17 bloques de código que todo científico de datos necesita saber
@programacion
Python ofrece varios códigos simplificados y versátiles para realizar tareas complejas dentro de bloques de código mínimos. A diferencia de otros lenguajes de programación que tienen anotaciones bastante complejas para resolver un problema específico, Python ofrece una solución más sencilla en la mayoría de los casos. Cada científico de datos necesita conocer ciertos bloques de código para comenzar su investigación en ciencia de datos y aprendizaje automático.
Es importante recordar que siempre se pueden reutilizar algunas líneas de código o bloques de código individuales, y en varios programas. Por lo tanto, los programadores de cualquier nivel, ya sea principiante, intermedio, avanzado o experto, deben desarrollar el hábito de memorizar códigos útiles. Esto le permitirá tomar decisiones más rápidas.
El objetivo principal de este artículo es presentar bloques de código que los científicos de datos puedan usar con regularidad, independientemente de los proyectos, problemas o tareas en los que estén trabajando. Los diecisiete bloques de código a continuación le brindarán una gran capacidad de reutilización para la mayoría de las tareas con poca o ninguna modificación.
El artículo está destinado principalmente a desarrolladores novatos. Sin embargo, los entusiastas de la ciencia de datos de nivel intermedio a avanzado que migren a Python desde otro lenguaje de programación también lo encontrarán útil. Entonces, sin más preámbulos, pasemos a describir estos 17 bloques de código.
1. Bucles condicionales e iterativos
def even(a):
new_list = []
for i in a:
if i%2 == 0:
new_list.append(i)
return(new_list)
a = [1,2,3,4,5]
even(a)
Los bucles condicionales e iterativos son código que la mayoría de los usuarios aceptan en su lenguaje de programación. Si bien estos bloques de código son los aspectos más básicos de la escritura de código, tienen una amplia gama de aplicaciones en todas las tareas de ciencia de datos, aprendizaje automático y aprendizaje profundo. Sin ellos, es casi imposible realizar las tareas más complejas.
El bloque de código anterior es un ejemplo simple de una función que utiliza tanto una instrucción condicional if como un bucle for. El ciclo for itera sobre todos los elementos, mientras que la instrucción if verifica los números pares. Si bien este bloque de código es un ejemplo trivial, hay varias otras opciones útiles que el usuario debe tener en cuenta.
2. Listas
lst = ['one', 'two', 'three', 'four']
lst.append('five')
lst
Las listas son un aspecto clave de las estructuras de datos. La mayoría de las estructuras de datos son una colección de diferentes elementos de datos que están estructurados de alguna manera. Las listas tienen algunas propiedades que les permiten usarse en casi todos los proyectos o tareas complejas que enfrentan los desarrolladores. La mutabilidad de las listas le permite cambiarlas o modificarlas según un caso de uso específico.
Para cualquier programa, necesitará una lista para almacenar información o datos relacionados con la tarea específica que está realizando. Para almacenar elementos adicionales en una lista, a menudo usará el método de agregar junto con un bucle for para iterar un comando en particular y almacenar los elementos en consecuencia.
3. Diccionarios
# Dictionary with integer keys
my_dict = {1: 'A', 2: 'B'}
print(my_dict)
# Dictionary with string keys
my_dict = {'name': 'X', 'age': 10}
print(my_dict)
# Dictionary with mixed keys
my_dict = {'name': 'X', 1: ['A', 'B']}
print(my_dict)
Otra estructura de datos importante que veremos es el diccionario. Esta estructura de datos también encuentra un uso frecuente en la mayoría de los programas. Los diccionarios contienen un conjunto de elementos desordenados. Con estos diccionarios, puede almacenar una variable clave que contenga varios valores. Al llamar a una tecla en particular, tendrá acceso a todos sus valores correspondientes.
Los diccionarios son fáciles de crear y almacenar en cualquier programa. Los desarrolladores generalmente prefieren estas estructuras de datos para varias tareas que requieren almacenar elementos emparejados. Cada par de elementos consta de una clave y un valor.
