это понятный легко измеримый показатель. В большинстве языков программирования и фреймворков тестирования есть простые инструменты для его отображения.
Позвольте выдать маленький секрет: покрытие кода — совершенно бесполезная метрика. Не существует «правильного» показателя. Это вопрос-ловушка. У вас может быть проект со 100% покрытием кода, в котором по-прежнему остаются баги и проблемы. В реальности нужно следить за другими метриками — хорошо известными показателям CTM (Codepipes Testing Metrics).
Метрики CTM
Вот определение CTM, если вы с ними не знакомы:
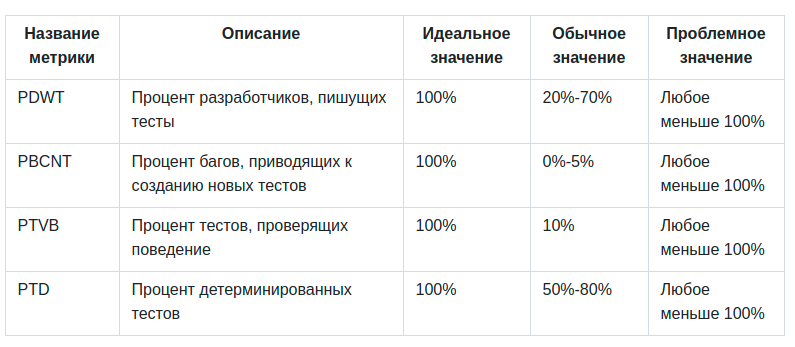
PDWT (процент разработчиков, пишущих тесты) — вероятно, самый важный показатель. Нет смысла говорить об антипаттернах тестирования ПО, если у вас вообще нет тестов. Все разработчики в команде должны писать тесты. Любую новую функцию можно объявлять сделанной только если она сопровождается одним или несколькими тестами.
PBCNT (процент багов, приводящих к созданию новых тестов). Каждый баг в продакшне — отличный повод для написания нового теста, проверяющего соответствующее исправление. Любой баг должен появиться в продакшне не более одного раза. Если ваш проект страдает от появления повторных багов даже после их первоначального «исправления», то команда действительно выиграет от использования этой метрики. Более подробно об этом см. в антипаттерне 10.
PTVB (процент тестов, которые проверяют поведение, а не реализацию). Тесно связанные тесты пожирают массу времени при рефакторинге основного кода. Эта тема уже обсуждалась в антипаттерне 5.
PTD (процент детерминированных тестов от общего числа). Тесты должны завершаться ошибкой только в том случае, если что-то не так с бизнес-кодом. Если тесты периодически ломаются без видимой причины — этой огромная проблема, которая обсуждается в антипаттерне 7.
Если после прочтения о метриках вы по-прежнему настаиваете на установке жёсткого показателя для покрытия кода, я дам вам число 20%. Это число должно использоваться как эмпирическое правило, основанное на законе Парето. 20% вашего кода вызывает 80% ваших ошибок, так что если вы действительно хотите начать писать тесты, то хорошо будет начать в первую очередь с этого кода. Совет также хорошо согласуется с антипаттерном 4, где я предлагаю писать тесты в первую очередь для критического кода.
Не пытайтесь достичь 100% общего покрытия. Это хорошо звучит в теории, но почти всегда является пустой тратой времени:
- вы впустую потратите силы, потому что переход с уровня 80% на 100% гораздо сложнее, чем с 0% до 20%;
- увеличение покрытия кода приводит к уменьшению отдачи.
В любом нетривиальном приложении есть определенные сценарии, для запуска которых требуются сложные юнит-тесты. Усилия, требуемые для написания таких тестов, как правило, перевешивают риск того, что эти сценарии реализуются в продакшне (если это вообще когда-нибудь произойдёт).
Если вы работали с любым большим приложением, то должны знать: после достижения 70% или 80% покрытия становится очень трудно писать полезные тесты для остального кода.
