AOS - 1
techworldthinkQ1. Categorize various advanced Operating Systems.
An Operating System performs all the basic tasks like managing files, processes, and memory. Thus operating system acts as the manager of all the resources, i.e. resource manager. Thus, the operating system becomes an interface between user and machine.
Types of Operating Systems: Some widely used operating systems are as follows-
1. Batch Operating System –
This type of operating system does not interact with the computer directly. There is an operator which takes similar jobs having the same requirement and group them into batches. It is the responsibility of the operator to sort jobs with similar needs.
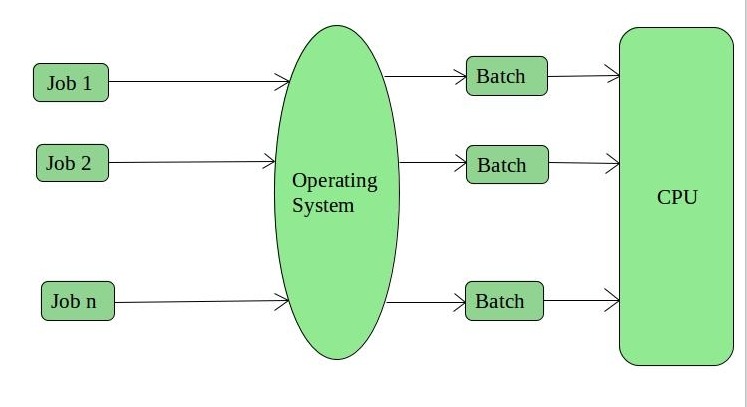
Advantages of Batch Operating System:
- It is very difficult to guess or know the time required for any job to complete. Processors of the batch systems know how long the job would be when it is in queue
- Multiple users can share the batch systems
- The idle time for the batch system is very less
- It is easy to manage large work repeatedly in batch systems
Disadvantages of Batch Operating System:
- The computer operators should be well known with batch systems
- Batch systems are hard to debug
- It is sometimes costly
- The other jobs will have to wait for an unknown time if any job fails
Examples of Batch based Operating System: Payroll System, Bank Statements, etc.
2. Time-Sharing Operating Systems –
Each task is given some time to execute so that all the tasks work smoothly. Each user gets the time of CPU as they use a single system. These systems are also known as Multitasking Systems. The task can be from a single user or different users also. The time that each task gets to execute is called quantum. After this time interval is over OS switches over to the next task.
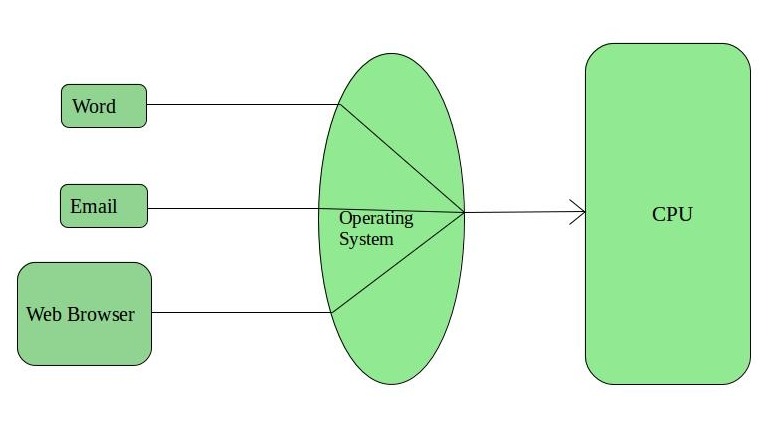
Advantages of Time-Sharing OS:
- Each task gets an equal opportunity
- Fewer chances of duplication of software
- CPU idle time can be reduced
Disadvantages of Time-Sharing OS:
- Reliability problem
- One must have to take care of the security and integrity of user programs and data
- Data communication problem
Examples of Time-Sharing OSs are: Multics, Unix, etc.
3. Distributed Operating System –
These types of the operating system is a recent advancement in the world of computer technology and are being widely accepted all over the world and, that too, with a great pace. Various autonomous interconnected computers communicate with each other using a shared communication network. Independent systems possess their own memory unit and CPU. These are referred to as loosely coupled systems or distributed systems. These system’s processors differ in size and function. The major benefit of working with these types of the operating system is that it is always possible that one user can access the files or software which are not actually present on his system but some other system connected within this network i.e., remote access is enabled within the devices connected in that network.
