声纹识别是个什么原理? - 知乎日报
知乎日报

OwlLite,{}
查看知乎原文
谢邀
区别于专注将语音转换为文字的语音识别(speech recognition, 应用如语音输入法), 声纹识别目的在于辨别说话者 / 发声者的身份(Identity) [1]。

声纹识别有两种应用场景: 1:1 验证(简称验证, Verification), 比如显示为女朋友 / 老婆的电话号打来, 接听之后发现声音不是她, 那就让人紧张;1:n 验证(又称识别, Identification), 比如陌生电话打来, 对方说一句字面上没有任何意义的"老王, 是我啊", 如果真是熟人, 你就能很快辨得 TA 的身份, 如果认为不是, 那就有可能是某省的人打来的了。
声纹识别有两种识别场景: 文本相关的, 这需要说话者说出固定的文本内容来给算法验证 :
https://azure.microsoft.com/en-us/services/cognitive-services/speaker-recognition/
比如, 汽车开起来有异响,我们可以判断车出问题了; 文本不相关的, 则不需要说话者说固定内容, 类比于汽车正常跑时候没啥异响, 但过减速带时候会有明显的异响. 通过这两个类比可以判断, 文本不相关的声纹识别要比文本相关的要更具难度.
声纹识别的本质, 就是要找到描述特定对象的声纹特征(feature)。
声纹特征可以分为听觉特征(Auditory feature)和声学特征(Acoustic features)。 前者是指人耳可以鉴别和描述的声音特征, 比如说话气声多 / 中气十足这样的描述。 后者是指计算机算法(数学方法)从声音信号提取出来的一组声学描述参数(向量) [2]。 不过这两者本质上还是一回事, 因为人耳可以鉴别的声音特征也可以使用算法生成和提取出来。
声纹特征还有语言学特征和非语言学特征, 比如两湖地区的人说话通常 n/l 不分, 南方人分不清卷舌和平舌音, 以及一些特定的方言说法等。 这类特征可以辅助声纹识别, 缩小 1:n 验证时候的检索对象范围。
另外, 声纹特征还可以分为短时特征和长时特征。 类比我们对一个人的描述, 如果是一个失踪的人, 我们会描述他离家时穿什么衣服(短时特征), 身高性别(长时特征)等; 描述一个熟人的时候, 我们通常会说 TA 的性格,做事风格(长时特征)等, 这时候如果说 TA 穿什么衣服就显得可笑了。 在声纹识别范畴, 我们最常使用的是声纹的短时特征, 因为我们用于识别的一段话通常都比较短。 长时特征通常是短时特征的平均, 比如基础频率 / 频谱特征等等。 长时特征因此更少受到说话语气 / 说话者身体情况变化的影响。
声纹识别在数学操作上, 就是对输入的声音信号进行数学操作, 得到一组特征描述向量。 声纹识别方法的好坏, 则主要在于从不同声纹对象提取的不同特征向量的区分度, 以及从相同声纹对象的声音在不同时间提取的特征向量之间相似度。 前者称为类间差异(Interclass Varience), 后者称为类内差异(Intraclass Varience)类比我们对一个人的描述, 如果说 TA 出门穿衣服, 这个描述可以作为一个特征, 但是不是一个好特征, 因为几乎所有人出门都会穿衣服, 这个特征描述的类间差异太小。 而如果说 TA 面部某个地方有个胎记, 那这就是一个好的描述特征, 因为这个描述具有很好的区分度(类间差异大)和复现性(类内差异小)。 得到声纹对象的特征向量之后, 我们把这个特征和注册的声纹特征向量进行比较, 比如计算欧氏距离(d), 当这个距离大于一定值(Th)时, 我们认为是源自不同人, 小于这个值时, 则认为是同一个人。