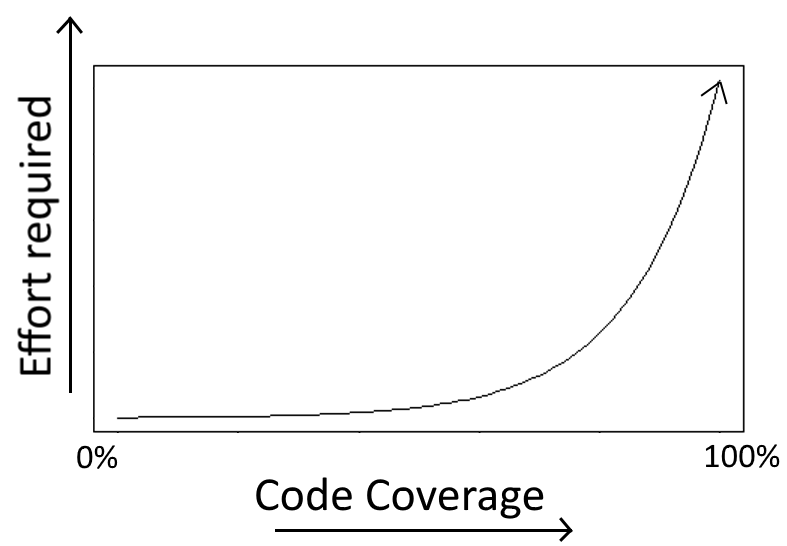
Как мы уже видели в описании антипаттерна 4, некоторые маршруты кода в реальности никогда не сбоят в продакшне, поэтому для них не рекомендуется писать тесты. Лучше потратить время на внедрение фактического функционала.
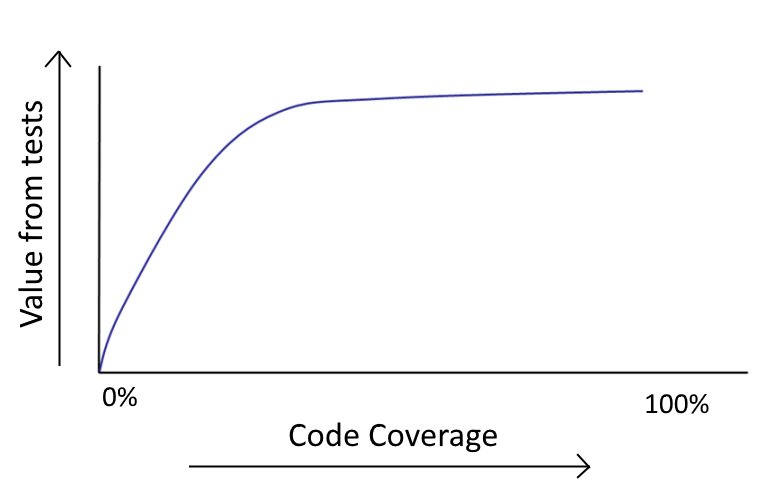
Если для проекта стоит условие определённого процента покрытия кода тестами, то разработчиков обычно заставляют тестировать тривиальный код или писать тесты, которые просто проверяют базовый язык программирования. Это огромная трата времени, и как разработчик вы обязаны пожаловаться руководству на такие необоснованные требования.
Подводя итог, покрытие кода тестами нельзя использовать как показатель качества софтверного проекта.
Антипаттерн 7. Ненадёжные или медленные тесты
Конкретно этот антипаттерн уже неоднократно подробно обсуждался, так что я только дополню.
Поскольку тесты ПО выступают ранним индикатором регрессий, они всегда должны работать надёжно. Провал теста обязан стать причиной беспокойства, а ответственные за соответствующий билд должны начать проверку, почему тест не прошёл.
Этот подход работает только с тестами, которые падают детерминированным образом. Если тест иногда сбоит, а иногда проходит (без каких-либо изменений кода между проверками), то он ненадёжен и дискредитирует всё тестирование. Это наносит двойной ущерб:
- Разработчики больше не доверяют тестам и начинают их игнорировать.
- Сбои даже нормальных тестов становится сложно обнаружить в море недетерминированных результатов.
О неудачном тесте следует чётко информировать всех членов команды, поскольку он меняет статус всей сборки. С другой стороны, при наличии ненадёжных тестов трудно понять, то ли происходят новые сбои, то ли это результат старых ненадёжных тестов.
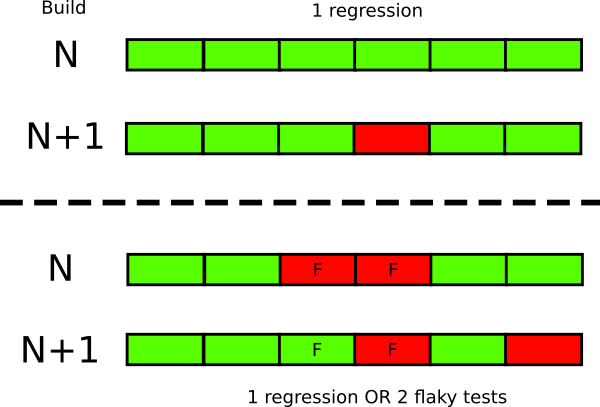
Даже небольшого количества ненадёжных тестов достаточно, чтобы разрушить доверие к остальным. Например, у вас пять ненадёжных тестов, вы прогнали новый билд через тесты и получили три сбоя. Непонятно, всё в порядке или у вас появились три регрессии.
