【优质信源】计划05--从基本的强化学习角度分析无线通信中的低延时调度策略 - 知乎每日精选
知乎每日精选Reviewed by: @甜草莓 @D.Han;前置知识:通信原理、马氏决策过程、拉格朗日松弛、值迭代/策略迭代一、研究背景
移动网络的第五代(5G)及其Beyond之类的未来无线网络带来了更严格的服务质量要求,以此用来支持爆炸性增长的移动设备应用。

低延迟是URLLC(超可靠的低延迟通信)最重要的要求之一,这也是5G带来的三大功能之一。对于通常由有限容量的终端或者基站节点,这些节点迫切需要高能效。
国家5G建设,除了部署成本非常高以外,使用起来后的功耗也是非常大的。
很多媒体也发文,面对目前没有强需求的压力,5G的部署还有很大的阻碍是来自与电费。随便上网一搜就有许多报道,这里用的关键词是“5G基站+电费”:

从前人们对电信运营商的普遍印象就是“富可敌国”,毕竟基本每个人都需要用手机,每月资费也与运营商年年月月斗智斗勇~
像那些密密麻麻矗立在城市、乡村大地上的信号塔就像一根根“吸血管”,日夜不停、源源不断地从亿万用户中吸取收入和利润,从日赚2亿、到日赚3亿、到日赚4亿。甚至5G时代资费是4G时代的十倍,那么运营商收入有希望能与四大行比肩?
从2018年数据来看,三大运营商合计营收1.4万亿,合计利润1431亿元,日均赚钱3.92亿。按中国14亿人口来算,每人要平均要给运营商贡献100元左右的利润值。 而工商银行净利润为2987亿元,农业银行净利润2,028亿元人民币,中国银行净利润1801亿元, 建设银行净利润2547亿元,合计为9363亿,是三大运营商的6.54倍。 如果算到全国14亿人,人均贡献669元,是三大运营商的6.7倍,日均赚钱25.65亿,也是三大运营商的6.54倍。
现在看来其实不是这样的。
面对如此高的电费需求,甚至许多人在看过5G的功耗计算以后直呼“国家电网恐怕成为5G最大赢家”!


在能耗方面能耗,不仅5G建设时候需要更多的电源存储设备,后期运行起来消耗的能量也是非常巨大的,这令运行商们十分头大!
面对功率消耗的火箭式上升,运营商在部署5G上页更加小心翼翼,一不小心就付不起电网爸爸的钱了。
对于5G的功耗控制,对于移动联通电信等运营商与华为中兴等设备商是十分紧迫要解决的一个问题。

使用一些高效的通信调度算法通常能够极大地减小传输所需要的功耗。根据队列长度、信道状态进行调度也可以减小平均时延与功率消耗。
较低的功率在基站端意味着网络功耗的降低,说白了就是运营商跟GJ会更省钱(4G还没收回成本,能省一毛是一毛啊~)!
较低的功率在用户端则意味着手机消耗的电量越小,那么无疑会延长手机电池的使用时间~
因此对于无线通信中的这些用户与基站来说,以有限的发射功率来实现尽可能小的时延要求是急需新的方案的。
我们本文提出的策略可以可以统一管理和调度无线资源,使资源调配更加灵活高效!

