当我们谈论收敛速度时,我们都在谈什么? - 知乎每日精选
知乎每日精选今天我们聊一聊收敛速度,看别人论文的时候,他们总会说我们的算法是sublinear convergence, 我们的算法是linear convergence的, 我们的算法是 quadratic convergence。。。看的我云里雾里,所以你们的算法,到底是什么样的convergence呢?
至少我查维基百科的时候没有看懂 (Rate of convergence),因为我以前没有弄明白过,所以觉得可能有一些人和我一样不是特别天资聪颖所以可能也没弄明白,我愿意稍微写一些我不太正确又不够严谨的看法,希望对人有启发吧。
咱外行看个热闹,如果有啥没说对的地方,欢迎批评指证。能力有限,也就拼拼凑凑一些简单的东西了,大牛见笑了。
本文有三部分:
Part I: Introduction of Convergence Rate (informal)
Part II: Sublinear Convergence & Linear Convergence & Quadratic Convergence
Part III: Example Convergence Rate of GD under Convex, Strong Convex, Non-Convex
%-------------------------------------------正文开始--------------------------------------------------------------
Part I: Definition (informal)对于一个 Optimization 的问题,只考虑一阶的话,我们希望得到 Convergence Analysis 无外乎三种
- 最差的情况下,我们需要迭代多少次,才能保证当前得到的点
与最小值点
的距离一定小于

- 最差的情况下,需要迭代多少次,才能保证当前得到的函数值
与函数的最小值的差一定小于

- 最差的情况下,需要迭代多少次,才能保证当前得到的导数
一定小于
(

其实就是你对这个算法的精度要求,
越小,就是希望算法输出的解的精度越高,反之亦然。
但这个世界是很奇怪的,这三种不是都能数学推导分析出来的,不同的算法,不同的条件,有时候你只能分析出来其中一到二种,有时候你一个也分析不出来,都是正常的,看缘分了。
下面我们就拿我们希望举例子,假设需要迭代
次,才能保证一定达到我们的要求,那么一般求出来的T都是一个和
有关的函数,如果求出来
,我们就知道,我们的迭代次数,至少是
Order (数量级)的, 我们才一定能达到
。于是我们就说我们的算法最差需要
的 Order (数量级) 才能达到
的精度了,这个貌似就叫做Upper Complexity Bound (具体是不是这个叫法,我找不到了,但是算是某个东西的 Upper Bound)。不过有的论文里有时候可不这么说,他就说我们的算法是sublinear convegence的。。。所以什么是 sublinear convegence 呢?
另外 Order 越小,说明达到相同的精度,算法所需要的迭代次数越少,迭代的次数少,自然这个算法就快。
结论就是:
Order 越小,一般来说算法越快。
比如哈,一般来说表示精度,我们一般比较都是比较
的时候所以,很明显可以得到
,所以 Order 是
的算法可能会比 Order
的算法快,但是这只是一个upper bound的比较,算是最差情况下的比较,不同情况下,算法的表现是会有差异的。
这关于的 Order 就是大家你死我活的不停向前拱,想 improve 的东西了,也是大家论文相互比较的重点。
先上结论,只要背了这张表,其实本文的重点已经结束了,后文的一切不过是为了加深记忆和理解而已~(请注意:表格上,只是我自己的总结, 推导公式其实有好多别的形式,我举的只是我见过的,不涵盖全部哈)

它们的快慢关系是 Sublinear < Linear < Quadratic, Quadratic最快了。 稍微画的图,感受一下Sublinear有多慢好了。。。x轴是要求的精度,y轴是所需要的迭代次数。

其实,自然而然的问题是,给定要求,如何找到,最差情况下,我们需要的迭代次数
的Order呢?
一般你推公式,推啊推啊推的,都能得到一些迭代的式子,下面就分Sublinear Convergence & Linear Convergence & Quadratic Convergence 三种情况分别举例。
(1) Sublinear Convergence
这种情况下,你一般会得到这样的递推公式
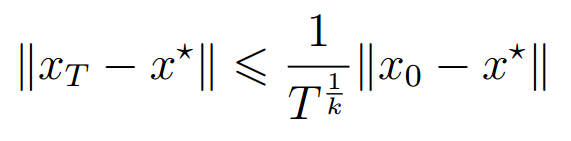
为了让,我们只需要让
加上
是一个常数,因为
是我们的初始点,
是极小值点,他们都是不变的。 所以我们能得到
, 也就是Order
。
所以Sublinear Convergence 的Order 是,
对应推导公式是 。
(2) Linear Convergence
这种情况下,你一般会得到这样的递推公式

注意这里,一直递推下去,就能得到
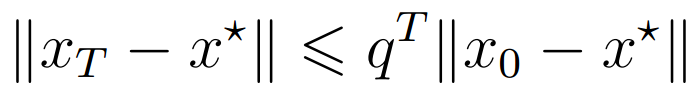
为了让,我们只需要让
加上
是一个常数 ,两边取对数可得

然后两边都除以, 注意
,所以
, 不等号要改变方向

公式(ii)因为,而且
是常数,所以直接写个
替代了。
所以Linear Convergence 的Order 是,
对应推导公式是。
( 3 ) Quadratic Convergence
这种情况下,你一般会得到这样的递推公式

然后我们一路迭代下去

公式(i)用等比数列去和公式,公式(ii)因为是常数,说以用一个
来替代一个
。下来我们令
,并假设
,那么为了得到
,只需要
,两边取对数可得

公式(i)要注意到,所以
,不等式两边要变号,而且变成常数后要加负号,所以
变成了
。公式(ii)是两边同时又取了一次对数。
所以,Quadratic Convergence的Order 是
推导公式是
Remark: Quadratic 比linear 多了一个平方, 这个收敛速度我目前就只在 Netwon Method 里见到过。
再回头看看 Table 1, 是不是顺眼多了。数学嘛和你喜欢的姑娘一样,都是越看越顺眼的,哈哈!
Part III: Convergence Rate of Gradient Descent这是总结的一个 Gradient Descent 在不同情况下的收敛,大家稍微背一背,以后就可以和别人吹牛了 ~~~我觉得还蛮实用的。你也能看出 GD 在 non-convex 下是 这不知道比 linear 的慢了多少倍。

%-----------------------------------------------------------------------------------------------------------------
话说有多少人想看, Gradient Descent 在 Convex, Strongly Convex, Non-Convex下的数学推导?一步一步推导出 Table 2 里的 Convergence Rate, 想看的话在下面留言,想看的人多的话,我可以专门写一篇专栏讲一讲这三种情况下的推导,推导不难,但是还蛮有趣的。
证明现在有啦,可以看这篇文章
哎呀:梯度下降在强凸/凸/非凸下的收敛速率证明%---------------------------------------------------------------------------------------------------------------------
谢谢你看到最后,但愿这些对你有帮助,有启发的话,点个赞呗,只收藏不点赞鼓励一下,人家都没有写下去的热情了。
以后想一起学习凸优化,非凸优化的可以关注我和专栏啦,我会写一些我看到的有意思的观点和思路的,哈哈!
参考文献:
【1】 Nesterov <Introductory Lectures on Convex Programming>
来源:知乎 www.zhihu.com
作者:Zeap
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
本文章由 flowerss 抓取自RSS,版权归源站点所有。