Аналогичная проблема с очень медленными тестами. Разработчикам нужна быстрая обратная связь по результатам каждого коммита (это обсуждается также в следующем разделе), поэтому медленные тесты они в итоге будут игнорировать или вообще не станут запускать.
На практике ненадёжные и медленные тесты почти всегда являются интеграционными и/или тестами пользовательского интерфейса. По мере подъёма по пирамиде тестов вероятность появления ненадёжных тестов значительно возрастает. Известно, что если тест обрабатывает события браузера, то его трудно сделать детерминированным. Источниками ненадёжности могут выступать многие факторы, но обычно виновата среда тестирования и её требования.
Основная защита от ненадёжных и медленных тестов — изолировать их в отдельном наборе тестов (при условии, что они неисправимы). В интернете есть много ресурсов о том, как исправить такие тесты на любом языке программирования, так что нет смысла объяснять это здесь.
Подводя итог, у вас должен быть абсолютно надёжный набор тестов, пусть это будет лишь подмножество всего набора тестов. Если тест из этого набора не проходит, то проблема однозначно с кодом. Любой сбой такого теста означает, что код нельзя пускать в продакшн.
Антипаттерн 8. Запуск тестов вручную
В разных организациях используются разные типы тестов. Юнит-тесты, нагрузочные, тесты приёма пользователей (UAT) — это типичные категории тестовых наборов, которые могут выполняться перед выпуском кода в продакшн.
В идеале все тесты выполняются автоматически без вмешательства человека. Если это невозможно, то хотя бы тесты, которые проверяют корректность кода (т.е. модульные и интеграционные тесты), должны выполняться автоматически. Таким образом, разработчики максимально оперативно получают обратную связь по коду. Функцию очень легко исправить, когда код свеж у вас в голове и вы ещё не переключили контекст на другую функцию.
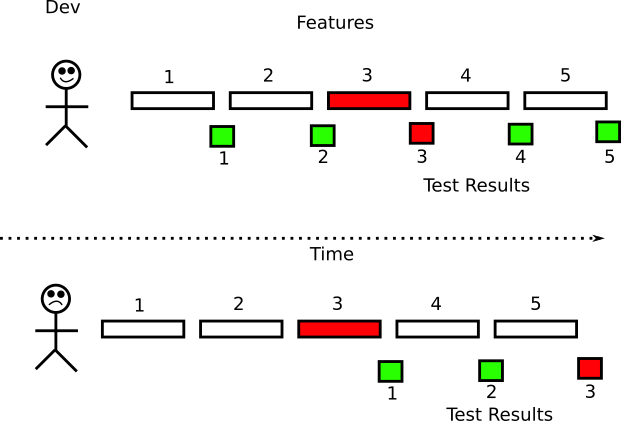
Раньше самым длительным этапом жизненного цикла ПО было развёртывание приложения. В облаке машины создаются по запросу (в виде VM или контейнеров), так что время подготовки новой машины сократилось до нескольких минут или секунд. Такой сдвиг парадигмы застал врасплох многие компании, которые оказались не готовы к столь частым циклам. Большинство существующих практик сосредоточены на длительных циклах выпуска. Ожидать определённого времени релиза с ручной «отмашкой» — одна из устаревших практик, от которых следует отказаться, если компания стремится к быстрым деплоям.
Быстрое развёртывание подразумевает доверие к каждому деплою. Доверие к автоматическому деплою требует высокой степени уверенности в коде. Хотя есть несколько способов получить эту уверенность, но первая линия защиты — ваши тесты ПО. Однако наличие набора тестов с быстрым поиском регрессий — это лишь полдела. Второе необходимое условие — автоматическое выполнение тестов (возможно, после каждого коммита).
Многие компании думают, что у них внедрена непрерывная поставка и/или развёртывание. На самом деле это не так. Практика истинной CI/CD означает, что в любой момент времени существует версия кода, готовая к развёртыванию. Это значит, что релиз-кандидат уже протестирован. Поэтому наличие «готового» пакета, который ещё не получил отмашку — это не настоящая CI/CD.