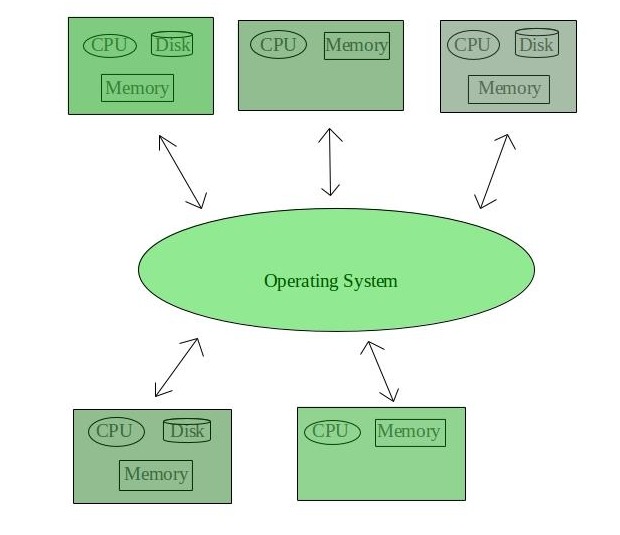
Advantages of Distributed Operating System:
- Failure of one will not affect the other network communication, as all systems are independent from each other
- Electronic mail increases the data exchange speed
- Since resources are being shared, computation is highly fast and durable
- Load on host computer reduces
- These systems are easily scalable as many systems can be easily added to the network
- Delay in data processing reduces
Disadvantages of Distributed Operating System:
- Failure of the main network will stop the entire communication
- To establish distributed systems the language which is used are not well defined yet
- These types of systems are not readily available as they are very expensive. Not only that the underlying software is highly complex and not understood well yet
Examples of Distributed Operating System are- LOCUS, etc.
4. Network Operating System –
These systems run on a server and provide the capability to manage data, users, groups, security, applications, and other networking functions. These types of operating systems allow shared access of files, printers, security, applications, and other networking functions over a small private network. One more important aspect of Network Operating Systems is that all the users are well aware of the underlying configuration, of all other users within the network, their individual connections, etc. and that’s why these computers are popularly known as tightly coupled systems.
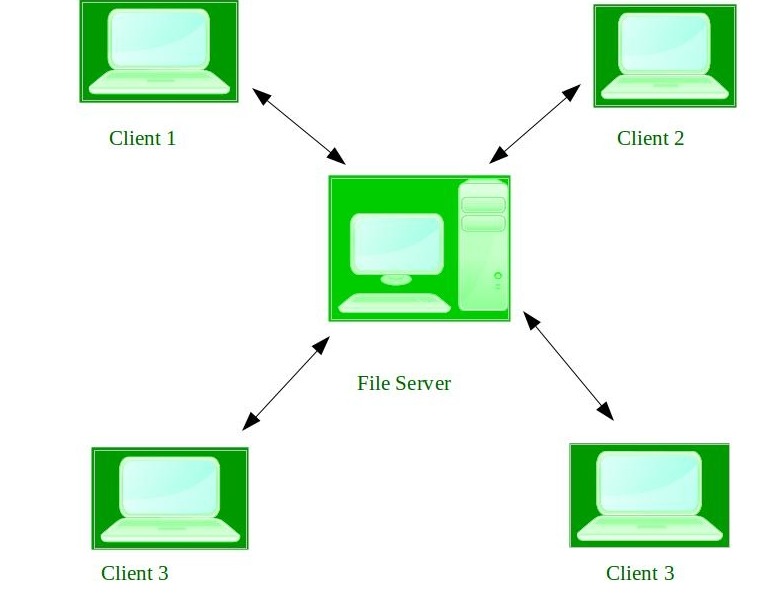
Advantages of Network Operating System:
- Highly stable centralized servers
- Security concerns are handled through servers
- New technologies and hardware up-gradation are easily integrated into the system
- Server access is possible remotely from different locations and types of systems
Disadvantages of Network Operating System:
- Servers are costly
- User has to depend on a central location for most operations
- Maintenance and updates are required regularly
Examples of Network Operating System are: Microsoft Windows Server 2003, Microsoft Windows Server 2008, UNIX, Linux, Mac OS X, Novell NetWare, and BSD, etc.