4. Declaraciones de interrupción y continuación
a = [1,2,3,4,5]
for i in a:
if i%2 == 0:
break
or j in a:
if j%2 == 0:
continue
Los operadores de interrupción ( break) y continuación ( continue) son los más útiles para desarrolladores y programadores cuando realizan cualquier tarea compleja de ciencia de datos. Estas declaraciones lo ayudan a completar un ciclo o condicional, o continuar una operación ó omitiendo un elemento innecesario.
El bloque de código anterior da una idea de la amplia gama de tareas que se pueden realizar con estos dos operadores. Si encuentra una variable o condición en particular y desea finalizar el ciclo, la instrucción break lo ayudará a hacerlo. Si después de ingresar alguna condición o variable, desea omitir este elemento y luego continuar con la operación, entonces el operador continue es la mejor opción para usted.
5. Función lambda
f = lambda x:x**2 f(5)
Las funciones regulares que usan la palabra clave def son en su mayoría adecuadas para grandes bloques de código. Sin embargo, si necesita obtener resultados rápidos y eficientes con costos mínimos de tiempo y espacio, debe usar la función lambda.
La función lambda evalúa un valor e inmediatamente devuelve el resultado o la solución de salida en un código de una línea. Por lo tanto, todo desarrollador debería considerar el uso de una función lambda para simplificar el código y realizar la tarea correspondiente con relativa facilidad y mayor eficiencia.
6. Función filter
a = [1, 2, 3, 4, 5] even = list(filter(lambda x: (x%2 == 0), a)) print(even)
La condición de filtro se usa para simplificar la mayoría de las operaciones en las que eliminamos todos los elementos innecesarios y mantenemos solo los más importantes necesarios para una tarea en particular. La efectividad de esta característica proviene del hecho de que cualquier problema complejo puede resolverse dentro de una o más líneas de código.
En el primer bloque de código, que es importante que todos los desarrolladores recuerden, discutimos un ejemplo de derivación de todos los números pares. Tenga en cuenta que usamos tanto una declaración condicional como un ciclo iterativo en el proceso de resolver dicho problema. Sin embargo, en el bloque de código anterior, podemos realizar la misma tarea de generar solo números pares para una lista de elementos en un código de una línea.
7. Función map
a = [1, 2, 3, 4, 5] squares = list(map(lambda x: x ** 2, a)) print(squares)
Map es otra característica única que tiene en cuenta todos los elementos esenciales en una estructura de datos particular y los atraviesa en consecuencia. Realiza una acción específica sobre cada uno de los elementos mencionados como argumento a dicha operación.
En resumen, esta map es una función integrada en Python que le permite procesar y transformar todos los elementos en modo de iteración sin usar un bucle for explícito. El bloque de código anterior realiza la operación de iterar a través de la lista provista y generar los cuadrados de cada uno de los elementos dados, respectivamente.
8. Función reduce
from functools import reduce a = [1, 2, 3, 4, 5] product = reduce(lambda x, y: x*y, a) print(product)
A diferencia de las dos funciones anteriores, filter()y map(), la función reduce (abreviatura) funciona de manera un poco diferente. Itera a través de una lista de números repetidos y devuelve solo un valor. Para usar esta función, debe importar un módulo adicional llamado functools. Después de eso, puede comenzar a usar la operación de reducción. La función reduce es la última de las funciones anónimas que discutiremos en este artículo.
9. NumPy
import numpy as np X = np.array(X) y = np.array(y) y = to_categorical(y, num_classes=vocab_size) ##Numerical Python — una de las mejores bibliotecas para resolver ##problemas matemáticos. Existe una amplia gama de problemas y desafíos ##que los desarrolladores y programadores pueden resolver con esta ##increíble biblioteca. Puede convertir las listas almacenadas con ##elementos enteros en una estructura numpy y comenzar a realizar ##varias operaciones en ellas.
