20. Расскажите про жизненный цикл бина, аннотации @PostConstruct и @PreDestroy()
UNKNOWNЖизненный цикл бинов
- Парсирование конфигурации и создание BeanDefinition
Цель первого этапа — это создание всех BeanDefinition. Объекты BeanDefinition — это набор метаданных будущего бина, макет, по которому нужно будет создавать бин в случае необходимости. То есть для каждого бина создается свой объект BeanDefinition, в котором хранится описание того, как создавать и управлять этим конкретным бином.
Проще говоря, сколько бинов в программе - столько и объектов BeanDefinition, их описывающих.
BeanDefinition содержат (среди прочего) следующие метаданные:
- Имя класса с указанием пакета: обычно это фактический класс бина.
- Элементы поведенческой конфигурации бина, которые определяют, как бин должен вести себя в контейнере (scope, обратные вызовы жизненного цикла и т.д.).
- Ссылки на другие bean-компоненты, которые необходимы для его работы. Эти ссылки также называются зависимостями.
- Другие параметры конфигурации для установки во вновь созданном объекте - например, ограничение размера пула или количество соединений, используемых в бине, который управляет пулом соединений.
Эти метаданные преобразуются в набор свойств, которые составляют каждое BeanDefinition. В следующей таблице описаны эти свойства:
Свойство -> Ссылка с описанием
Class -> Instantiating Beans
Name -> Naming Beans
Scope -> Bean Scopes
Constructor arguments -> Dependency Injection
Properties -> Dependency Injection
Autowiring mode -> Autowiring Collaborators
Lazy initialization mode -> Lazy-initialized Beans
Initialization method -> Initialization Callbacks
Destruction method -> Destruction Callbacks
При конфигурации через аннотации с указанием пакета для сканирования или JavaConfig используется класс AnnotationConfigApplicationContext. Регистрируются все классы с @Configuration для дальнейшего парсирования, затем регистрируется специальный BeanFactoryPostProcessor, а именно BeanDefinitionRegistryPostProcessor, который при помощи класса ConfigurationClassParser парсирует JavaConfig, загружает описания бинов (BeanDefinition), создаёт граф зависимостей (между бинами) и создаёт:
Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
в которой хранятся все описания бинов, обнаруженных в ходе парсинга конфигурации.
2. Настройка созданных BeanDefinition
После первого этапа у нас имеется коллекция Map, в которой хранятся BeanDefinition-ы.
BeanFactoryPostProcessor-ы на этапе создания BeanDefinition-ов могут их настроить как нам необходимо. BeanFactoryPostProcessor-ы могут даже настроить саму BeanFactory ещё до того, как она начнет работу по созданию бинов. В интерфейсе BeanFactoryPostProcessor всего один метод:
public interface BeanFactoryPostProcessor {
void postProcessBeanFactory(ConfigurableListableBeanFactory
beanFactory) throws BeansException;
}
3. Создание кастомных FactoryBean (только для XML-конфигурации)
4. Создание экземпляров бинов
Сначала BeanFactory из коллекции Map с объектами BeanDefinition достаёт те из них, из которых создаёт все BeanPostProcessor-ы, необходимые для настройки обычных бинов.
Создаются экземпляры бинов через BeanFactory на основе ранее созданных BeanDefinition.
5. Настройка созданных бинов
На данном этапе бины уже созданы, мы можем лишь их донастроить.
