A Deep Probabilistic Model for Customer Lifetime Value Prediction
Artem ErokhinХорошая статья 2019 года + разбор (я бы даже сказал, что одна из лучших статей, которые прочитал про LTV). Авторы представляют новую функцию потерь, чтобы учитывать минусы типичного процесса решения задачи предсказания LTV. Что ж, давайте разбираться, что интересного придумали авторы.
Начнем со стандартного процесса и проблем с предсказанием LTV. В посте про модели выживаемости, я писал, что задачу можно представить в виде двух проблем: классификации - “выживет” ли пользователь и моделирования суммы покупок посредством регрессии.
Тут возникает некоторое количество проблем:
- Задачи решаются независимо. Потому у нас не используется часть информации при решении общей для нас задачи - моделирования “выживания” и размера покупок;
- Распределение размера покупок очень скошено из-за большого числа нулей среди пользователей, а также из-за небольшого числа т.н. “китов”, которые тратят очень много денег. Это сильно влияет на типичную функцию ошибок для задачи регрессии - mean squared error (MSE). Например, MSE будет больше штрафовать за ошибки много покупающих пользователей, а также может быть нестабильной при наличии выбросов в данных.
В принципе, вторую проблему можно исправить использованием квантильной регрессии. Но проблема в том, что мы уже оцениваем не среднее значение, а некие квантили нашего LTV. И среднее нам все же может быть нужно, ибо воспринимать его бизнесу проще.
Соответственно, нужно что-то делать первой проблемой.
Что же можно сделать? Давайте попробуем решить обе проблемы разом. Со второй проблемой можно справиться, изменив функцию потерь с MSE на что-то другое. Авторы предлагают Lognormal loss, то есть перейти к использованию логнормального распределения. Такой вид распределения выглядит куда более подходящим, применительно к LTV, т.к. значения начинаются в нуле и уходят в бесконечность, плюс есть скошенность в правую сторону. Так что, давайте будем оценивать параметры этого распределения (mu и sigma). И применять отличную от MSE функцию потерь. Правда, стоит отметить, что предложенный авторами вариант создает некоторое смещение (bias) в сторону предсказания больших значений, но если мы хотим поправить сильный штраф, который дает MSE на больших значениях, то это небольшая цена.

Первую проблему мы исправим тем, что сделаем multitask задачу. То есть будем сразу учить параметры mu и sigma из логнормального распределения и вероятность возвращения пользователя p. Совместить функции потерь достаточно несложно - авторы предлагают учитывать их в равной степени, то есть использовать итоговый ZILN loss = BCE loss + Lognormal loss, где BCE loss - это просто binary cross entropy (бинарная кросс-энтропия).

В итоге, получаем, что мы учимся решать сразу две задачи (классификация и регрессия), учитывая особенности наших данных. Для реализации авторы предлагают использовать глубокую нейронную сеть с вышеуказанной функцией потерь (в основном, из-за удобства использования и хороших результатов на различных иных задачах).
Для сравнения с другими подходами используют: коэффициент Джини (насколько хорошо мы разделяем группы пользователей), корреляцию Спирмена между реальными значениями и предсказаниями (в основном, для большей устойчивости к выбросам) и mean absolute percentage error (MAPE) для децилей значений пользователей.
Про последнее немного подробнее. Суть в том, чтобы оценить калибровку модели - то есть оценить, есть ли смещение к какому либо хвосту (например, предсказывать меньшие значения для групп с небольшими реальными LTV и большие - для групп с большими). Мы делим выборку на децили, усредняем значения LTV, потом строим MAPE между предсказаниями и фактом на этих 10 числах. Так и оцениваем качество калибровки.
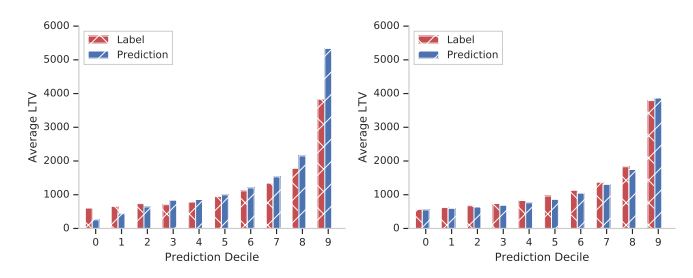
В итоге, авторы указывают, что подход с ZILN loss работает хорошо, метрики почти всегда лучше. Плюс, еще приводят код (что совсем хорошо).
Мои выводы:
- Интересная идея совмещения двух задач в одну;
- Любопытные метрики для сравнения результатов. Стоит взять их на вооружение при работе с LTV;
- Хорошая и понятная статья. Все по полочкам. Даже захотелось попробовать где-нибудь применить и посмотреть на результаты на своих задачах.