Путеводитель по лжи
Часть 1. Оценка цифр
Правдоподобие
Самое базовое в критическом мышлении это прикинуть насколько утверждение вообще правдоподобно. Вот пример:
Каждый год в США от анорексии умирает 150 тысяч девушек и молодых женщин.
Согласно данным американских Центров по контролю и профилактике заболеваний, ежегодное количество смертей девушек и молодых женщин в возрасте от 15 до 25 от всех видов заболеваний — 8500. Добавьте сюда женщин от 25 до 45 — показатель все равно достигнет только 55 тысяч. Количество случаев смерти от анорексии за год не может превышать в три раза количество всех смертей.
Нередко достаточно просто на листке посчитать цифры и заметить, что ничего не сходится.
Разные средние
Это вообще крайне забавно, что люди, несмотря на обучение в школе и ВУЗах, абсолютно не понимают, что такое среднее. Вспоминая школьную программу математики, мы знаем, что никакого среднего не существует. Есть среднее арифметическое, мода, медиана. Манипуляция состоит в том, что, слыша среднее люди думают, что речь о среднем арифметическом, что далеко не всегда так. Более того, среднее арифметическое не всегда лучший способ для понимания реальной картины. Оно сильно подвержено выбросам: допустим, когда говорят, что средняя зарплата по области 700 долларов, это ещё не значит, что в основном люди столько получают. Это может быть при повальном заработке 200 долларов и пару «выбросов»-людей с огромными доходами. Для отображения «средней зарплаты» куда практичнее использовать медиану (половина людей будет получать меньше этой суммы и половина больше) или моду (наиболее часто встречающиеся значения). Важно держать в голове эти отличия и выбирать наиболее подходящее, иначе кончится тем, что «средняя температура по больнице 36,6».
Махинации с осями координат
Необозначенные оси координат
Распространённый пример. Не подписывая оси координат невозможно понять, что действительно происходит и мозг только по визуалу делает выводы, что не надежно совершенно. Если с осью Х можно догадаться что это года, то ось Yабсолютно непонятно. Это проданные экземпляры или прибыль в долларах? Если прибыль, то сколько? Может это рост продаж с пяти центов до 5 долларов в год, а может с 50 миллионов до 500 миллионов.
Усеченная вертикальная ось
Если хотите показать реальное положение дел, то в случае, если измеряемое количественное множество может иметь значение 0, то именно с нулевого значения и должен строиться график. Если хотите манипулировать, то начните график с нижней границы своих значений.
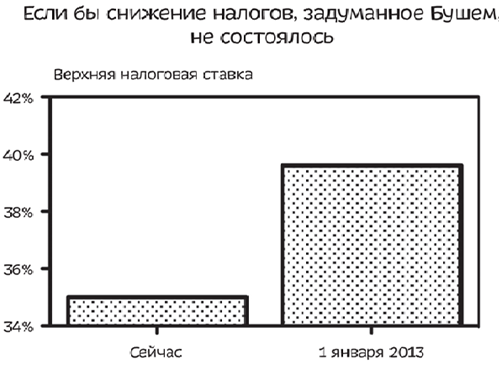

На первой картинке мы видим разницу в высоте столбцов в 6 раз (или же на 600% выше правый столбец), когда на второй картинке разница в высоте всего 13%.
Разрыв осей