5. Real-Time Operating System –
These types of OSs serve real-time systems. The time interval required to process and respond to inputs is very small. This time interval is called response time.
Real-time systems are used when there are time requirements that are very strict like missile systems, air traffic control systems, robots, etc.
Two types of Real-Time Operating System which are as follows:
- Hard Real-Time Systems:
- These OSs are meant for applications where time constraints are very strict and even the shortest possible delay is not acceptable. These systems are built for saving life like automatic parachutes or airbags which are required to be readily available in case of any accident. Virtual memory is rarely found in these systems.
- Soft Real-Time Systems:
- These OSs are for applications where for time-constraint is less strict.
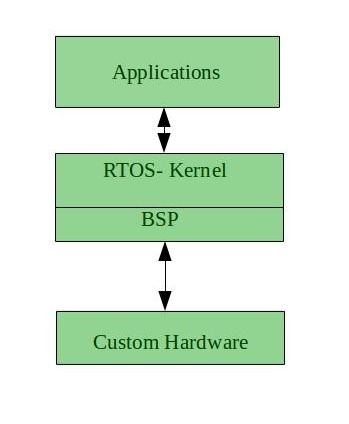
Advantages of RTOS:
- Maximum Consumption: Maximum utilization of devices and system, thus more output from all the resources
- Task Shifting: The time assigned for shifting tasks in these systems are very less. For example, in older systems, it takes about 10 microseconds in shifting one task to another, and in the latest systems, it takes 3 microseconds.
- Focus on Application: Focus on running applications and less importance to applications which are in the queue.
- Real-time operating system in the embedded system: Since the size of programs are small, RTOS can also be used in embedded systems like in transport and others.
- Error Free: These types of systems are error-free.
- Memory Allocation: Memory allocation is best managed in these types of systems.
Disadvantages of RTOS:
- Limited Tasks: Very few tasks run at the same time and their concentration is very less on few applications to avoid errors.
- Use heavy system resources: Sometimes the system resources are not so good and they are expensive as well.
- Complex Algorithms: The algorithms are very complex and difficult for the designer to write on.
- Device driver and interrupt signals: It needs specific device drivers and interrupts signals to respond earliest to interrupts.
- Thread Priority: It is not good to set thread priority as these systems are very less prone to switching tasks.
Examples of Real-Time Operating Systems are: Scientific experiments, medical imaging systems, industrial control systems, weapon systems, robots, air traffic control systems, etc.
Q2. Synchronization using semaphore
Semaphore was proposed by Dijkstra in 1965 which is a very significant technique to manage concurrent processes by using a simple integer value, which is known as a semaphore. Semaphore is simply a variable that is non-negative and shared between threads. This variable is used to solve the critical section problem and to achieve process synchronization in the multiprocessing environment.
Semaphores are of two types:
1. Binary Semaphore –
This is also known as mutex lock. It can have only two values – 0 and 1. Its value is initialized to 1. It is used to implement the solution of critical section problems with multiple processes.
2. Counting Semaphore –
Its value can range over an unrestricted domain. It is used to control access to a resource that has multiple instances.
- Binary Semaphore –
The binary semaphores are like counting semaphores but their value is restricted to 0 and 1. The wait operation only works when the semaphore is 1 and the signal operation succeeds when semaphore is 0. It is sometimes easier to implement binary semaphores than counting semaphores.

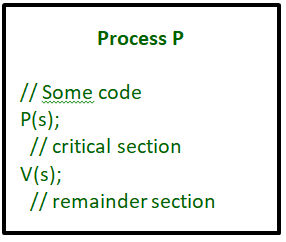
Some point regarding P and V operation
- P operation is also called wait, sleep, or down operation, and V operation is also called signal, wake-up, or up operation.
- Both operations are atomic and semaphore(s) is always initialized to one. Here atomic means that variable on which read, modify and update happens at the same time/moment with no pre-emption i.e. in-between read, modify and update no other operation is performed that may change the variable.
- A critical section is surrounded by both operations to implement process synchronization. See the below image. The critical section of Process P is in between P and V operation.
