update
arms3. BFS prakticky https://is.mendelu.cz/eknihovna/opory/zobraz_cast.pl?cast=19950
4. AVL prakticky https://ksp.mff.cuni.cz/kucharky/vyhledavaci-stromy/ https://www.itnetwork.cz/algoritmy/vyhledavani/avl-strom-datova-vyhledavaci-struktura
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
ITERATIVNI PROHLEDAVANI DO HLOUBKY - Iterativní prohledávání do hloubky (Depth-first iterative deeping)
Algoritmus iterativního vyhledávání kombinuje výhody vyhledávání do hloubky
a do šířky. Je nejvýhodnější variantou mezi neinformovanými algoritmy pro vyhledávání ve velkých stavových prostorech s neznámou hloubkou. Algoritmus
začíná vyhledávat stejně jako algoritmus vyhledávání do hloubky s tím, že
v každé iteraci roste hloubka prohledávání o jedničku a první nalezené řešení je
automaticky označeno za optimální. Výhodami tohoto algoritmu je optimálnost,
úplnost a nízké paměťové nároky. Za nevýhodu lze označit neznalost jak určit
limit prohledávání, při zadání příliš malé hloubky, do které má algoritmus vyhledávat, nedospějeme k cíly. Naopak, jestliže je zadána moc velká hloubka, bude docházet i k prohledávání slepých listů, což povede ke zpomalování chodu algoritmu.
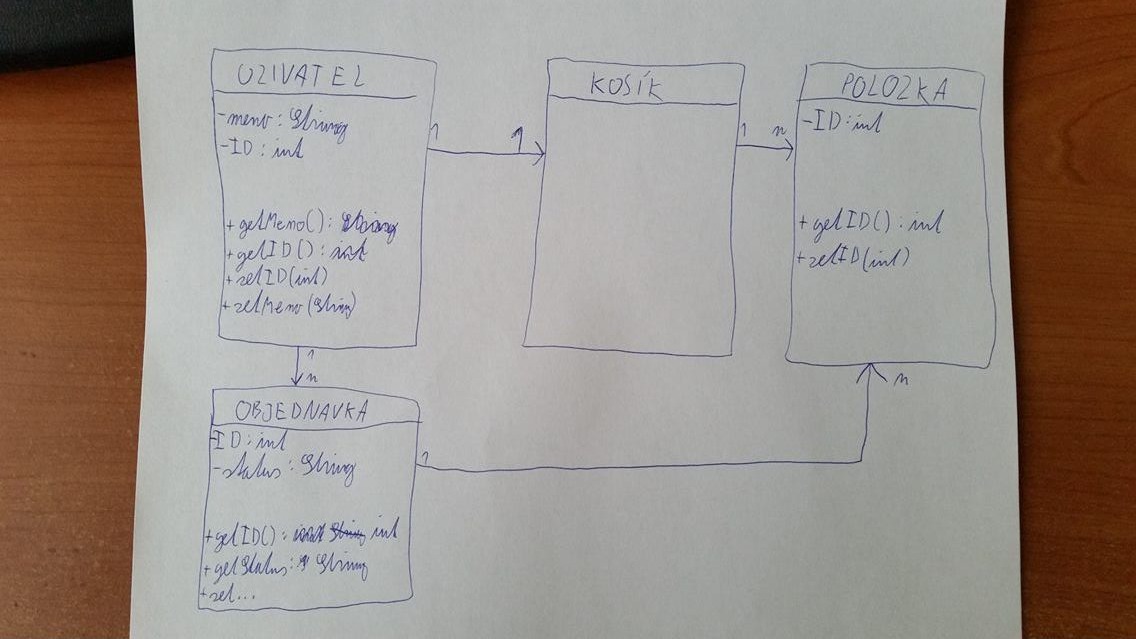
5. UML popis + obrázok trieda, atributy, metody, vzťahy - na listochke. https://habr.com/post/150041/ http://gameinstitute.ru/resources/lessons/uml/1-obzor-yazyika-proektirovaniya-uml/


6. P-NP - nevim.
7. Návrh riešenia polynomickej rovnice ax^m+by^n=z pri známych kombináciach x,y,z pomocou genetických algoritmov