Las aplicaciones de NumPy son numerosas en todas las áreas. En un campo como el de la visión artificial, podemos usar matrices NumPy para representar un modelo de color RGB (rojo-verde-azul) o en escala de grises como una matriz NumPy y transformar cada elemento en consecuencia. En la mayoría de los proyectos de procesamiento de lenguaje natural desarrollados, generalmente preferimos convertir los datos textuales en vectores y números para mejorar los cálculos optimizados. Para la siguiente tarea, puede importar fácilmente la biblioteca NumPy y continuar convirtiendo datos de texto en datos categóricos, como se muestra en el bloque de código anterior.
10.Pandas
Pandas es otra biblioteca que utilizará todo el tiempo para interpretar datos. Es una de las mejores bibliotecas para ver datos en casi cualquier formato, especialmente como archivos CSV o Excel. Es conocido por su excepcional utilidad en tareas relacionadas con el procesamiento y análisis de datos en proyectos de aprendizaje automático.
La biblioteca realiza la mayoría de las tareas relacionadas con la alineación de datos, la indexación, el corte y la configuración de conjuntos de datos muy grandes. Se utiliza para resolver los problemas más complejos en un formato estructurado. Simplemente puede leer los datos disponibles en un código de una línea y continuar interpretándolos de la manera que más le convenga.
11. Matplotlib
import matplotlib.pyplot as plt
plt.bar(classes, train_counts, width=0.5)
plt.title("Bar Graph of Train Data")
plt.xlabel("Classes")
plt.ylabel("Counts")
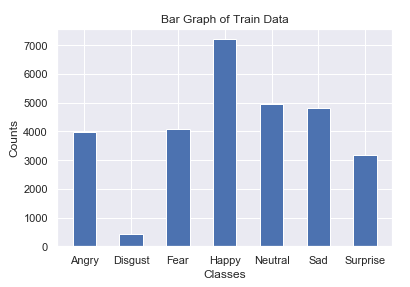
El último algoritmo de aprendizaje automático que casi siempre se combina con NumPy y Pandas es Matplotlib. Esta biblioteca es extremadamente útil para la visualización. Mientras que las otras dos bibliotecas lo ayudan a ver aspectos individuales de los elementos de datos de forma estructural o numérica, la biblioteca Matplotlib le permite capturar estos aspectos en forma de una representación visual.
La representación visual de datos numéricos ayuda a utilizar métodos de búsqueda para su análisis en tareas de aprendizaje automático. Con la ayuda de estos métodos de análisis, podemos elegir las direcciones apropiadas para resolver un problema en particular. El bloque de código es una visualización de gráfico de barras de sus datos. Esta visualización es un método ampliamente utilizado para ver datos.
12. expresiones regulares
import re
capital = re.findall("[A-Z]\w+", sentence)
re.split("\.", sentence)
re.sub("[.?]", '!', sentence)
x = re.search("fun.", sentence)
El módulo de expresiones regulares es una biblioteca de Python preconstruida que ofrece a los desarrolladores excelentes formas de resolver cualquier problema de procesamiento de lenguaje natural. Proporciona a los usuarios muchos comandos para simplificar los datos de texto disponibles. Con la ayuda de Re-library, puede importarlos para realizar varias operaciones en letras, palabras y oraciones.
13. Kit de herramientas de procesamiento de lenguaje natural
import nltk sentence = "Hello! Good morning." tokens = nltk.word_tokenize(sentence)
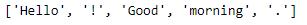
Las operaciones de expresiones regulares son excelentes para las primeras etapas de un proyecto de procesamiento de lenguaje natural. Sin embargo, en el futuro, otra excelente biblioteca viene en ayuda del desarrollador. Realizará de manera eficiente la mayoría de las tareas, como la inferencia, el marcado, la lematización y otras operaciones similares. Gracias a la biblioteca del kit de herramientas de procesamiento de lenguaje natural (NLTK), los usuarios pueden desarrollar fácilmente proyectos de PNL.
La biblioteca NLTK es una de las herramientas más útiles para los desarrolladores. Este módulo permite simplificar las tareas más complejas con unas pocas líneas de código. La mayoría de las funciones proporcionadas por la biblioteca le permiten realizar ajustes complejos a los datos de texto dentro de una o más líneas de código. El bloque de código anterior con la salida proporcionada es uno de esos ejemplos.