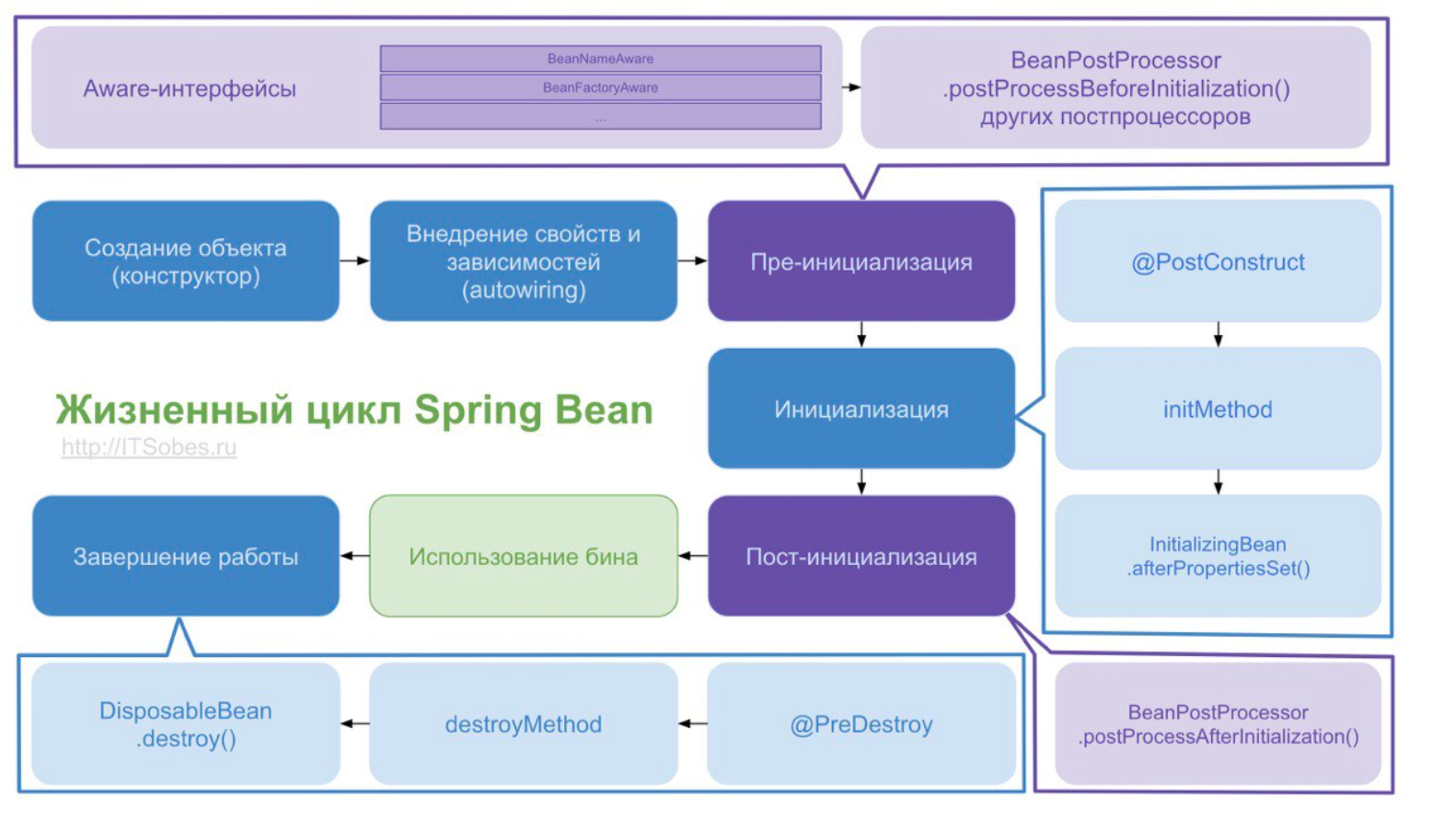
Интерфейс BeanPostProcessor позволяет вклиниться в процесс настройки наших бинов до того, как они попадут в контейнер. ApplicationContext автоматически обнаруживает любые бины с реализацией BeanPostProcessor и помечает их как “post-processors” для того, чтобы создать их определенным способом. Например, в Spring есть реализации BeanPostProcessor-ов, которые обрабатывают аннотации @Autowired, @Inject, @Value и @Resource.
Интерфейс несет в себе два метода: postProcessBeforeInitialization(Object bean, String beanName) и postProcessAfterInitialization(Object bean, String beanName). У обоих методов параметры абсолютно одинаковые. Разница только в порядке их вызова. Первый вызывается до init-метода, второй - после.
Как правило, BeanPostProcessor-ы, которые заполняют бины через маркерные интерфейсы или тому подобное, реализовывают метод postProcessBeforeInitialization (Object bean, String beanName), тогда как BeanPostProcessor-ы, которые оборачивают бины в прокси, обычно реализуют postProcessAfterInitialization (Object bean, String beanName).