DEIKSTRA = https://www.youtube.com/watch?v=gdmfOwyQlcI
KRASKAL = https://www.youtube.com/watch?v=vm_9-vnV7PE&t=1s
TURINGUV STROJ = https://www.youtube.com/watch?v=s7R8HXpgiHA
Princip evolučních algoritmů
Ukažme si princip evolučních algoritmů rovnou na praktickém příkladu. Řekněme, že potřebujeme optimalizovat přepravu mezi logistickými centry a prodejnami. Na vstupu máme schéma dopravní sítě a neustále se aktualizující požadavky na přepravu zboží. Očekávaným řešením úlohy je plán přepravy, tj. informace o tom, která vozidla mají v jakém pořadí, odkud a kam přepravovat požadované zásilky. Snažíme se přitom minimalizovat počet najetých kilometrů a počet úkonů typu nakládka/vykládka. Různým zásilkám bychom také mohli přiřadit různou prioritu.
Řešení – tedy v našem případě plán přepravy – zakódujeme do číselné podoby. Obecně může mít řešení podobu jednoho čísla nebo skupiny čísel (vektoru, matice). Dále budeme pro jednoduchost předpokládat, že naše řešení lze zakódovat do desetimístného binárního čísla.
Vrátíme-li se k biologické analogii, tak každé číselně vyjádřené řešení představuje jednoho jedince. V prvním kroku náhodně vygenerujeme sadu řešení, tj. jedince naší populace. Mohou jich být třeba i stovky či tisíce.

Křížení jedinců provedeme tak, že náhodně vybereme dva jedince (rodiče) a zkombinujeme jejich části do nového jedince (potomka).

Mutace pak bude spočívat ve změně jednoho bitu na opačný (tedy z nuly na jedničku či naopak).

Jak křížení, tak mutace vedou k vytváření nových řešení. Má-li algoritmus směřovat směrem k úspěšnému výsledku, tak je potřeba zajistit, aby křížení probíhalo s výrazně vyšší četností nežli mutace. Časté mutace by totiž vedly k ničení pokročilých stádií řešení. Kdyby ale k mutacím nedocházelo vůbec, tak by naopak hrozilo, že by řešení stagnovala. Mutace je zvláště důležitá v situacích, kdy se zadání úlohy během jejího řešení mění – v našem případě musí algoritmus operativně reagovat např. na průběžně zadávané nové požadavky na přepravu či na změnu priorit zásilek.
U každé úlohy musíme říci, jak budou řešení ohodnocována, tedy jak bude posuzováno, který jedinec je zdatnější. V našem případě bychom řešení hodnotili podle požadavků daných v zadání úlohy – tj. dle počtu najetých kilometrů, počtu nakládek/vykládek a respektování přednosti prioritních zásilek. Algoritmus pak lépe hodnocená řešení, tj. zdatnější jedince, nějakým způsobem zvýhodňuje. Např. se jim s vyšší pravděpodobností umožní křížení anebo se jim zvýší šanci na přežití – řekne se např. že do další generace přežije určité procento nejzdatnějších potomků anebo že lepší potomek vytěsní horšího rodiče.
Takto se postupuje generaci za generací. Konec algoritmu může být určen dopředu daným počtem generací, dosažením určité kvality nejlepšího jedince anebo malou změnou nejlepšího jedince za posledních několik generací.
Evoluční algoritmy jsou schopny přibližně řešit úlohy, jejichž exaktní řešení není v našich výpočetních silách, je extrémně časově náročné anebo vyžaduje lidskou intuici. Tyto algoritmy využívají principů známých z evoluční biologie, zejm. pak Darwinova principu přežití silnějšího.
Namísto toho, aby bylo exaktním nebo randomizovaným algoritmem budováno jedno výsledné řešení problému, je v evolučních algoritmech udržována celá populace kandidujících řešení. Tato řešení jsou posupně šlechtěna, např. po generacích. V každé generaci jsou určitým způsobem vybrána nejlepší řešení a tato řešení jsou pak křížena a mutována.
Tímto principem jsou často nalezena vysoce kvalitní řešení daných problémů – bez nutnosti toho, aby člověk musel vymýšlet specializovaný algoritmus, jak daný problém řešit! Jediné, co algoritmus potřebuje vědět, je, která řešení jsou silnější a která slabší. To je pro celou řadu triviální určit, zatímco vyrobit dobré řešení může být nepřekonatelně obtížné.
2) Minimalni kostra grafu, delas matice vseh, a pak hledash minimalni.
https://www.youtube.com/watch?v=vm_9-vnV7PE
5. Strana 178 skript.
Pro zjištění úspěšnosti klasifikačního algoritmu existují různé ukazatele správnosti. U testovací množiny dat je nutné znát zařazení subjektů do předem daných tříd. Pak můžeme porovnat výsledek zařazení subjektů klasifikátorem se skutečností a získáme tak tzv. matici záměn. Matice záměn je matice, ve které každý prvek na pozici i,j popisuje počet objektů patřících do třídy i, kterou klasifikátor zařadil do třídy
6) Iterativní prohlubování je vlastni omezené prohledávání do hloubky, pro které se postupne zvetšuje
maximální hloubka, do které se prohledává. Prohledává se tedy (do hloubky) nejprve stavový prostor hloubky 1, pak do hloubky 2, pak do hloubky 3 atd. Tato varianta dokáže odstranit i druhý problém klasického prohledávání do hloubky, nebo nalezne optimální rešení (pokud existuje)
https://www.algoritmy.net/article/5108/Dijkstruv-algoritmus
https://www.algoritmy.net/article/30/Zasobnik
https://ksp.mff.cuni.cz/kucharky/vyhledavaci-stromy/
https://www.algoritmy.net/article/28/Fronta
2. TS, popis, druhy -
NEDETERMINICKY TS = STROJ Z NEKONECNOU PARALELIZACE, v libovolni cas stroj muze byt v ruznych stavu.
Konečný automat s nekonečnou páskou – na pásce je napsaný vstup, symboly na pásce lze libovolně přepisovat, po pásce se lze pohybovat oběma směry , je možné měnit vnitřní stav
Konečný automat neměl žádnou paměť
jen konečný počet stavů • Zásobníkový automat mělnekonečný zásobník s přístupem pouze k symbolu na vrcholu. Turingův stroj má nekonečnou pásku s přístupem kamkoliv. Je to zjednodušený model počítače – tzv. “výpočetní model”
– model jakéhokoliv možného výpočtu
• Má jasnou formální definici umožňující dokazovat (ne)řešitelnost problémů
• Je formálním ekvivalentem vágně definované “algoritmické řešitelnosti”
• Cílem je ukázat, že existují problémy neřešitelné pomocí počítače
Turingův stroj čte symboly ze vstupní pásky
• Na základě vnitřního stavu a čteného symbolu
TS podle přechodové funkce
– změní svůj vnitřní stav
– zapíše na pásku nový symbol
– posune čtecí hlavu doleva, nebo doprava
• Vstupní páska je jednosměrně nekonečná
– Zaplněno je vždy jen konečně mnoho políček
– Ostatní políčka obsahují prázdný symbol ⊥
• Výpočet TS končí, jestliže se stroj dostane do
některého ze stavů qA, qR.
Nedeterministický TS může mít v každém kroku
na výběr několik možností
• Podobně jako u DTS definujeme i u NTS relaci
• Všechny možnosti výpočtu TS lze popsat
stromem (tzv. výpočtový strom), jehož uzly
jsou konfigurace, kořen je počáteční
konfigurace a listy jsou koncové konfigurace