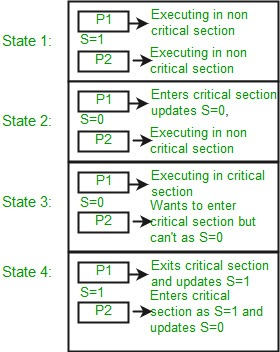
Now, let us see how it implements mutual exclusion. Let there be two processes P1 and P2 and a semaphore s is initialized as 1. Now if suppose P1 enters in its critical section then the value of semaphore s becomes 0. Now if P2 wants to enter its critical section then it will wait until s > 0, this can only happen when P1 finishes its critical section and calls V operation on semaphore s. This way mutual exclusion is achieved. Look at the below image for details which is Binary semaphore.
In counting semaphore, Mutual exclusion was not provided because we has the set of processes which required to execute in the critical section simultaneously.
However, Binary Semaphore strictly provides mutual exclusion. Here, instead of having more than 1 slots available in the critical section, we can only have at most 1 process in the critical section. The semaphore can have only two values, 0 or 1.
struct semaphore {
enum value(0, 1);
// q contains all Process Control Blocks (PCBs)
// corresponding to processes got blocked
// while performing down operation.
Queue<process> q;
}
P(semaphore s){
if (s.value == 1) {
s.value = 0;
}
else {
// add the process to the waiting queue
q.push(P)
sleep();
}
}
V(Semaphore s){
if (s.q is empty) {
s.value = 1;
}
else {
// select a process from waiting queue
Process p=q.pop();
wakeup(p);
}
}
2. Counting Semaphore –
There are the scenarios in which more than one processes need to execute in critical section simultaneously. However, counting semaphore can be used when we need to have more than one process in the critical section at the same time.
In this mechanism, the entry and exit in the critical section are performed on the basis of the value of counting semaphore. The value of counting semaphore at any point of time indicates the maximum number of processes that can enter in the critical section at the same time.
A process which wants to enter in the critical section first decrease the semaphore value by 1 and then check whether it gets negative or not. If it gets negative then the process is pushed in the list of blocked processes (i.e. q) otherwise it gets enter in the critical section.
When a process exits from the critical section, it increases the counting semaphore by 1 and then checks whether it is negative or zero. If it is negative then that means that at least one process is waiting in the blocked state hence, to ensure bounded waiting, the first process among the list of blocked processes will wake up and gets enter in the critical section.
The processes in the blocked list will get waked in the order in which they slept. If the value of counting semaphore is negative then it states the number of processes in the blocked state while if it is positive then it states the number of slots available in the critical section.
struct Semaphore {
int value;
// q contains all Process Control Blocks(PCBs)
// corresponding to processes got blocked
// while performing down operation.
Queue<process> q;
}
P(Semaphore s){
s.value = s.value - 1;
if (s.value < 0) {
// add process to queue
// here p is a process which is currently executing
q.push(p);
block();
}
else
return;
}
V(Semaphore s){
s.value = s.value + 1;
if (s.value <= 0) {
// remove process p from queue
Process p=q.pop();
wakeup(p);
}
else
return;
}
Limitations :
- One of the biggest limitations of semaphore is priority inversion.
- Deadlock, suppose a process is trying to wake up another process which is not in a sleep state. Therefore, a deadlock may block indefinitely.
- The operating system has to keep track of all calls to wait and to signal the semaphore.
Q3. Potential Security Violations
Unauthorized information release. This occurs when an unauthorized person able to read and take advantage of the information stored in a computer system. This also includes the unauthorized use of a computer program.
Unauthorized information modification. This occurs when an unauthorized person is able to alter the information stored in a computer. Examples include changing student grades in a university database and changing account balances in a bank database. Note that an unauthorized person need not read the information before changing it. Blind writes can be performed.
Unauthorized denial of service. An unauthorized person should not succeed in preventing an authorized user from accessing the information stored in a computer. Note that services can be denied to authorized users by some internal actions (like crashing the system by some means, overloading the system, changing the scheduling algorithm) and by external actions (such as setting fire or disrupting electrical supply),
Q4. Explain requirements of mutual exclusion
Mutual exclusion is a concurrency control property which is introduced to prevent race conditions. It is the requirement that a process can not enter its critical section while another concurrent process is currently present or executing in its critical section i.e only one process is allowed to execute the critical section at any given instance of time.
- No Deadlock:
Two or more site should not endlessly wait for any message that will never arrive.
- No Starvation:
Every site who wants to execute critical section should get an opportunity to execute it in finite time. Any site should not wait indefinitely to execute critical section while other site are repeatedly executing critical section
- Fairness:
Each site should get a fair chance to execute critical section. Any request to execute critical section must be executed in the order they are made i.e Critical section execution requests should be executed in the order of their arrival in the system.
