Тестовое задание
Вопрос 1.
Для того, чтобы максимизировать пользу от занятий спортом, полезно знать, что, из того что мы привыкли делать, позволяет сжечь больше калорий.
Для этого я сначала построил матрицу корреляций признака calories_burnt с другими, которые должны оказывать на него влияние.
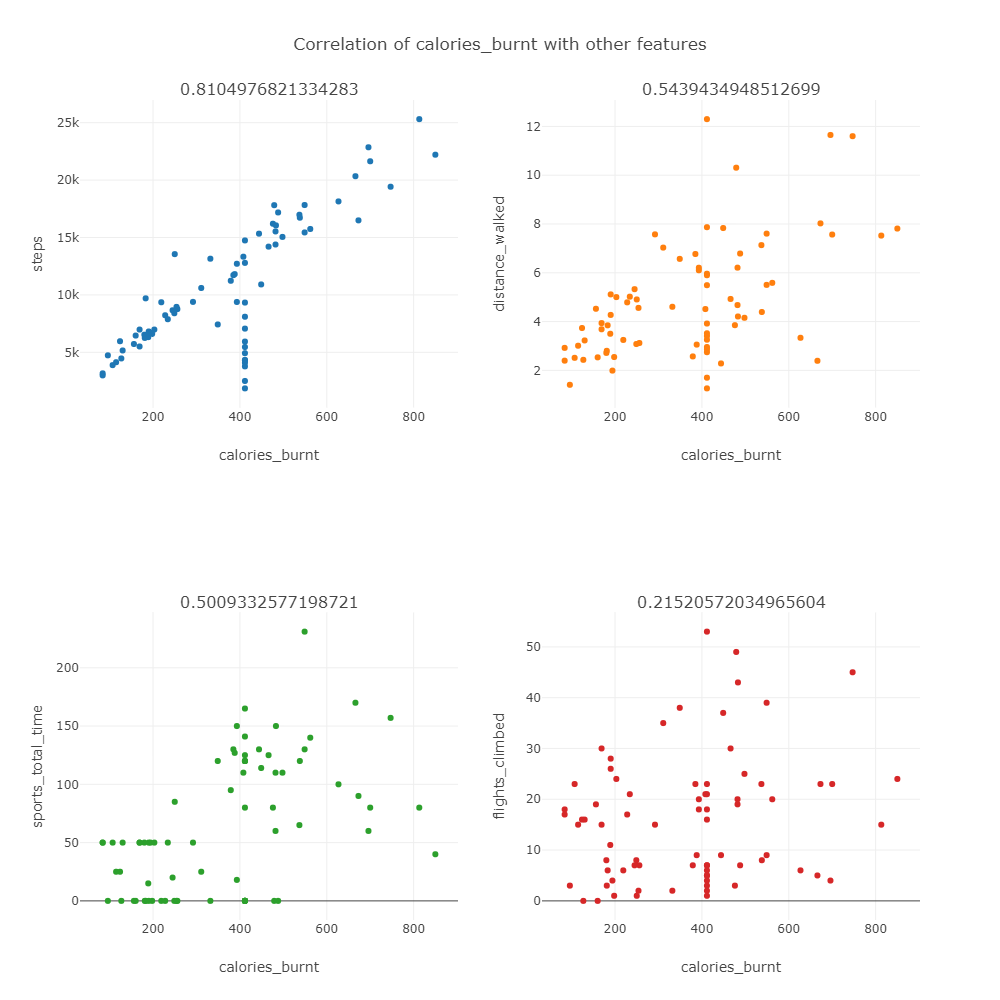
Во-первых, видно, что зависимость между количеством пройденных шагов почти линейна, при этом общее время занятий спортом не так явно влияет на количество сжигаемых калорий.
Во-вторых, на первой диаграмме отчетливо видно, что несколько значений признака calories_burnt выбиваются из общего распределения. Дело в том, что первые 11 значений одинаковы и дробны, в то время как остальные целые. Видимо это результат заполнения пропусков в данных средним значением. По возможности, не будем учитывать эти данные при работе с calories_burnt
Разумеется спорт влияет на сжигаемые калории, проблема в том, что данные о занятиях спортом имеют много пропусков в отличие от количества пройденных шагов. Для того, чтобы выяснить какой тип занятий позволяет сжечь больше калорий, сначала посмотрим какие вообще виды спорта представлены в выборке.

Имеет смысл сравнить велосипед и баскетбол, так как по остальным видам спорта выборка совсем нерепрезентативна.

С помощью t-теста мы также можем отвергнуть нулевую гипотезу о равенстве средних этих двух выборок.

В среднем занятия баскетболом позволили сжечь больше калорий чем велосипед, однако видно, что пики числа пройденных шагов, часто совпадают с днями занятий баскетболом, и это могло повлиять на число сожженных калорий. Например если вычислить среднюю стоимость шага в калориях по дням, где занятий спортом вообще не было, можно оценить количество сожженных калорий без учета ходьбы.

Теперь отвергнуть гипотезу о равенстве средних не получается.