1. LIFO, obrázok, popis, metóda Add
Zásobník
Datová struktura sloužící k odkládání dat. Je typu LiFo – last in,
first out, což znamená, že prvek, jenž přišel do zásobníku jako první,
bude vyjmut jako poslední a prvek, jenž byl uložen jako poslední bude
vyjmut jako první,
Při deklaraci pomocí lineárního seznamu je práce obdobná, vytvoříme
si ukazatel vrcholu zásobníku, který bude ukazovat na místo v paměti,
kde se nachází první prvek. Ten je strukturovaného typu, proto má
uloženou nejen hodnotu, ale i ukazatel na další prvek. V takto
vytvořeném zásobníku se sice můžeme pohybovat pouze jedním
směrem, ale to v tomto příkladu není na škodu.


http://dl4.joxi.net/drive/2018/05/05/0002/2847/170783/83/db90776e90.jpg
LI: Vytvoříme si proměnnou typu struktura zásobníku, do ní přiřadíme
hodnotu a pak musíme změnit ukazatele, aby na prvek, na který
ukazovala pomocná vrch ukazoval nově přidaný prvek a na něj vrch, viz
lineární seznamy.
Fronta
Datová struktura sloužící k odkládání dat. Je typu FiFo – first in,
first out, což znamená, že prvek, jenž přišel do fronty jako první, bude
vyjmut jako první a prvek, jenž byl uložen jako poslední bude vyjmut jako
poslední, viz obrázek.

V lineárním seznamu musíme mít taktéž dva ukazatele, první ukazatel
vrchol ukazuje na místo v paměti, kde je vrchní prvek, tedy ten, co se
načítá, mezitímco ukazatel konec ukazuje na místo v paměti, kde je
uložen prvek, který přišel jako poslední. Mezi těmito hranicemi se
pohybujeme pomocí ukazatelů jednotlivých struktur.
Přidání prvku do fronty:
Zkontrolujeme, zda-li ukazatele vrch a konec neukazují na místo
v paměti kde je hodnota null. Pokud ano, tak se ukazatelé vrch a konec
budou odkazovat na nově přidanou strukturu a ta na NIL.
Pokud fronta není prázdná, tak struktura, na kterou dosud ukazoval
ukazatel konec bude ukazovat na nově přidanou strukturu, ta na NIL a
ukazatel konec na nově přidanou strukturu.

