SQL-запросы, о которых должен знать каждый дата-инженер. Гайд по по работе с SQL в Data Science.
https://t.me/data_analysis_mlЗнание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
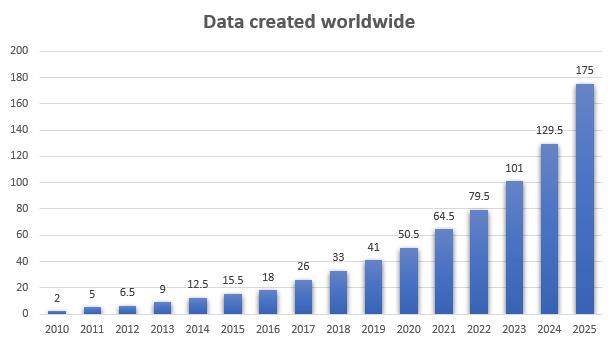
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Я и сам дата-инженер, давно использую SQL и знаю, как важно быстрее писать сложные запросы. И продвинутый синтаксис SQL будет здесь очень кстати.
В примерах использованы данные таблицы bill («Счет»):

Нарастающий итог
На практике часто приходится подсчитывать нарастающий итог по таблице, т. е. как меняется промежуточная сумма каждый раз при добавлении нового значения.
Нарастающим итогом называется сумма значений во всех ячейках столбца до следующей ячейки в этом конкретном столбце.
Вот запрос на эту сумму:
SELECT id,month , Amount , SUM(Amount) OVER (ORDER BY id) as total_sum FROM bill
А вот как будет выглядеть результат:

Обобщенные табличные выражения
Обобщенные табличные выражения используются ради большего удобства для восприятия человеком сложных запросов, требующих соединения, и подзапросов.
Фактически это временный именованный результирующий набор данных, на который можно ссылаться внутри оператора SELECT, INSERT, UPDATE или DELETE.
Рассмотрим простой запрос:
SELECT * FROM bill WHERE id in (SELECT DISTINCT id FROM id WHERE country = "US" AND status = "Y" )
Представьте, что мы задействуем этот подзапрос многократно в последующем запросе. Не проще ли использовать его как временную таблицу? Именно эту задачу и решают обобщенные табличные выражения.
WITH idtempp as ( SELECT id as id FROM id WHERE country = "US" AND status = "Y" ) SELECT * FROM bill WHERE id in (SELECT id from idtempp)
Упорядочение данных
Дата-инженерам и аналитикам данных очень часто приходится упорядочивать значения по каким-либо параметрам, например зарплате, затратам и т. д. И это экономит много времени при поиске точного запроса.
SELECT id, Amount, RANK() OVER (ORDER BY Amount desc) FROM bill
В этом запросе набор данных упорядочен по столбце amount («Сумма»).
Вместо RANK() используется также DENSE_RANK(). Он аналогичен, но не пропускает следующее по порядку значение, если у двух строк одинаковое значение.
Добавление подытогов
Наличие промежуточного итога (подытога) помогает оценить данные в контексте общего итога.
Это расширенная версия оператора GROUP BY: здесь есть возможность добавления к данным промежуточных и общих итогов.
SELECT Type, id, SUM (Amount) AS total_amount FROM bill GROUP BY Type,id WITH ROLLUP