- Fault Tolerance:
In case of failure, it should be able to recognize it by itself in order to continue functioning without any disruption.
Q5. Difference Between Load Balancing and Load Sharing in Distributed System
A distributed system is a computing environment in which different components are dispersed among several computers (or other computing devices) connected to a network. These devices broke up the work and coordinated their efforts to do the job faster than if it had been assigned to a single device.
Load Balancing:
Load balancing is the practice of spreading the workload across distributed system nodes in order to optimize resource efficiency and task response time while avoiding a situation in which some nodes are substantially loaded while others are idle or performing little work.
- Load balancing equally distributes network traffic or load across different channels and can be achieved using both static and dynamic load balancing techniques.
- focuses on the notion of traffic dispersion across connections.
- The creation of Ratios, Least connections, Fastest, Round robin, and observed approaches are used in load balancing.
- It is unidirectional.
- no instance is load sharing.
- Accurate Load Balancing is not an easy task.
Load Sharing:
Load balancing solutions are designed to establish a dispersed network in which requests are evenly spread across several servers. Load sharing, on the other hand, includes sending a portion of the traffic to one server and the rest to another.
- Load sharing delivers a portion of the traffic or load to one connection in the network while the remainder is routed through other channels.
- works with the notion of traffic splitting across connections.
- Load Sharing is based on the notion of sharing traffic or network load among connections based on destination IP or MAC address selections.
- it is unidirectional.
- All instances are load sharing.
- Load sharing is easy compared with load balancing.
Load sharing is a more specific phrase that refers to the distribution of traffic across different routes, even if in an uneven manner. If you compare two traffic graphs, the two graphs should be almost same with load balancing, however they may be comparable with load sharing, but the traffic flow pattern will be different.
Q6. Major componants of a load distributing Algorithms.
A distributed scheduler is a resource management component of a distributed operating system that focuses on judiciously and transparently redistributing the load of the system among the individual units to enhance overall performance. Users submit tasks at their host computers for processing. The need for load
distribution arises in such environments because, due to the random arrival of tasks and their random CPU service time requirements, there is a good possibility that several computers are idle or lightly loaded and some others are heavily loaded,
which would degrade the performance. In real life applications there is always a possibility that one server or system is idle while a task is being waited upon at another server.
- Transfer Policy –
Determine whether or not a node is in a suitable state for a task transfer.
- Process Selection Policy –
Determines the task to be transferred.
- Site Location Policy –
Determines the node to which a task should be transferred to when it is selected for transfer.
- Information Policy –
It is in-charge of initiating the gathering of system state data.
Q7. Interconnection network in multiprocessors
• The interconnection network in multiprocessor systems provides data transfer facility between processors and memory modules for memory access.
• The design of the interconnection network is the most crucial hardware issue in the design of multiprocessor systems.
• Generally, circuit switching is used to establish a connection between processors and memory modules.
• During a data transfer, a dedicated path exists between the processor and the memory module.
• Types of interconnection networks include:
Bus
Cross-bar Switch
Multistage Interconnection Network
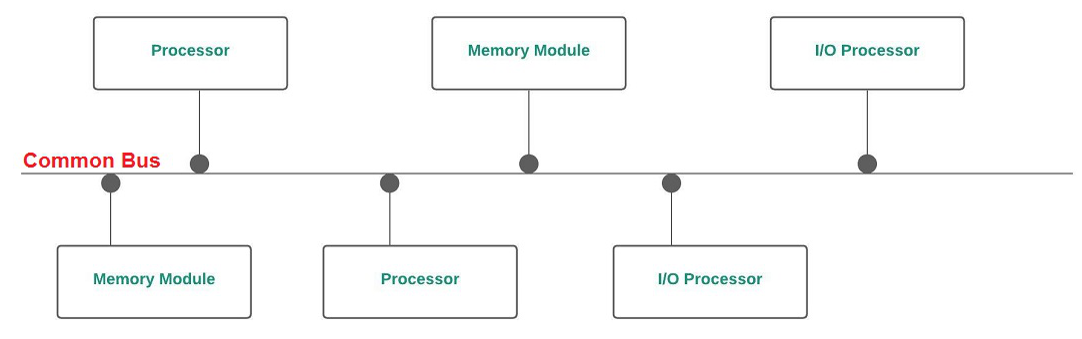
- Bus
• Processors are connected to memory module via a bus.