1) int sucet = 0;
while(last != null) {
sucet += last.getValue();
last = last.getPrevious();
}
2) Princip metody podpůrných vektorů (Support Vectores Machines – SVM) je založen na
rozdělení dat, reprezentovaných vektory v mnohodimenzionálním příznakovém
prostoru, do dvou skupin (tříd) s pomoci lineárního klasifikátoru – roviny [7].
Pojmenování SVM je odvozeno od tzv. podpůrných vektorů (support vectors).
Tímto termínem jsou míněny vektory nacházející se nejblíže stanovenému lineárnímu
klasifikátoru. Vizuální zobrazení je vidět na Obr. 3.3, kde jsou vektory znázorněny body
v kroužku (vzhledem k 2D zobrazení jsou vektory promítnuty do jednotlivých bodů).
Podpůrné vektory jsou nejdůležitější částí dat, dle kterých je určena poloha roviny
v prostoru. Je-li použita analogie k váhování, podpůrným vektorům je dána nejvyšší
váha [8]. Tj. mají vyšší vliv na klasifikaci než vektory nacházející se ve vyšší
vzdálenosti od roviny.
Na Obr. 3.3 lze vidět, že podpůrné vektory leží na přerušovaných přímkách. Tyto
přímky označují okraje prázdného prostoru (margin, v separovatelném případě se jedná
o tzv. „hard margin“) mezi třídami.
b] Jejich nevýhodou však je èasto velmi
obtížné uèení, protože prakticky vždy existuje riziko uvíznutí v lokálním minimu
chybové funkce a navíc je uèení silnì komplikováno hledáním vysokého poètu vah
v mnohadimensionálním prostoru.
K alternativním, relativnì novým metodám patøí podpùrné vektory (support vector
machines, SVM), které tvoøí urèitou kategorii tzv. jádrových algoritmù (kernel machines).
Tyto metody se snaží využít výhody poskytované efektivními algoritmy
pro nalezení lineární hranice a zároveò jsou schopny representovat vysoce složité
nelineární funkce. Jedním ze základních principù je pøevod daného pùvodního
vstupního prostoru do jiného, vícedimensionálního, kde již lze od sebe oddìlit tøídy
lineárnì.

3) KRUSKAL.
6)