工业界以及学术界都将功率受限情况下的低时延通信这个问题作为了一项研究热点课题。如【优质信源】计划01中提到的Ephremides,Gallager, EI Gamal, Ata, Modiano, Shroff等知名学者都对这个问题很感兴趣,在不同的场景下使用不同的建模方式和解决方案对该问题进行研究。
二、研究场景功率分配,其实功率注水已经是一个非常具有创造性的成果了,但是功率注水是有非常大的局限性的。
功率注水:
用拉格朗日乘子法或者KKT条件求解这个凸优化问题,得出的结果是
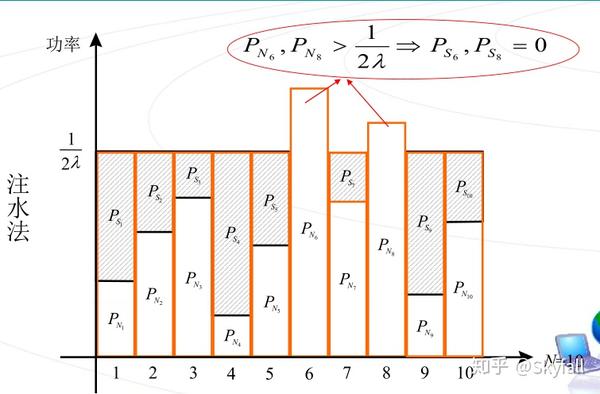
相信这个大家已经非常熟悉了,在通信原理、信息论、凸优化课程中应该都有讲解。
还有一种功率分配策略是基于李雅普诺夫优化[1]的队长加权速率的分配方式。
解出的结果也是类似的注水策略。这几种功率分配的策略是非常好的,但是也是有致命缺陷的。比如在某个时隙上所有用户的信道都很差,用这种方式分配功率不能把这个信道差的时隙上的功率节约出来,放到信道较好的时隙上去。
- 传统功率注水只能在一个时隙上进行分配,无法在时域上进行分配。
- 传统功率注水不能对单用户进行分配,因为无法在时域上进行分配。
(当然也有时域注水[2],就是有很大的局限性,并且大部分情况下只是近似解,简单来讲就是对信道容量关于功率的函数进行时域积分,这里不再赘述。)
上述的这些解法都不是时延最优的解法,基本无法满足URLLC的要求,所以我们,提出了一种基于马氏决策的无线通信调度算法。
1、队长角度
在一个长时运行的系统当中,根据Little定律,对任意一个排队系统而言,在统计平衡状态下有
其中λ: 平均到达率, L: 平均队列长度, W: 平均滞留时间,由此我们可看出在平均到达率一定的情况下,平均队长越长会导致平均服务时间越长。
- 多用户系统当中,队长长的用户需要分得更多的功率。
- 单用户系统当中,队长长的时刻需要分到更多的功率。
这样让队长长的状态尽快发送数据包,减小队长长的状态的概率,以此来达到更小的平均队长。因此不同的队长情况下,发送速率应该是不尽相同的。不考虑信道的变化,队长越长分得的功率应该越多。
2、信道角度
这一部分在【优质信源】计划01中已经说得比较清楚了,在这里我搬运一下。
在实际场景中,无线信道会因为传输环境中的散射、反射等因素导致的多径效应,产生时变的信道状态,也就是信道质量的好坏程度会随着时间变化,而信道质量会影响通信的能量效率。
如下图所示,在信道条件好的时候(绿色),移动设备可以用相对低的传输功耗发送数据;但是在信道条件不好的时候(红色),为了克服坏信道的影响,移动设备需要使用更高的传输功耗发送数据。假设需要发送4次数据,不考虑信道好坏则最快可以在4个时隙内完成传输(1次低能耗+3次高功耗);如果想最小化移动设备的功耗,那么需要只在好信道条件下传输,算上等待信道变好的时间,一共需要7个时隙。
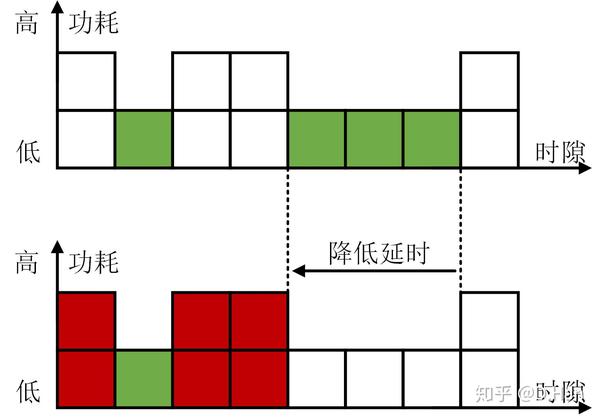
那么很好理解,如果随机产生的数据包到达后,移动设备不考虑信道状态就直接进行传输,由于无需等待所以延时可以很低,然而当遭遇恶劣信道时,能量效率也会很低。如果数据包到达后可以缓存在移动设备中,然后等待信道条件好的时候再进行机会传输,那么虽然可以降低能耗,但延时也会增大。
因此我们可以看出,在不同的信道条件下,发送速率应该是不尽相同的。在不考虑队列长度的变化时,信道越好时候应该分配更多的功率。
本文是【优质信源】计划01的一个续集,从强化学习角度来解决的,也建议也阅读一下下面这篇文章。
D.Han:【优质信源】计划01--一种无线通信中的低延时调度方法介绍三、模型假设这一部分我们也用【优质信源】计划01中的模型,用同样的模型假设,换一种思路来求解最优的Tradeoff曲线。
在这里我们采用限制功率,最小化平均时延。
很多通信的理论研究中会考虑离散的时间模型,即将连续的时间划分为若干离散的时隙。我们用符号 来表示时隙的编号。
接下来为了刻画前文所述的通信调度过程,需要选择合适的时变信道模型、数据包到达模型,以及传输功耗模型。
3.1 时变信道模型在这个模型中我们采用块衰落信道。在有些情况下,若基站与移动台之间几乎没有相对移动,可认为一定时间内信道基本保持不变,在这段时间内的连续符号遭受的衰落是相同的,这就是块衰落信道。
为了使模型简单信道增益分布我们采用最简单的伯努利分布,也就是信道状态只有好和坏的状态,用0代表信道堵塞,1代表信道状态良好,其分布概率为:
只要数据包的到达不是无记忆的(连续情况下泊松分布、离散情况下几何分布),那么发送速率与数据包的到达必然是相关的。
为了使模型简单,我们采用伯努利到达。第 个时隙初的数据包的个数
的分布概率为:
为了使模型简单,我们假设发送过程也是符合伯努利分布的,也就是采用0-1发送策略,要么发一个包,要么不发。
- 当
,也就是不发送时,认为传输功耗为0;
- 当
时,信道状态好和坏情况下所需要的传输功耗设为
。