Большинство компаний поняли, что человеческое участие вызывает ошибки и задержки, но по-прежнему остались компании, где запуск тестов является полуавтоматическим процессом. Под «полуавтоматическим» подразумевается то, что сам набор тестов может быть автоматизирован, но люди выполняют некоторые задачи по обслуживанию, такие как подготовка тестовой среды или очистка тестовых данных по завершению тестов. Это антипаттерн, потому что это не настоящая автоматизация. Все аспекты тестирования должны быть автоматизированы.
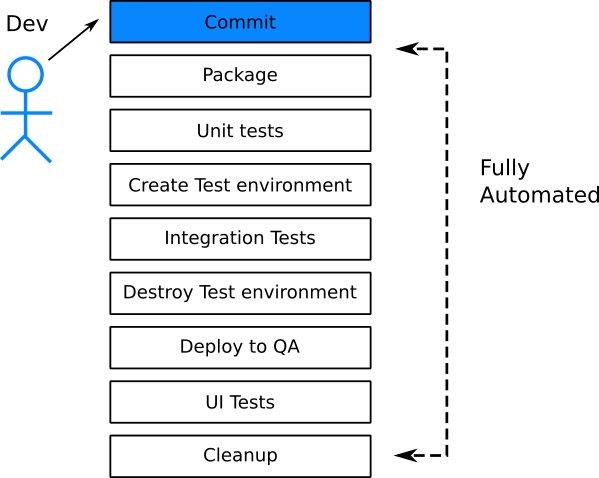
Имея доступ к виртуальным машинам или контейнерам, очень легко по запросу создавать различные тестовые среды. Создание тестовой среды на лету по каждому запросу должно стать стандартной практикой в вашей организации. Это означает, что каждая новая функция тестируется отдельно. Проблемный компонент (т.е. вызывающий сбой тестов) не должен блокировать деплой остальных.
Простой способ понять уровень автоматизации тестирования в компании — понаблюдать за рутинной работой сотрудников отделов QA/тестирования. В идеальном случае тестировщики просто создают новые тесты, которые добавляются в существующий набор. Они не запускают их вручную. Набор тестов выполняется сервером сборки.
Подводя итог, тестирование должно всё время происходить за кулисами. Разработчики узнают результат теста для своей конкретной функции через 5−15 минут после коммита. Тестеры создают новые тесты и проводят рефакторинг существующих тестов, но не запускают их вручную.
Антипаттерн 9. Недостаточное внимание коду теста
Опытный разработчик всегда сначала потратит некоторое время на упорядочивание кода в уме, прежде чем приступать к написанию. Относительно дизайна кода есть несколько принципов, а некоторые из них так важны, что им посвящены даже отдельные статьи в Википедии. Вот некоторые примеры:
Возможно, первый принцип самый важный, поскольку он заставляет установить для кода единственный источник истины, который повторно используется в нескольких функциях. В зависимости от языка программирования вы также можете использовать некоторые другие рекомендации и шаблоны проектирования. Могут быть отдельные рекомендации, принятые специально в вашей команде.
Однако по какой-то неизвестной причине некоторые разработчики не применяют те же принципы к коду тестов ПО. Я видел проекты, где код функций отлично спроектирован, но код тестов страдает от огромных объёмов дублирования, жёстко закодированных переменных, фрагментов копипаста и других ошибок, которые считались бы непростительными в основном коде.
Не имеет смысла рассматривать тестовый код как второсортный, ведь в долгосрочной перспективе весь код нужно обслуживать. В будущем тесты придётся обновлять и перерабатывать. Их переменные и структура изменятся. Если вы пишете тесты, не задумываясь об их дизайне, то создаёте дополнительный технический долг, который добавится к уже существующему в основном коде.
Попробуйте писать тесты с тем же вниманием, которое уделяете коду компонентов. Здесь нужно использовать все те же техники рефакторинга. Для начала:
- Весь код теста должен быть централизованным. Таким же образом все тесты должны выдавать тестовые данные.
- Сложные сегменты верификации следует извлечь в общую для данной области библиотеку.
- Часто используемые имитации и эмуляции не следует копировать копипастом.
- Код инициализации теста должен быть общим для аналогичных тестов.
Если вы используете инструменты статического анализа, форматирования исходного кода или качества кода, настройте их для обработки тестового кода тоже.
Подводя итог, разрабатывайте тесты настолько же тщательно, как и основной код компонента.