信息论与机器学习 - 知乎每日精选
知乎每日精选虽然标题中有机器学习,但这篇文章更主要讲的是信息论的一些知识。在后面会对信息论中的一些理论在机器学习中的应用进行简单的介绍。写这篇文章的原因在于总是在看书或者读paper时遇到有关于信息论的一些知识,虽然已经学过信息论,但某些简单的概念总是让我感到混乱。这里既是复习,也是整理。编码
谈到信息论,就离不开编码。谈到信息论就离不开传递信息,传递信息的过程需要对信息进行编码,而如何用最少的编码表示所要传递的信息就是我们要研究的目标了。
假设两地互相通信,两地之间一直在传递,
,
,
四类消息,那应该要选择什么样的编码方式才能尽可能少的使用资源呢?如果这四类消息的出现是等概率的,都为
,那么肯定应该采用等编码方式,也就是
这样就能达到最优的编码方式,平均编码长度为。
但是,如果四类消息出现的概率不同呢?例如消息出现的概率是
,
是
,
是
,
是
,那应该怎样编码呢?直觉告诉我们,为了使平均编码长度尽可能小,出现概率高的
消息应该使用短编码,出现概率低的
,
消息应该使用长编码。与等长编码相比,这样的编码方式叫做变长编码,它的效果更好,例如采用下表所示的编码(其实这是最优编码)
平均编码长度为
在对消息进行变长编码时,可以看到对消息编码后,后面的三类消息编码都不是以
开头。这是因为在编码时必须保证该编码是唯一可解码的。例如若
消息编码为
,
消息编码为
,那么
的编码就会产生歧义,即不知道在何位置对接收到的编码消息进行划分。因此在进行变长编码时,就必须保证任何编码都不是其他编码的前缀。符合这种特性的编码称为前缀码(Prefix Codes)。
从上面的叙述可以看出,每当在某位置选取一个编码以后,我们都要损耗一部分编码空间,如图
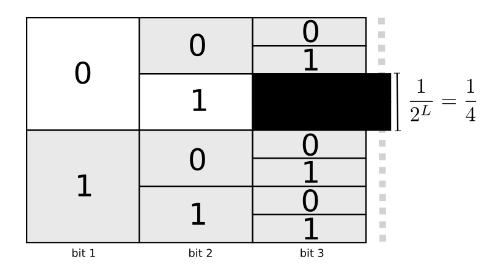
因此,为了达到对信息进行最优编码的目标,我们要在使用尽可能短的编码与短编码可能会导致编码空间不可用的两种情况中进行权衡。
我们可以把使用短编码需要消耗的编码空间称为编码代价。事实上,为了达到理论上的最优编码,我们只需要根据不同消息出现的概率
给每类消息分配相应的编码代价即可以达到最优编码,假设
的编码长度为
,那么
这样,对于分布,我们的平均编码长度就是
在信息论中,被称为熵,熵代表了理论上对符合
分布的消息进行编码的最优编码的平均长度。
若现在还有一种消息序列的概率分布满足分布,但是它仍然使用
分布的最优编码方式,那么它的平均编码长度即为
其中被称为
分布相对于
分布的交叉熵(Cross Entropy),它衡量了
分布使用
分布的最优编码方式时的平均编码长度。
交叉熵不是对称的,即。交叉熵的意义在于它给我们提供了一种衡量两个分布的不同程度的方式。两个分布
和
的差异越大,交叉熵
就比
大的越多,如图

它们的不同的大小为,这在信息论中被称为KL散度(Kullback-Leibler Divergence),它满足
KL散度可以看作为两个分布之间的距离,也可以说是可以衡量两个分布的不同程度。
多变量熵与互信息和单变量相同,如果有两个变量,
,我们可以计算它们的联合熵(Joint Entropy)
当我们事先已经知道的分布,我们可以计算条件熵(Conditional Entropy)
与
变量之间可能共享某些信息,我们可以把信息熵想象成一个信息条,如下图
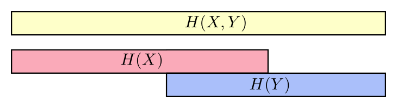

更细一点,我们把与
重叠的部分定义为
与
的互信息(Mutual Entropy),记作
,则
互信息代表了中包含的有关于
的信息(或相反)。
将与
不重叠的信息定义为差异信息(Variation of Information),记为
,则
差异信息可以衡量变量与
的差距,若
为0,就意味着只要知道一个变量,就知道另一个变量的所有信息。随着
的增大,也就意味着
与
更不相关。形象化的表示可以从下图看出
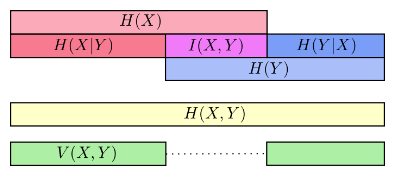
在分类任务中,我们想要的结果是使预测的分布和真实的分布尽量接近,交叉熵提供了一种非常好的衡量方式,在LR分类,SVM多分类等问题中经常用到,将交叉熵定义为损失函数
其中代表真实分布,
代表预测分布,优化目标为
。
在概率推断中,经常使用变分推断来近似隐变量真实的后验分布
。利用如下公式
其中
上式中的称为证据下界(Evidence Lower Bound)。
这里KL散度描述了估计分布
与真实分布
的差别,当
时两分布就是相同的。我们知道
,但因为我们不知道真实的后验分布
是什么,因此无法直接最小化
,但是我们可以通过最大化
来达到这个目的。而在求解最大化
的过程中,可以利用平均场方法(Mean Field)将最终目标可以转化成最小化另外的一个KL散度(这里省略推导了,具体可参见《机器学习》)。
- Visual Information Theory
- 《机器学习》周志华
- 《Pattern Recognition and Machine Learning》Christopher Bishop
来源:知乎 www.zhihu.com
作者:PENG
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
本文章由 flowerss 抓取自RSS,版权归源站点所有。
查看原文:信息论与机器学习 - 知乎每日精选