• Simplest multiprocessor architecture. Less Expensive.
• Can only support a limited number of processors because of limited bandwidth.
• This problem can be avoided by using multiple buses.
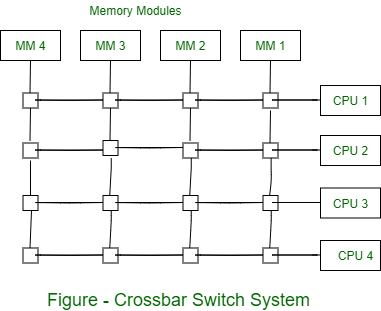
2. Cross-bar Switch
• It is a matrix or grid structure that has a switch at every cross-point.
• A cross-bar is capable of providing an exclusive connection between any processor-memory pair.
• All n processors can concurrently access memory modules provided that each processor is accessing a different memory module.
• A cross bar switch does not face contention at the interconnection network level.
•A contention can occur only at the memory module level.
• Cross-bar based multiprocessor systems are relatively expensive and have limited scalability because of the quadratic growth of the number of switches with the system size. (nxn if there ae n processors and n memory modules).
• Crossbar needs N2 switches for fully connected network between processors and memory.
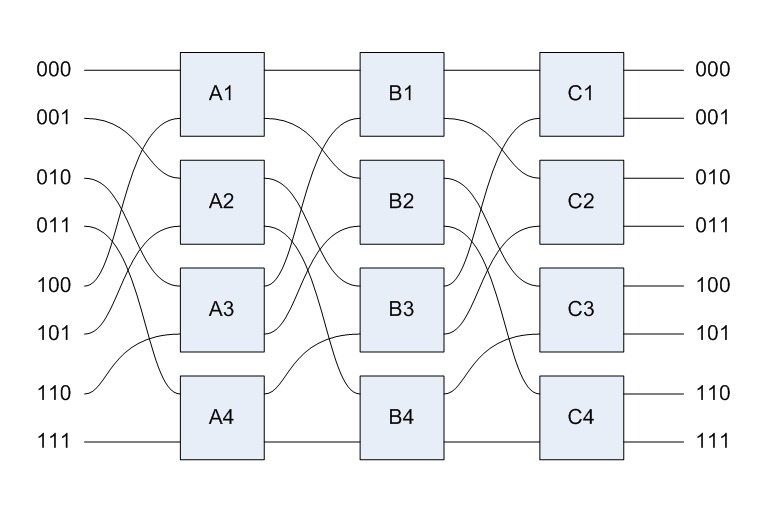
3. Multistage Interconnection Network
• It is a compromise between a bus and a cross-bar switch.
• A multistage interconnection network permits simultaneous connections between several processor-memory pairs and is more cost-effective than a cross-bar.
• A typical multistage interconnection network consists of several stages of switches.
• Each stage consists of an equal number of cross-bar switches of the same size.
• The outputs of the switches in a stage is connected to the inputs of the switches in the next stage.
• These connection are made in such a away that any input to the network can be connected to any output of the network.
• Depending upon how output-input connections between adjacent stages are made, there are numerous types of interconnection network.
• An N x N multistage interconnection network can connect N processors to N memory modules.
• In multistage switch based system all inputs are connected to all outputs in such a way that no two-processor attempt to access the same memory at the same time.
• But the problem of contention, at a switch, arises when some memory modules are contested by some fixed processor.
• In this situation only one request is allowed to access and rest of the requests are dropped.
• The processor whose requests were dropped can retry the request or if buffers are attached with each switch the rejected request is forwarded by buffer automatically for transmission.
• This Multistage interconnection networks also called store-and-forward networks.
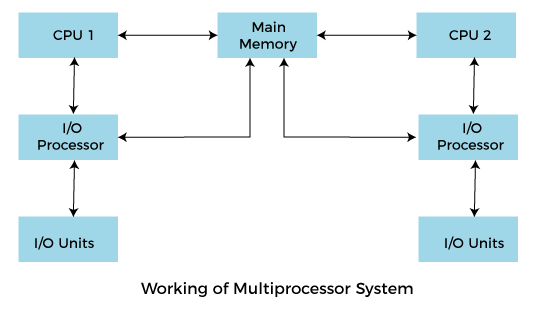
Q8. Structure of Multiprocessing Operating system
In operating systems, to improve the performance of more than one CPU can be used within one computer system called Multiprocessor operating system.