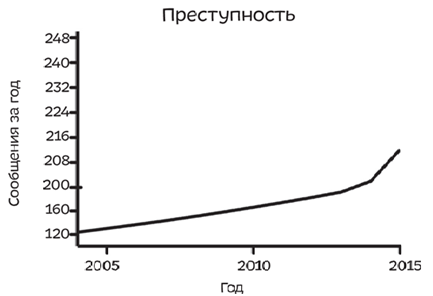
Не сразу бросается в глаза, но тут разорвали ось Y. Сначала был шаг в двадцать сообщений, потом пошел шаг в 8. Внимательно смотрите на значения на осях графиков. Легко манипулировать визуально резким скачком.
Выбор масштаба и оси
Примером будет выступать повышение цена на дома на 15 процентов в год.
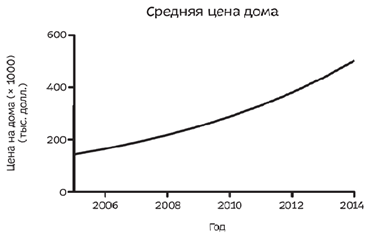
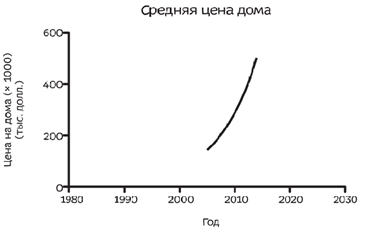
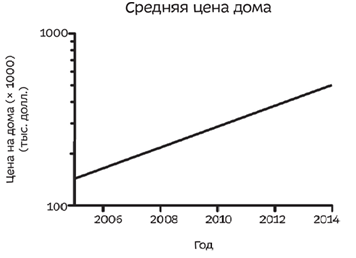
3 графика выше отображают одинаковые данные. Первый график наверное тот, который по стандарту сделает человек в Excel (потому что нажмет на мастера диаграмм). Второй график уже сделан с целью устрашения, нашему мозгу кажется из-за сильного наклона, что рост цен идет прямо-таки экспоненциально. Третий график (мой любимый тип) в логарифмическом масштабе. Суть его заключается в том, что постоянное изменение на одинаковые проценты изображается одинаковыми промежутками на оси Y. Он наиболее точно отображает реальную картину.
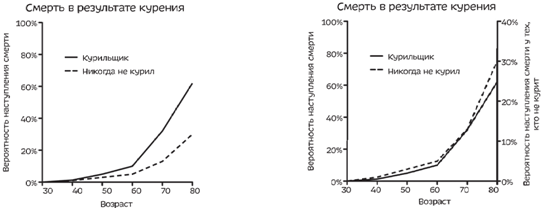
Двойная ось
Играя с разными масштабами осей мы доказали только что, что курение не влияет на шанс смерти (по крайне мере именно так большинство поймет график).
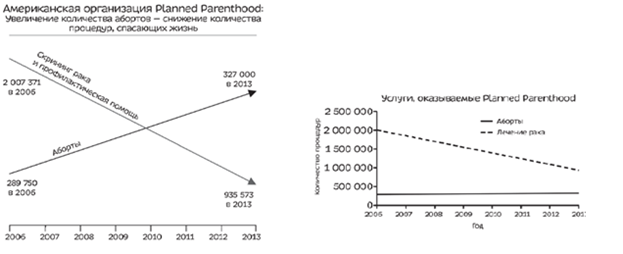
Тут тоже становится ясно, что авторы первого графика хотели запугать людей тем, что аборты делают чаще, чем скринниг рака.
Если у нас падают квартальные продажи, то можно сделать так, чтобы график пошел вверх сделав график кумулятивных продаж (общее количество продаж). Если наклон становится меняя крутым, то надо понимать, что произошла просадка.
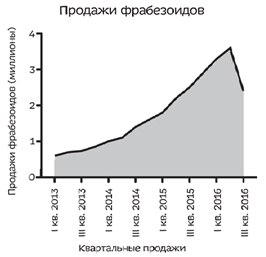
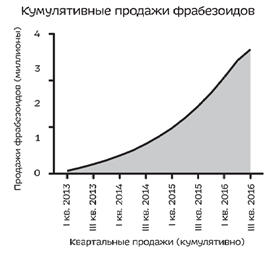
Вот Тим Кук также показывает продажи iPhone. Нашему глазу сложно оценить такой наклон мгновенно, поэтому относитесь осторожно к графикам кумулятивным.

Возможные уловки при сообщении данных
Корреляции
Если кратко: корреляция — это не причинно-следственная связь. В корреляции либо одно вызывает второе, либо второе первое, либо третий фактор влияет на первое и второе, либо вообще зависимость совпадение. http://www.tylervigen.com/spurious-correlations Тут можно посмотреть на забавные корреляции.
Обманчивые иллюстрации
Отрезают тут отнюдь не 4,2 процента.

При соблюдении масштаба всё выглядит не так фаталистически.