Примечание: это запрос в MySQL. Для других синтаксис свертки может отличаться.
Здесь в запросе строка со значениями null и для типа, и для идентификатора — это итог. Есть также подытоги со значениями null только в столбце идентификатора: это 4-я и предпоследняя строки.
Временные функции
Временные функции позволяют легко менять данные без использования огромных операторов case.
В следующем примере временная функция применяется для преобразования типа в род. Это можно было сделать с помощью встроенного в запрос оператора case, но тогда было бы неудобно читать.
CREATE TEMPORARY FUNCTION get_gender(type varchar) AS (
CASE WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
)
SELECT
name,
get_gender(Type) as gender
FROM bill
Дисперсия и среднеквадратическое отклонение
Для получения этих значений есть специальные агрегатные функции: VARIANCE, VAR_POP и VAR_SAMP. Они группируют данные и используются для определения дисперсии, дисперсии группы и дисперсии выборки набора данных по отдельности.
SELECT VARIANCE(amount) AS var_amount, VAR_POP(amount) AS var_pop_amount, VAR_SAMP(amount) AS var_samp_amount, STDDEV_SAMP(amount) as stddev_sample_amount, STDDEV_POP(amount) as stddev_pop_amount, FROM bill
VAR_POP — дисперсия совокупности;
VAR_SAMP — дисперсия выборки;
STDDEV_SAMP — среднеквадратическое отклонение для выборки;
STDDEV_POP — среднеквадратическое отклонение для совокупности.
Это были основные SQL-команды, которые я постоянно использовал, работая дата-инженером, и которые пришлись очень кстати при решении многих бизнес-задач.
Stats подтверждает, что экосистема инструментов SQL, которая включает в себя все: от Excel и Tableau до SparkSQL — используется в более чем 60 % организаций. Это настоящий подвиг для SQL, особенно учитывая его возраст.
https://t.me/ai_machinelearning_big_data
Полный гайд по работе с SQL в Data Science
Настройка базы данных MySQL
Настроить базу данных MySQL очень просто. Загрузите исполняемый файл на Mac или ПК и запустите установку. Затем подключитесь к серверу, используя клиент MySQL. Вот инструкции.
Создание таблиц
Следующий запрос создаёт таблицу с первичным ключом.
Получение данных из таблиц
Этот запрос извлекает данные из одной таблицы.
Следующий запрос извлекает данные из двух таблиц путём внутреннего объединения. Выходными данными будут все совпадающие записи из таблиц ClientInfo и ClientAddress.
А такой запрос извлекает данные из двух таблиц с помощью неявного обозначения «внутреннего» объединения.
Выходные данные будут такими же, как и раньше.
Следующий запрос извлекает данные из двух таблиц с помощью внешнего объединения.
В результате получаем все записи ClientInfo + совпадение таблиц ClientInfo и ClientAddress.
Создание индексов
Создадим уникальный индекс для таблицы с помощью следующего запроса:
Теперь, когда у вас сложилось представление о том, как взаимодействовать с SQL и получать информацию из таблиц, перейдём к примеру для Data Science.
SQl + Google BigQuery
С помощью SQL специалисты в Data Science предварительно обрабатывают информацию и решают вопросы машинного обучения. Дальнейший код будет на Python. Для достижения высокой скорости обработки больших наборов данных воспользуемся хранилищем корпоративных данных Google BigQuery.
В онлайн-среде Kaggle для работы с Jupyter Notebooks активируйте Google BigQuery. Вам будут доступны ежемесячные бесплатные 5 терабайт на использование веб-сервиса BigQuery. Если объём закончится раньше, подождите следующего месяца.
Для использования BigQuery зарегистрируйте бесплатный аккаунт Google Cloud Platform и создайте экземпляр проекта в Google-сервисе. Смотрите руководство по началу работы.
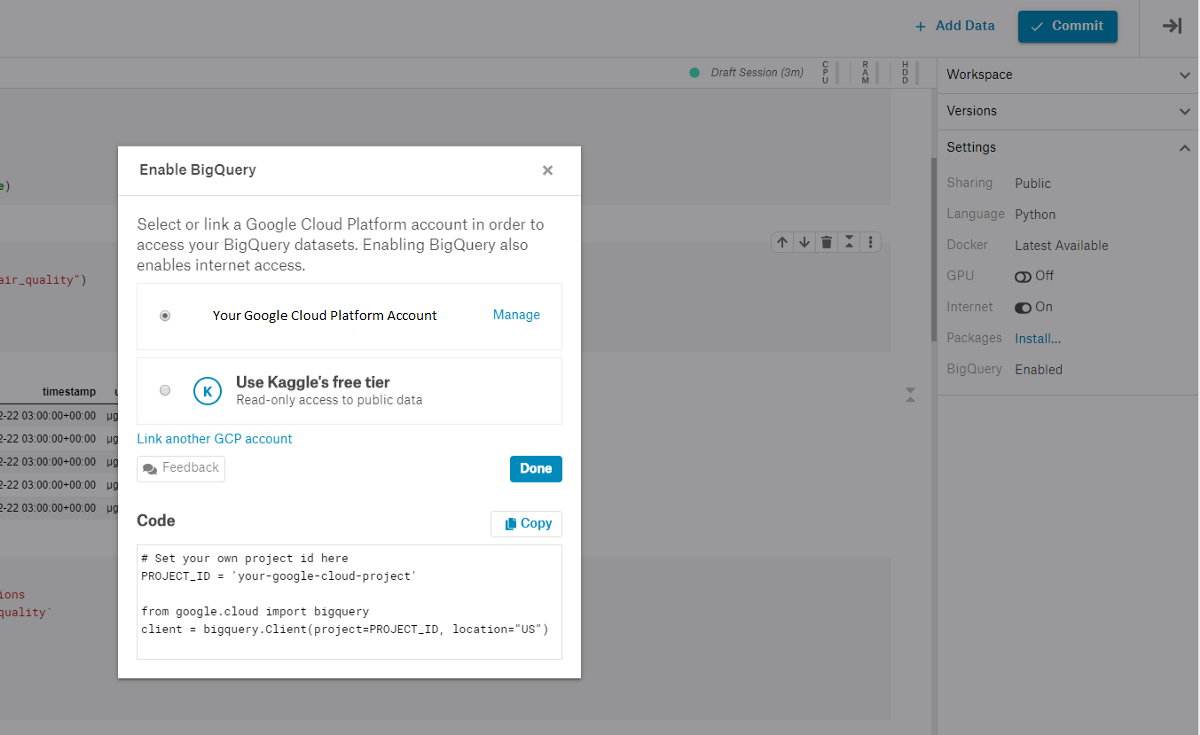
После создания проекта BigQuery в учётной записи вы получите идентификатор, который понадобится, чтобы связать BigQuery с ядром Kaggle. Для этого запустите код:
В примере используется набор данных OpenAQ, который содержит информацию о качестве воздуха в мире.

