Алгоритмы сжатия данных с помощью Java
https://t.me/android_its
Сжатие данных – очень распространенная тема. В интернете мы можем найти множество материалов о ней. Существуют разные тесты для всех видов алгоритмов сжатия. Тесты производительности для Java существуют, но, все они немного устарели, поскольку были написаны давным-давно.
Эффективность сжатия (как производительности, так и размера) зависит от фактических данных. Поэтому для меня имело смысл повторить тесты, чтобы определить, какой алгоритм (если таковой имеется) подойдёт больше всего. Также хотелось просто побольше узнать о сжатии данных в Java.
Какие данные мы сравниваем?
Мы собираемся провести сравнение двух наборов данных: нашей внутренней структуру данных разного размера и набора искусственно сгенерированных случайным образом данных с различными степенями сжатия и размерами.
Внутренняя структура данных – это своего рода trie с URL-адресами, UUID и другой двоичной информацией (закодированной как сообщения protobuf).
Случайный датасеты – это просто рандомные символы из разных наборов. Вот функция для генерации данных:
private static java.util.Random rnd = ...;
private static byte[] generateImpl(
byte[] alphabet,
int length)
{
byte[] result = new byte[length];
for (int i = 0; i < result.length; i++) {
result[i] = alphabet[rnd.nextInt(alphabet.length)];
}
return result;
}
Для разных текстов я рассчитал коэффициенты сжатия и вызвал разные наборы в соответствии с их коэффициентами:
low (1.3) -> "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789" medium (2.1) -> "0123456789" high (3.4) -> "0123" extra high (6.2) -> "01"
Дисклеймер: случайный датасет не является полностью рандомным, как вы можете видеть, для целей сравнения. Это просто нестатический набор данных с более или менее стабильной степенью сжатия.
Алгоритмы сжатия
Я выбрал несколько популярных алгоритмов сжатия:
- gzip через Apache Commons Compress
- deflate также через Commons Compress
- MySQL compression: в основном, он использует алгоритм deflate, а также префиксы с 4 байтами исходной длины данных (что помогает выделить буфер для распаковки). Через java.util.zip.Deflater.
- zstd: алгоритм сжатия Facebook, который предположительно быстрее и имеет лучшую степень сжатия, чем deflate.
- snappy: алгоритм сжатия Google, который был разработан таким образом, чтобы быть очень быстрым при разумных коэффициентах сжатия. Через snappy-java.
- brotli: еще один алгоритм сжатия от Google, который нацелен на лучшую степень сжатия и сопоставимую производительность с deflate. Для brotli мы будем использовать 3 уровня сжатия: 0, 6 и 11 (по умолчанию, максимальный). Используя Brotli4j.
- lz4: алгоритм сжатия, который направлен на достижение наилучшей производительности декодирования. Для lz4 мы будем использовать 3 уровня сжатия: быстрый, 9 (по умолчанию), 17 (максимальный). Через lz4-java.
Степени сжатия
Для реального набора данных лучшую степень сжатия предоставляет brotli, худшую snappy и lz4 fast:

Для случайного датасета лучшую степень сжатия предоставляет brotli, а худшую, неизменно, lz4 fast.
Электронная таблица со всеми коэффициентами сжатия доступна здесь.
Тесты производительности
Тесты были выполнены с использованием JMH для 3 JDK: openjdk-8, openjdk-11 и openjdk-17.
Декодирование реальных данных
Во-первых, давайте посмотрим на производительность декодирования для реальных данных (длина данных составляет от 600 КБ до 4 МБ):

Другим представлением для этой диаграммы была бы пропускная способность в байтах в секунду:

Из этих графиков видно, что lz4 (все 3 уровня) значительно превосходит все остальные алгоритмы. Следующими после lz4 fast являются zstd и snappy.
Кодирование реальных данных
Далее давайте проверим производительность кодирования для реальных данных (длина данных составляет от 600 КБ до 4 МБ):
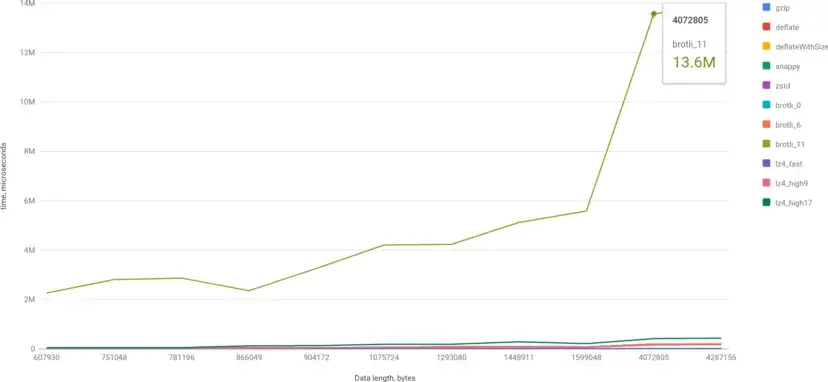
Ух ты! Brotli с 11-м уровнем потребовалось 13 секунд, чтобы закодировать 4 МБ данных… Сначала я не поверил в это, подумал, что, должно быть, неправильно пользуюсь библиотекой. Но потом я запустил оригинальный родной двоичный файл:
$ time brotli ~/1/bins/total_4072805_with_34010_items.bin real 0m12.945s user 0m12.878s sys 0m0.064s
Действительно, 11 уровень сжатия чрезвычайно медленный. Давайте исключим его, чтобы увидеть нормальную работу других алгоритмов:

И соответствующий график пропускной способности (байты в секунду):

Здесь 4 лидера: lz4 fast (500+Мбит/с), brotli_0 (450+Мбит/с), snappy (400+Мбит/с) и zstd (250+Мбит/с). Худший – lz4_high17 с 13-30 Мбит /с.
Сравнение производительности в разных JDK
Сравнивая производительность в разных JDK, мы можем увидеть, что производительность более или менее одинакова, поскольку большинство библиотек используют JNI под капотом:

То же самое и для кодирования:

Сравнение тестов случайного датасета
Несмотря на то, что коэффициенты сжатия в реальном наборе данных разные, в основном они равны 2 и выше, плюс не все данные случайны. Также интересно проверить, как алгоритмы ведут себя при более разных степенях сжатия и большем количестве случайных данных. Итак, давайте проверим производительность рандомных данных при различных степенях сжатия.
lz4 fast vs snappy
Глядя на графики пропускной способности, кажется, что lz4 fast compressor – очень достойная альтернатива snappy, когда степень сжатия не очень важна. Декодирование происходит быстрее:

А теперь кодирование:

Однако, этот тест не учитывает ограничение ввода-вывода системы: пропускная способность сети / диска не бесконечна, поэтому сжатие не будет работать с максимальной производительностью. Я попытался эмулировать ограничение ввода-вывода, но, похоже, у меня это плохо получилось. Поэтому я собираюсь скоро запустить еще один тест…
gzip vs deflate
Gzip и deflate имеют разницу в размерах в 12 байт. Кроме того, gzip использует deflate для сжатия данных. Но между ними есть разница в производительности!

Это очень странно, потому что под капотом как deflate, так и gzip используют классы Inflater/ Deflater из JDK.
deflate vs MySQL Compress
Размер разницы (дополнительные 4 байта) позволяет точно распределять буфер при декодировании, что может сэкономить несколько выделений и копирование памяти. И это то, что мы действительно видим на графике:

Здесь оптимизация действительно очень помогает.
brotli vs gzip
Предполагается, что Brotli является более эффективной заменой deflate / gzip. С точки зрения производительности, Brotli с уровнем сжатия 6, как правило, быстрее, чем gzip / deflate. После определённого размера (в этом тесте где-то между 20K и 30K) Brotli работает значительно лучше:

То же самое касается и кодирования, но там порог еще меньше (около 3K-4K):

Другие интересные детали
Brotli
Существует 3 библиотеки для Java:
- org.brotli:dec: старая библиотека от Google, последнее обновление было в 2017 году.
- com.nixxcode.jvmbrotli:jvmbrotli: тоже старая, обновлена в 2019 году.
- com.aayushatharva.brotli4j:brotli4j: та, которую я использовал при сравнении.
Библиотека dec допускает только декомпрессию. Я решил провести сравнительный анализ, и результаты очень печальные:
Action (algorithm) (ratio) (length) Score Units decode brotli_6 medium 102400 813.029 us/op decode dec medium 102400 2220.280 us/op decode jvmbrotli medium 102400 2644.517 us/op
lz4
lz4 поддерживается в Commons Compress. Краткий тест показал, что он более чем на 1 порядок медленнее, чем org.lz4:lz4-java.
Action (algorithm) (length) Score Units decode lz4_block 62830 726.496 us/op decode lz4_framed 62830 891.120 us/op decode lz4_fast 62830 30.119 us/op decode lz4_high17 62830 22.561 us/op decode lz4_high9 62830 22.075 us/op
Заключение
Несмотря на то, что результаты теста выглядят многообещающими, я не до конца уверен, что увижу такой же уровень производительности в реальном приложении: я кратко упомянул, что ограничение ввода-вывода сети / диска тяжело эмулировать, поэтому трудно предсказать, как оно будет себя вести.
В любом случае,
- lz4 выглядит действительно многообещающе. Я с нетерпением жду возможности сделать с его помощью более полный тест производительности!
- Brotli удивил тем, что по умолчанию он использует максимальное сжатие, которое происходит чрезвычайно медленно. Ещё больше меня удивило то, что скорость декодирования сильно сжатых данных ниже, что делает средний уровень сжатия гораздо лучшим выбором.
- Zstd находится где-то посередине с точки зрения производительности и степени сжатия.
Поиграйте с графиками здесь. Исходный код находится на GitHub.
https://t.me/javatg – изучение java в нашем телеграм канале.