由上述假设,我们可以得到缓存的数据队列的长度 满足如下更新方式:
其中, 为第
个时隙结束时移动设备缓存中的数据包个数,
为移动设备缓存的大小(最多能存放多少数据包)。
本工作的目标就是通过在每个时隙动态地调整 或者
,在给定平均功率约束下
,最小化平均时延。平均功率可以表示为:
在这里代表任意一种调度策略。利用Little定理,平均排队延时可以表示为:
根据此可以发现一个很直观的结论,即移动设备缓存中数据包个数越多,则会产生更高的排队延时。另一方面,根据之前队列更新公式,可以发现让 保持为1,也就是发送数据包可以降低
的值。
上述优化问题可以表示为:
可能部分读者看到这里已经会觉得有点乱,但这已经是最最简单的情况了。更简单地来说,我们需要做的是,根据系统状态(包括缓存状态 ,任务包到达
和信道状态
)来决定当前时隙是否需要发送,即
或者
。
在这里我们不再用线性规划的方法去求解,我们采用拉格朗日松弛,将受限的马尔科夫决策过程(CMDP)转化为马尔科夫决策过程(MDP)。
定义环境状态为 ,给定环境状态后的策略分布可以定义为:
也就是,每一种系统状态,都不会是一个确定的 ,而是按照概率
来随机选择
的取值。例如
代表各以50%的概率选择
和
。
每次在某个状态下采取是否发送的动作,会影响队列长度,跟消耗的功率。如果在某个状态下发送文件,便会减小队长,但是会消耗功率。并且在不同的状态下发送文件所需要的功率是不一样的。我们在功率受限的情况下去最小化平均时延,这是一个受限的马尔可夫决策过程(CMDP)。
既要优化时延,又不能让总的平均功率超过限制,这里的优化目标便有了两个。将两个目标按照某个比例加权,这样去优化,便可得到最优tradeoff上的某个点,换不同的比例去优化,便可以得到不同的的点,这里见结果部分。所以,我们有如下的方法将受限的马尔科夫决策过程(CMDP)转化为马尔科夫决策过程(MDP)。
应用拉格朗日松弛,定义 为拉格朗日乘子,那么我们有
由于 是常数,所以我们可以再简化为
我们代入时延与功率的表达式,可以得到
再变换一次,将 这个常数去掉,将min 换成max,那么我们可以得到
这个式子可以看做是无折扣、无限时长MDP问题的最大化回报函数的公式了!那么我们可以定义,相应的环境值函数 与动作值函数
以及动作回报函数
:
到这里我们就可以看到这是一个无限长时间、无折扣的模型,对于每一个状态都有一个值函数.对于这个状态上 ,采取某个动作后立即获得一个回报值,然后就可以根据上式来更新动作值函数与环境值函数。这便成为一个没有限制的MDP问题了!

到这一步,我们便得到了这个问题的贝尔曼方程,那么便可以利用强化学习中的最基本的值迭代或者是策略迭代来求解这个问题了。
值迭代:
- 给一个随机的环境值函数的初值
- 在任意一个时隙内
- 对于所有的环境状态采用贪婪的方式改进策略
- 改进策略评估,至值函数收敛
- 重复上述算法直至收敛到一个确定性策略
通过值迭代的算法,可以解出图中的转折点来,在文献[4]中证明了转折点的策略是一个确定性的门限策略,而非转折点的策略是相近的确定性策略的概率组合。
对于值迭代,
- 只能解出图中的转折点来,通过改变不同的拉格朗日乘子可以得到不同的转折点。这一点就类似于多目标规划,通过不同比例的线性可以得到不同的最优Tradeoff。
- 值迭代得到的最优策略是一个确定性的策略,也被证明了是一个具有门限性质的确定性策略。

来源:知乎 www.zhihu.com
作者:Skyfall
【知乎日报】千万用户的选择,做朋友圈里的新鲜事分享大牛。 点击下载
本文章由 flowerss 抓取自RSS,版权归源站点所有。