14. Imágenes con almohada
# Importing the required libraries
import numpy as np
from PIL import Image
import PIL# Opening and analyzing an image
image1 = Image.open('Red.png')
print(image1.format)
print(image1.size)
print(image1.mode)
Trabajar con imágenes es un aspecto importante para los científicos de datos que están interesados en explorar más a fondo los campos de la visión artificial y el procesamiento de imágenes. Pillow es una de esas bibliotecas de Python que ofrece a los usuarios opciones versátiles para administrar imágenes y fotos.
Los usuarios pueden realizar muchas tareas utilizando la biblioteca de Pillow. El ejemplo que se muestra en el bloque de código anterior lo ayudará a abrir una imagen en una ruta determinada. Al hacerlo, podrá explorar muchos parámetros de la imagen, como la altura, el ancho y la cantidad de canales. Tendrá la capacidad de administrar y manipular la imagen de manera adecuada y, finalmente, guardarla.
15. Imágenes de Open-CV
import cv2 # Importing the opencv module
image = cv2.imread("lena.png") # Read The Image
cv2.imshow("Picture", image) # Frame Title with the image to be displayed
cv2.waitKey(0)
Open-CV es una de las mejores bibliotecas utilizadas por los desarrolladores en todas las etapas para resolver con éxito problemas relacionados con imágenes, fotos, efectos visuales o videos. Esta biblioteca, entre otras cosas, se utiliza para calcular acciones relacionadas con el funcionamiento de la cámara web en tiempo real.
La disponibilidad general y la popularidad de este módulo lo hacen indispensable para la mayoría de los científicos de datos. El bloque de código anterior es un ejemplo de representación de una imagen en una ruta de directorio dada.
16. Clases
class Derivative_Calculator:
def power_rule(*args):
deriv = sympy.diff(*args)
return deriv
def sum_rule(*args):
derive = sympy.diff(*args)
return deriv
differentiatie = Derivative_Calculator
differentiatie.power_rule(Derivative)
Las clases son una parte integral de los lenguajes de programación orientados a objetos. Python usa clases para combinar datos y funciones. En comparación con otros lenguajes de programación, la mecánica de clasificación en Python es ligeramente diferente. Es una mezcla de algoritmos de clasificación tomados de C++ y Modula-3.
Las clases se utilizan ampliamente incluso para desarrollar modelos de aprendizaje profundo. Al escribir códigos de TensorFlow, es posible que deba crear una clase personalizada para definir sus modelos en consecuencia. Este método de creación de subclases de modelos lo utilizan los desarrolladores al más alto nivel.
17. Aleatorio
import random r = random.uniform(0.0,1.0)
La biblioteca Random, preconstruida y ofrecida por Python, es uno de los módulos más importantes que lo ayudará a realizar la mayoría de las tareas que involucran incertidumbre o aleatoriedad. Son ampliamente utilizados para resolver la mayoría de los problemas de programación relacionados con las predicciones en el aprendizaje automático.
A diferencia de los humanos, la mayoría de las computadoras tienen un rango de valores para predecir valores exactos. Por lo tanto, la variable aleatoria y la biblioteca Random se encuentran entre los elementos más importantes de Python. Después de todo, los proyectos de aprendizaje automático y aprendizaje profundo requieren que el usuario especifique un rango de aleatoriedad a partir del cual se pueden obtener los valores más precisos.
Conclusiones
“CUALQUIER TONTO PUEDE ESCRIBIR UN CÓDIGO QUE UNA COMPUTADORA PUEDA ENTENDER. LOS BUENOS PROGRAMADORES ESCRIBEN CÓDIGO QUE LA GENTE PUEDE ENTENDER”. — MARTÍN FOWLER
En cualquier lenguaje de programación, hay módulos que usará con más frecuencia que otros. El lenguaje de programación Python también tiene bloques de código que los usuarios prefieren sobre otros. Este artículo fue dedicado a ellos. Es cierto que no hemos considerado todos los elementos. Hay muchos más conceptos que vale la pena aprender en el mundo de la programación Python.
Fuente:
https://elsolitario.org/?p=516&preview=true