Multiple CPUs are interconnected so that a job can be divided among them for faster execution. When a job finishes, results from all CPUs are collected and compiled to give the final output. Jobs needed to share main memory and they may also share other system resources among themselves. Multiple CPUs can also be used to run multiple jobs simultaneously.
For Example: UNIX Operating system is one of the most widely used multiprocessing systems.
To employ a multiprocessing operating system effectively, the computer system must have the following things:
- A motherboard is capable of handling multiple processors in a multiprocessing operating system.
- Processors are also capable of being used in a multiprocessing system.
1) Separate supervisor
• In separate supervisor system each process behaves independently.
• Each system has its own operating system which manages local input/output devices, file system and memory well as keeps its own copy of kernel, supervisor and data structures, whereas some common data structures also exist for communication between processors.
• The access protection is maintained, between processor, by using some synchronization mechanism like semaphores.
• Such architecture will face the following problems:
1) Little coupling among processors.
2) Parallel execution of single task.
3) During process failure it degrades.
4) Inefficient configuration as the problem of replication arises between supervisor/kernel/data structure code and each processor.
2) Master-slave
• In master-slave, out of many processors one processor behaves as a master whereas others behave as slaves.
• The master processor is dedicated to executing the operating system. It works as scheduler and controller over slave processors. It schedules the work and also controls the activity of the slaves.
• Therefore, usually data structures are stored in its private memory.
• Slave processors are often identified and work only as a schedulable pool of resources, in other words, the slave processors execute application programmes.
• This arrangement allows the parallel execution of a single task by allocating several subtasks to multiple processors concurrently.
• Since the operating system is executed by only master processors this system is relatively simple to develop and efficient to use.
• Limited scalability is the main limitation of this system, because the master processor become a bottleneck and will consequently fail to fully utilise slave processors.
3) Symmetric
• In symmetric organisation all processors configuration are identical.
• All processors are autonomous and are treated equally.
• To make all the processors functionally identical, all the resources are pooled and are available to them.
• This operating system is also symmetric as any processor may execute it. In other words there is one copy of kernel that can be executed by all processors concurrently.
• To that end, the whole process is needed to be controlled for proper interlocks for accessing scarce data structure and pooled resources.
• The simplest way to achieve this is to treat the entire operating system as a critical section and allow only one processor to execute the operating system at one time.
• This method is called ‘floating master’ method because in spite of the presence of many processors only one operating system exists.
• The processor that executes the operating system has a special role and acts as a master.
• As the operating system is not bound to any specific processor, therefore, it floats from one processor to another.
• Parallel execution of different applications is achieved by maintaining a queue of ready processors in shared memory.
• Processor allocation is then reduced to assigning the first ready process to first available processor until either all processors are busy or the queue is emptied.
• Therefore, each idled processor fetches the next work item from the queue.
Q9. What is the term serializability in DBMS?
Serial schedule both by definition and execution means that the transactions bestowed upon it will take place serially, that is, one after the other. This leaves no place for inconsistency within the database. But, when a set of transactions are scheduled non-serially, they are interleaved leading to the problem of concurrency within the database. Non-serial schedules do not wait for one transaction to complete for the other one to begin. Serializability in DBMS decides if an interleaved non-serial schedule is serializable or not.
• The transactions are set of instructions and these instructions perform operations on database.
• When multiple transactions are running concurrently then there needs to be a sequence in which the operations are performed because at a time only one operation can be performed on the database.
• This sequence of operations is known as Schedule.
• When multiple transactions are running concurrently then there is a possibility that the database may be left in an inconsistent state.
• Serializability is a concept that helps us to check which Schedules are serializable.
• A serializable schedule is the one that always leaves the database in consistent state.
• Execution of a transaction is modeled by a log and the correctness condition is stated in terms of logs.
Q10. log equavalence in serializability
Intuitively, two logs are equivalent if the executions that produced them leave the database in the same state. The formal definition of equivalence is:Two logs are equivalent if and only if:
- Each read operation reads from the same write operation in both logs, and
- Both logs have the same final writes.
We say a read operation j reads from a write operation i if read operation j reads a value most recently written by write operation i. The final write of a log is the log's last write operation.