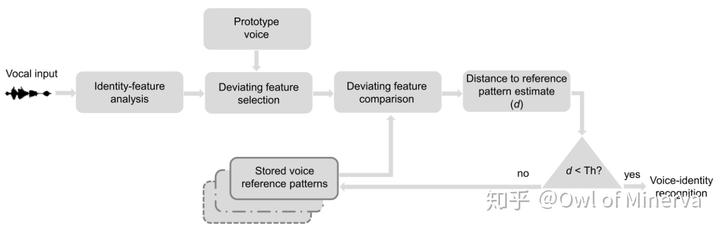
至于特征提取方法, 按照发展历程有模板匹配, 高斯混合模型(GMM), 联合因子分析法(JFA), 深度神经网络方法等【3】。 深度神经网络之前的方法基本可以认为是传统方法。 传统方法是用可以用精确数学模型描述的操作对声音信号进行分析, 得到的特征具有较好的可解释性, 需要的数据量相对较小。 深度神经网络对声音信号的操作则不便使用数学模型进行精确描述, 它是一种数据驱动的方法, 需要更大量的数据对模型进行训练(有多少数据 / 人工, 就有多少智能)。 不过深度神经网络是更为强大的特征提取方法, 只要保证足够多和好的数据输入, 就可以预期较好的效果。
我们人脑的声纹识别系统跟计算机声纹识别基本类似[4], 不过人脑的声纹特征提取更为灵活, 可以更方便的结合短时 / 长时 / 语言学 / 抽象声音特征等描述进行分析 [5]。
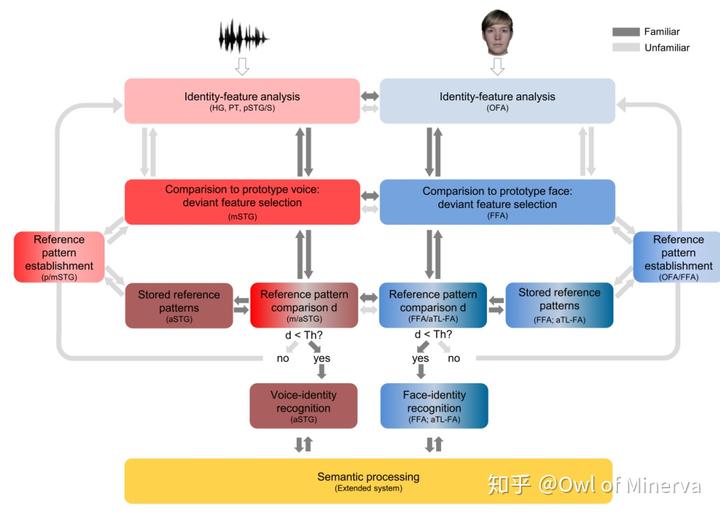
由于同一个声纹信号的多变性, 声音采集设备的影响, 环境噪声的影响, 声音内容的变化等因素, 声纹识别目前还难以做到很高的准确率和可靠性(FAR)。 因此在使用时不宜作为第一选项。
[1] Campbell, Joseph P. "Speaker recognition: A tutorial."Proceedings of the IEEE 85.9 (1997): 1437-1462.
[2] Mariéthoz, Johnny, Samy Bengio, and Yves Grandvalet.Kernel Based Text-Independnent Speaker Verification. No. LIDIAP-REPORT-2008-013. Idiap, 2008.
[3] Snyder, David, et al. "X-vectors: Robust DNN embeddings for speaker recognition."Submitted to ICASSP(2018).
[4] Maguinness, Corrina, Claudia Roswandowitz, and Katharina von Kriegstein. "Understanding the mechanisms of familiar voice-identity recognition in the human brain."Neuropsychologia (2018).
[5] Badcock, Johanna C., and Saruchi Chhabra. "Voices to reckon with: perceptions of voice identity in clinical and non-clinical voice hearers."Frontiers in Human Neuroscience 7 (2013): 114.
查看知乎讨论
本文章抓取自RSS,版权归源站点所有。
查看原文:声纹识别是个什么原理? - 知乎日报
[点击] 加入书友群 1.5TB电子书资源 @ideahub_ml
[点击] 全网福利资源|薅羊毛·省钱中心 @rss_news_list