Таким образом, если во время игры в баскетбол человек делает много шагов , что и приводит к пикам этого признака, а во время езды на велосипеде не делает вообще, то можно считать, что баскетбол сжигает калории лучше.
Что касается полноты и качества данных, то помимо уже упомянутых выше проблем, стоит отметить, что в датасете присутствуют данные только за весенний период, поэтому мы не можем провести такое же сравнение например с зимними видами спорта.
Вопрос 2
По-моему, наибольший интерес представляют данные такого рода о большом количестве людей. Это бы позволило построить модель, способную давать рекомендации по изменению образа жизни, интенсивности и вида тренировок, режима дня и т.д., для достижения тех или иных целей, на основании опыта других людей. Например:
Пользователь хочет избавиться от лишнего веса. На основании этих данных, мы можем найти людей похожих на него не только по физиологическим параметрам, но и по образу жизни , предпочтениям и т.д. Среди этих "похожих" людей можно найти тех, кому удалось сбросить лишний вес. Теперь осталось только порекомендовать пользователю вести себя так же как и эти "успешные".
Это могут быть рекомендации заняться тем или иным спортом, изменить режим дня или увеличить количество прогулок в день.
Искать похожих людей можно разными способами. Самый простой способ это преобразовать множество временных рядов описывающих каждого пользователя в вектор признаков. (например усредненные значения и признаки некоторым образом характеризующие всю его историю). Тогда можно просто вычислять расстояние по какой-нибудь метрике (например cosine-similarity), однако при таком большом количестве признаков это вряд ли принесет хороший результат. Куда лучше будет воспользоваться одним из методов понижения размерности.
Вернемся к предоставленному нам датасету с историей одного пользователя.
Когда пользователь накопил достаточно большую историю о себе, можно использовать эти данные, чтобы предсказывать значения в будущем. Например с помощью рекуррентных нейронных сетей. Таким образом можно заранее предупреждать пользователя к чему приведет его текущий образ жизни, и давать рекомендации по его улучшению.
Вопрос 3
Сегментацию так же было бы интересно проводить на множестве людей. Разбиение на кластеры это один из способов найти похожих.
Однако здесь объектами являются дни. Как вариант можно разбить дни на активные и неактивные. Для наглядности будем делать разбиение по 3-м признакам 'steps', 'sports_total_time' и 'flights_climbed'. Поскольку объектов и кластеров тут совсем немного, простой KMeans справится с этой задачей.
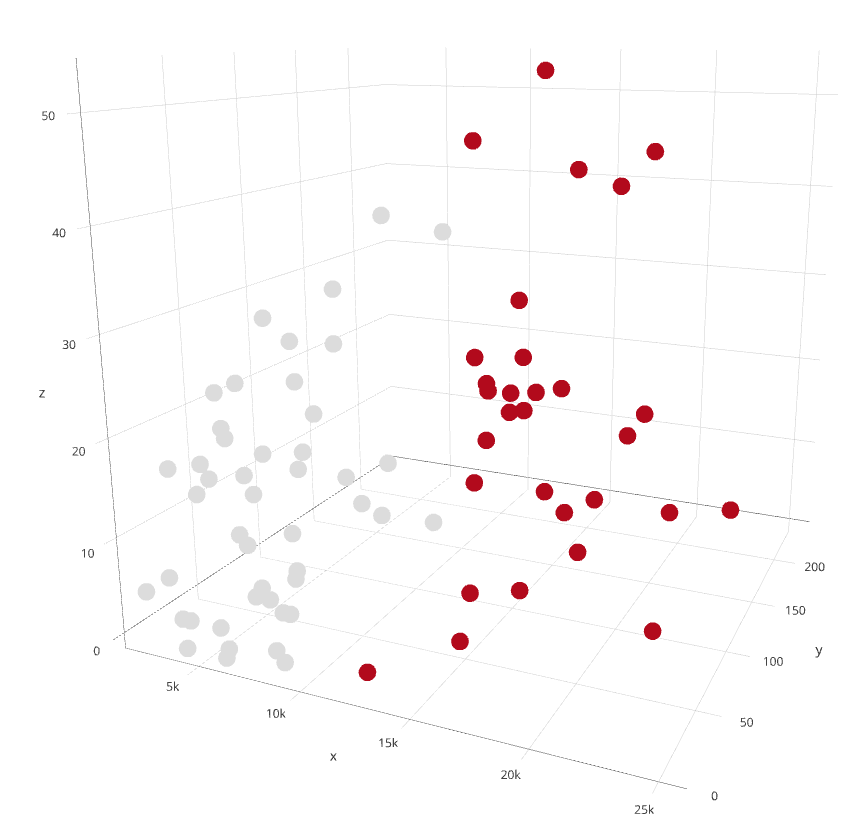
Логично, что неактивные дни должны располагаться ближе к началу координат, а активные дальше. Но чтобы убедиться, можно сравнить с раскраской где насыщенность соответствует количеству сожженных калорий - признаком, имеющим отношение к активности, но не участвовавшем в кластеризации.

Такое разбиение позволяет, например, добавить еще один бинарный признак в датасет.