Доступ
Это слово должно насторожить в контексте статистики. К моему каналу имеют доступ более 60% процентов населения планеты, потому что у них всех есть возможность пользоваться интернетом. Хотя по факту только 7 человек из примерно 8 000 000 000 людей.
Выборка
Допустим есть новость «71 процент украинцев за то, чтобы играл гимн в школах по утрам». Этот заголовок значит ровным счётом ничего. Надо задаться вопросом «71% каких именно украинцев за это?» Возможно, человек опрашивал людей возле места собраний радикальных националистов и те 30 процентов всего лишь случайно рядом проходившие люди. Не любая выборка является репрезентативной, в добавок ещё надо считать сколько надо людей для определенного опроса на специальных калькуляторах, которые можно найти в интернете. Также надо обращать внимание на доверительный интервал и погрешность результата. Обычно их не указывают, поэтому можно легко посчитать самим. Принято в статистике брать доверительный интервал 95 процентов. Что означает, что 95% результатов попадут в указанный диапазон. Диапазон это +- погрешность, которую можно посчитать как +- 1.96*корень(p*(1-p)/n). К примеру, 58% опрошенных за введение реформ. Размер выборки 90 человек. +-1.96*корень(0.58*0.42/90) = +-0.1 = +- 10.2%. Что означает, что возможно меньше половины населения за реформы.
Смещение из-за правил отбора
В телеграм опросах скорее всего больше всего ответит молодежь, а в вайбере 35+ лет. Также как и спрашивать о здоровом образе жизни в кабаке будет странно (если хотите представить не в виде стратифицированного опроса, а как общий показатель населения).
Смещение выборки из-за отказа участников
Люди, которые отказываются от опроса, отличаются от тех, кто в них участвует. Поэтому репортер должен не называть тему опроса заранее или камуфлировать её. В ином случае может возникнуть ошибка пропущенных данных.
Смещение выборки из-за ответов
Люди просто могут лгать.
Определения
Все зависит от определений. Любой вопрос можно задать так, чтобы получить нужный вам ответ.
Теорема Байеса.
Моя любимая теорема, которая показывает, насколько плохо мы интуитивно чувствуем вероятности событий. Автор показал самый простой способ её применения из тех, что видел.
Предположим, что злоумышлинник пробрался накануне сорвенований в конюшню и дал лошади доппинг. Следователь обнаружил, что ДНК подозреваемого совпадает с найденной. Достаточное ли это условие для того, чтобы его обвинить? Совершенно нет. Для начала нам надо понять, какого априорная вероятность, что он мог оказаться нарушителем. Допустим отстувуют следы взлома, а это значит, что они имел нарушитель имел доступ к конюшне. Работников пускай 50, итого шанс 1 из 50, 2 процента. Вероятность совпадения ДНК 85 процентов.
Теперь настало время чертить табличку.

Мы чертим четырехчастную табличку и заполняем в первую очередь нижнюю строку под ней: один из 50 шансов за то, что подозреваемый виновен (виновен: столбец «да»), и 49 шансов из 50 за то, что невиновен. В лаборатории нам сообщили, что вероятность совпадения образов крови 0,85, — вписываем эти данные в верхнюю левую ячейку: вероятность того, что подозреваемый виновен и образцы совпадают. Это означает, что в нижнюю левую ячейку надо записать 0,15 (сумма вероятностей должна давать единицу). Совпадение образцов на 85 % означает, что с вероятностью 15 % кровь была оставлена кем-то еще, не нашим подозреваемым, — а значит, его можно оправдать. А еще есть 15 % вероятности, что следы крови оставил кто-то из оставшихся 49 человек, поэтому мы умножаем 49 на 0,15 и получаем 7,35 — вписываемэто число в правую верхнюю ячейку. Мы вычитаем его из 49, чтобы найти значение, которое запишем внизу справа.
Подозреваемый виновен при совпадении с вероятностью 0,85/8,2 = 0,1 и не виновен при совпадении с вероятностью 7,35/8,2 = 0,9.0
Мы знаем от наших судебных экспертов, что вероятность совпадения образцов волос равна 0,95. Умножив это на 1, мы получаем данные, которые вписываем в верхнюю левую ячейку, а вычитая результат из единицы, получаем значение для нижней левой ячейки. Если вероятность того, что образец совпадает с образцом лошади-жертвы, равна 0,95, то с вероятностью 0,05 образец совпадет с образцом другого животного (благодаря чему подозреваемый будет оправдан). Значит, в правую верхнюю ячейку мы вписываем 0,45 — результат умножения 0,05 на число внизу таблицы, то есть на девять.

Внизу 1 и 9 это из процентов виновности взяли прошлой таблицы. Виновен будет с вероятностью 0,68 и не виновен с вероятностью 0,32. Это уже гораздо выше, чем просто при совпадении крови.
Из этого выходит, что чем менее вероятно какое-то событие, тем больше доказательной базы надо, чтобы получить высокую вероятность. Люди склоны же считать, что везде хватит одинакового количества доказательств и как правило совсем немного.