Mějme lineární seznam. Vytvořte metodu "vložPrvni", která vloží prvek na začátek seznamu.
public void vlozPrvni(int hodnota) {
Uzel u = new Uzel();
u.setData(hodnota);
u.setNasledovnik(prvni);
prvni = u;
}
Mějme lineární seznam. Napište metodu "vypisHodnoty", který vypíše všechny hodnoty, které se v lineárním seznamu vyskytují.
Uzel u = prvni;
while(u != null) {
System.out.println(u.getData());
u = u.getNasledovnik();
}
DFS - https://www.youtube.com/watch?v=Tzc7Z-mOwxY
BFS -
~~~~~~~~~~~~~~~~~~~~~~~




Uvaznuti - deadlock
Pokud je ve viceulohovem systemu jednomu procesu pridelena tiskarna a druhemu magneticka paska a potom prvni z procesu pozada o prideleni pasky a druhy tiskarny, zadny z techto procesu nemuze pokracovat v behu. Teto situaci rikame uvaznuti neboli deadlock. Resenim teto situace je odebrat jednomu z procesu prostredek, ktery pozaduje druhy proces. Vetsina operacnich systemu vsak nasilne odebrani prostredku nedovoluje.
Uvaznuti (deadlock) - je situace, kdy dva nebo vice procesu cekaji na udalost, ke ktere by mohlo dojit pouze pokud by jeden z techto procesu pokracoval (vyreseni dopravni situace couvanim).
Podminky uvaznuti
K uvaznuti muze dojit jenom pokud jsou splneny vsechny ctyri nasledujici podminky:
- Vylucny pristup (mutual exclusion). Existence prostredku, ktere jsou pridelovany pro vyhradni pouziti jednomu procesu, tj. nesdilitelnych prostredku.
- Postupne pridelovani prostredku (hold and wait). Procesy nezadaji o prideleni vsech prostredku najednou, ale postupne. Pokud pozadovany prostredek neni volny, musi proces cekat.
- Pridelovani prostredku bez preempce. Pridelene prostredky nelze procesu nasilim odebrat.
- Cyklicke cekani.

3) http://labe.felk.cvut.cz/~posik/pga/theory/pga-theory.htm - parallelizace GA
Prohledávání do šířky (Breadth-first search)
U prohledávání do šířky, se od uzlu, označeného za počáteční prohledávají
všichni jeho sousedé, kteří jsou následně uloženi do fronty. Z fronty se vybere
první uzel, u kterého se opět prohledají sousedé jako u počátečního, mimo ty,
kteří již byli prozkoumáni. Tento postup se opakuje dokud fronta není prázdná.
(Algoritmy.net, 2008) U popisů algoritmů se vyskytují pojmy OPEN a CLOSED. Pojmem OPEN se rozumí seznam neexpandovaných uzlů, pojmem CLOSED seznam expandovaných uzlů. Algoritmus lze popsat následujícím způsobem:
1. Zapiš počáteční stav do seznamu OPEN, seznam CLOSED je prázdný. Jeli
počáteční stav současně stavem cílovým, ukonči vyhledávání.
2. Pokud je seznam OPEN prázdný, řešení neexistuje, ukonči vyhledávání.
3. Vymaž první stav (označíme jej i) v seznamu OPEN a zapiš tento stav do
seznamu CLOSED.
4. Expanduj stav i. Pokud tento stav nemá následovníky nebo všichni následovníci
byli již expandováni (tj. jsou v seznamu CLOSED), pokračuj
krokem č. 2.
5. Zapiš všechny následovníky stavu i, kteří nejsou v seznamu CLOSED, na
konec seznamu OPEN.
6. Pokud některý z následovníků stavu i je cílovým stavem, řešení bylo nalezeno,
ukonči vyhledávání. Jinak pokračuj krokem č. 2. (Mařík V., 1993)
Jestliže existuje cesta k cíly, musí být algoritmem nalezena a to vždy ta nejkratší.
Nevýhodou je však expandování neúměrného množství uzlů, než dosáhneme
cíle a s tím je spojená vysoká paměťová náročnost. Algoritmus prohledávání do
šířky má asymptotickou časovou složitost O(|U|+|H|), kde U je počet uzlů a H
počet hran.

Prohledávání do hloubky (Depth-first search)
Během prohledávání se mění stavy uzlů. Na začátku jsou všechny uzly označeny
jako nové, jestliže do uzlu vstoupíme, změní se označení na otevřený. Jestliže
přes uzel provede návrat je označen za zavřený. Algoritmus se vždy nachází
v nějakém vrcholu, který nazveme aktuální. Algoritmus vybere hranu vedoucí
z aktuálního vrcholu a je-li následný vrchol označen za nový, prohledávání pokračuje
do hloubky k dalšímu uzlu, který se stane aktuálním. Do starého aktuálního
uzlu se algoritmus vrátí až po prohledání nového aktuálního uzlu. Pokud
hrana vede k jinému vrcholu než novému, tato hrana se přeskočí. Nevyskytují-li
se již v grafu žádné nové vrcholy, je aktuální uzel označen za zavřený
a algoritmus provede návrat do uzlu ze, kterého přišel.
Algoritmus lze popsat následujícím způsobem:
1. Zapiš počáteční stav do seznamu OPEN, seznam CLOSED je prázdný.
Je-li počáteční stav současně stavem cílovým, ukonči vyhledávání.
2. Pokud je seznam OPEN prázdný, řešení neexistuje, ukonči vyhledávání.
3. Vymaž první stav (označíme jej i) v seznamu OPEN a zapiš tento stav do
seznamu CLOSED.
4. Expanduj stav i. Pokud tento stav nemá následovníky nebo všichni následovníci
byli již expandováni (tj. jsou v seznamu CLOSED), pokračuj krokem č. 2.
5. Zapiš všechny následovníky stavu i, kteří nejsou v seznamu CLOSED, na
začátek seznamu OPEN. ukonči vyhledávání. Jinak pokračuj krokem č. 2.
Výhodou algoritmu prohledávání do hloubky je menší paměťová složitost, oproti
prohledávání do šířky. Výhoda spočívá v uchovávání pouze uzlů od expandovaného
k počátečnímu. Časová složitost je rovna O(|U|+|H|), kde U je počet uzlů
a H počet hran. Za nevýhody jsou považovány neoptimalita řešení, to znamená,
že nemusí být nalezena vždy nejkratší cesta. Při existenci nekončené větve nedojde
k nalezení cíle.
