AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
https://t.me/reading_ai, @AfeliaN📎 GitHub
🗂️ Project Page
📄 Paper
Main idea
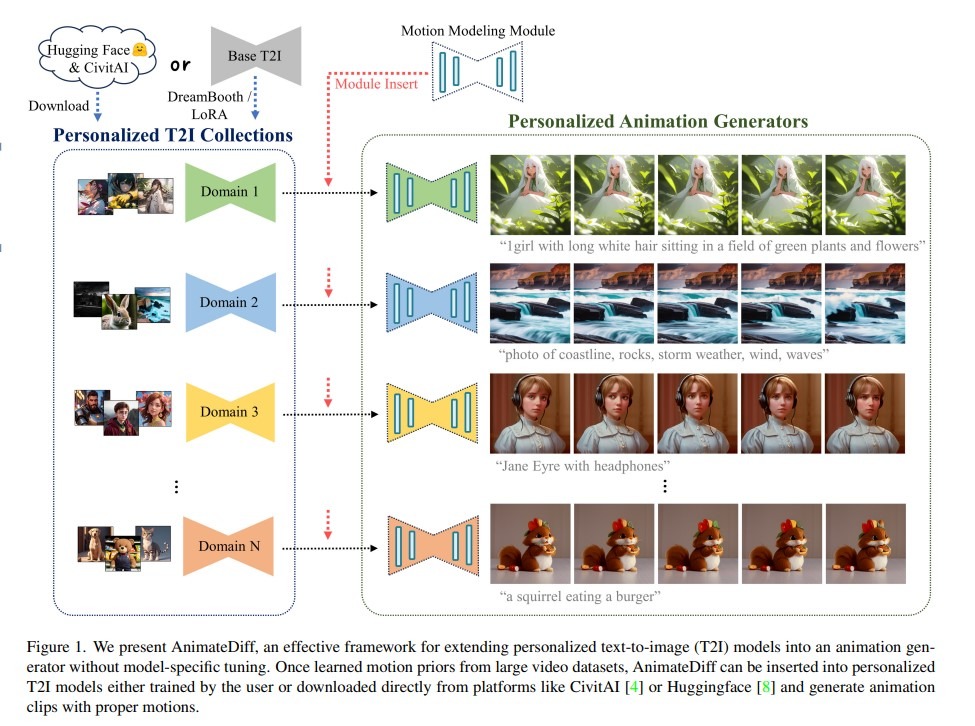
Motivation: Animating a personalized image model usually requires additional tuning with a corresponding video collection. The personalized domains, collecting sufficient personalized videos is costly. Meanwhile, limited data would lead to the knowledge loss of the source domain
Solution: A practical framework to animate most of the existing personalized text-to-image models once and for all. At the core of the framework is to insert a newly initialized motion modeling module into the frozen text-to-image model and train it on video clips to distill reasonable motion priors.
AnimateDiff is able to generate animated images for any personalized T2I model, requiring no model-specific tuning efforts and achieving appealing content consistency over time.
Pipeline

Animating a personalized image model usually requires additional tuning with a corresponding video collection, making it much more challenging. However the authors suggested a method to transform personalized images inot anomation with little training cost while preserving its original domain knowledge and quality. To achieve this goal the generalizable motion modeling module was trained and pluged into the personalized T2I at inference time.
First of all as the original SD can only process image data batches, model inflation is necessary to make it compatible with our motion modeling module, which takes a 5D video tensor in the shape of batch × channels×frames×height×width as input. To achieve this the authors transformed each 2D convolution and attention layer in the original image model into spatialonly pseudo-3D layers by reshaping the frame axis into the batch axis and allowing the network to process each frame independently (the same as in Align your Latents).
To achive the spatial consistency, the authors used the vanilla temporal transformer.

Implementation details
Model: SD 1, SD with LoRA, SD with DreamBooth

Datasets: WebVid-10M
Compated with: Text2Video-Zero,
Results