Подготовка данных
Посмотрим, какие SQL-запросы используются для предобработки данных.
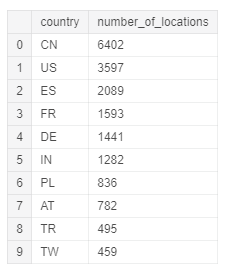
Начнём с определения количества городов в стране, где измерялось качество воздуха. С помощью SQL выбираем столбец country и подсчитываем все отличающиеся значения столбца location. Для удобства сделаем группировку по стране и убывающий порядок.
Так выглядят первые десять результирующих записей:
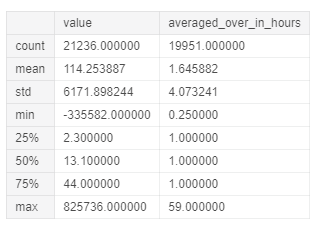
Исследуем статистические характеристики столбцов value и averaged_over_in_hours в единицах измерения µg/m³. Это послужит быстрой проверкой на аномалии.
В столбце value хранится последнее измеренное значение для загрязнителей, а в averaged_over_in_hours – время усреднения значения в часах.
Чтобы подвести итог нашего анализа, определим среднее количество озона в каждой стране. Для наглядности построим гистограмму с использованием Matplotlib.
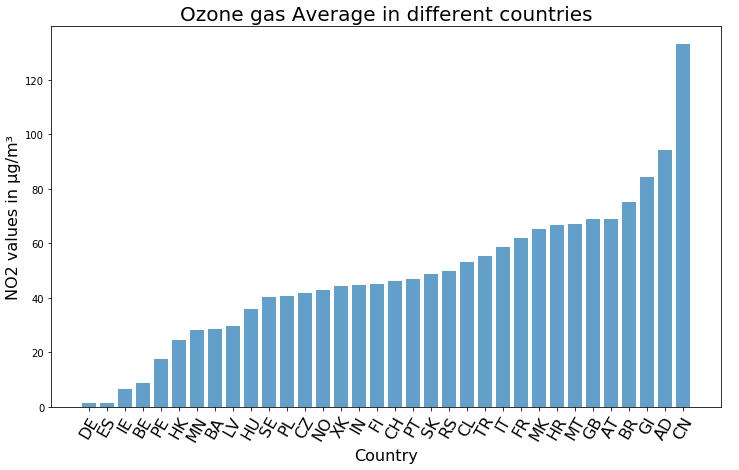
SQL + Machine Learning
Для создания моделей машинного обучения с применением SQL используется Google BigQuery ML. Сервис снижает порог вхождения в Machine Learning и ускоряет процесс благодаря отсутствию перемещения информации.
BigQuery ML избавляет нас от чтения данных в локальной памяти и метания между несколькими языками программирования. Наша модель готова к работе прямо после тренировки.
BigQuery ML поддерживает массу моделей машинного обучения: от линейной и логистической регрессий до метода k-средних и работы с предобученными моделями TensorFlow.
В первую очередь импортируем требуемые зависимости. И добавим команду BigQuery для читабельности.
Создадим нашу модель на первых 800 образцах, чтобы сэкономить память. С помощью логистической регрессии предскажем название страны по указанным географическим координатам и уровню загрязнения.
Чтобы посмотреть итоги обучения модели, выполните:
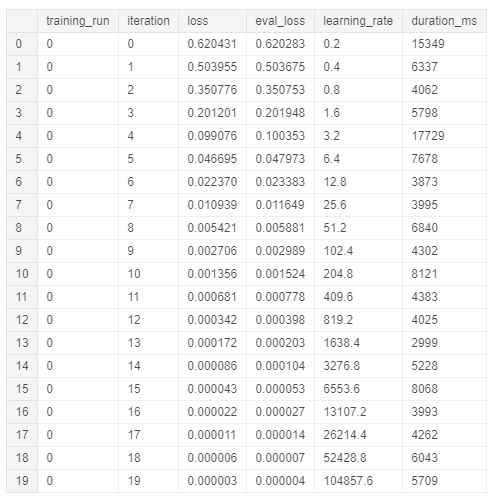
Определим точность модели:

Следующие шаги
Вы прочитали инструкции, поясняющие, как использовать SQL для решения проблем Data Science.
- Теперь создайте простой проект для работы с информацией в базе данных. Самый лёгкий способ – загрузить набор «грязных данных». Затем выполните шаги по очистке данных с использованием SQL вместо Panda