Прокси — это класс-декорация над бином. Например, мы хотим добавить логику нашему бину, но джава-код уже скомпилирован, поэтому нам нужно на лету сгенерировать новый класс.
Этим классом мы должны заменить оригинальный класс так, чтобы никто не заметил подмены.
Есть два варианта создания этого класса:
- либо он должен наследоваться от оригинального класса (CGLIB) и переопределять его методы, добавляя нужную логику;
- либо он должен имплементировать те же самые интерфейсы, что и первый класс (Dynamic Proxy).
По конвенции спринга, если какой-то из BeanPostProcessor-ов меняет что-то в классе, то он должен это делать на этапе postProcessAfterInitialization(). Таким образом мы уверены, что initMethod у данного бина, работает на оригинальный метод, до того, как на него накрутился прокси.
Хронология событий:
- Сначала сработает метод postProcessBeforeInitialization() всех имеющихся BeanPostProcessor-ов.
- Затем, при наличии, будет вызван метод, аннотированный @PostConstruct.
- Если бин имплементирует InitializingBean, то Spring вызовет метод afterPropertiesSet() - не рекомендуется к использованию как устаревший.
- При наличии, будет вызван метод, указанный в параметре initMethod аннотации @Bean.
- В конце бины пройдут через postProcessAfterInitialization (Object bean, String beanName). Именно на данном этапе создаются прокси стандартными BeanPostProcessor-ами. Затем отработают наши кастомные BeanPostProcessor-ы и применят нашу логику к прокси-объектам. После чего все бины окажутся в контейнере, который будет обязательно обновлен методом refresh().
- Но даже после этого мы можем донастроить наши бины ApplicationListener-ами.
- Теперь всё.
6. Бины готовы к использованию
Их можно получить с помощью метода ApplicationContext#getBean().
7. Закрытие контекста
Когда контекст закрывается (метод close() из ApplicationContext), бин уничтожается.
Если в бине есть метод, аннотированный @PreDestroy, то перед уничтожением вызовется этот метод.
Если бин имплементирует DisposibleBean, то Spring вызовет метод destroy() - не рекомендуется к использованию как устаревший.
Если в аннотации @Bean определен метод destroyMethod, то будет вызван и он.
@PostConstruct
Spring вызывает методы, аннотированные @PostConstruct, только один раз, сразу после инициализации свойств компонента. За данную аннотацию отвечает один из BeanPostProcessor - ов.
Метод, аннотированный @PostConstruct, может иметь любой уровень доступа, может иметь любой тип возвращаемого значения (хотя тип возвращаемого значения игнорируется Spring-ом), метод не должен принимать аргументы. Он также может быть статическим, но преимуществ такого использования метода нет, т.к. доступ у него будет только к статическим полям/методам бина, и в таком случае смысл его использования для настройки бина пропадает.
Одним из примеров использования @PostConstruct является заполнение базы данных.
Например, во время разработки нам может потребоваться создать пользователей по умолчанию.
@PreDestroy
Метод, аннотированный @PreDestroy, запускается только один раз, непосредственно перед тем, как Spring удаляет наш компонент из контекста приложения.
Как и в случае с @PostConstruct, методы, аннотированные @PreDestroy, могут иметь любой уровень доступа, но не могут быть статическими.
Целью этого метода может быть освобождение ресурсов или выполнение любых других задач очистки до уничтожения бина, например, закрытие соединения с базой данных.
Обратите внимание, что аннотации @PostConstruct и @PreDestroy являются частью Java EE, а именно пакета javax.annotation модуля java.xml.ws.annotation. И поскольку Java EE
устарела в Java 9, то с этой версии пакет считается устаревшим (Deprecated). С Java 11 данный пакет вообще удален, поэтому мы должны добавить дополнительную зависимость для использования этих аннотаций:
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>
Предыдущий вопрос: 19. Расскажите про ApplicationContext и BeanFactory, чем отличаются? В каких случаях что стоит использовать?
Следующий вопрос: 21.Расскажите про scope бинов. Какой scope используется по умолчанию? Что изменилось в пятом Spring?
Все вопросы по теме: список
Все темы: список
Вопросы/замечания/предложения/нашли ошибку: напишите мне