Программирование
Людка Буфетчица1. Тип данных. Структуры данных. Классификация структур данных
Тип данных - характеристика набора данных, которая определяет:
- диапазон возможных значений данных из набора;
- допустимые операции, которые можно выполнять над этими значениями;
- способ хранения этих значений в памяти.
Структура данных (англ. data structure) — программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в вычислительной технике. Для добавления, поиска, изменения и удаления данных структура данных предоставляет некоторый набор функций, составляющих её интерфейс.
Классификация структур данных по различным признаками.
1) По сложности: простые и интегрированные.
Простые (базовые, примитивные) структуры - это такие, которые не могут быть распределены на составные части.
Структурированные (интегрированные, композитные, сложные) - такие структуры данных, составными частями которых есть другие структуры данных - простые ли, в свою очередь, интегрированные. Интегрированные структуры данных конструируются программистом.
2). По способу представления: физическая и логическая.
Физическая структура данных - это способ физического представления данных в памяти компьютера.
Логическая или абстрактная структура - это рассмотрение структуры данных без учета его представления в машинной памяти.
В общем случае между логической и соответствующей ей физической структурами существует расхождения, степень которого зависит от самой структуры и особенностей той среды, в котором она должна быть отображенной. Вследствие этого расхождения существуют процедуры, которые осуществляют отображение логической структуры в физическую, и, наоборот, физической структуры в логическую.
3). По наличию связей между элементами данных: несвязные и связные.
Несвязные структуры характеризуются отсутствием связей между элементами структуры.
Связные структуры характеризуются наличием связи. Примерами несвязных структур есть векторы, массивы, строки, стеки, очереди; примеры связных структур - связные списки.
4). По изменчивости: статические, полустатические, динамические.
Изменчивость, то есть изменение числа элементов и (ли) связей между элементами структуры.
Статические - к этой группе относят массивы, множества, записи, таблицы.
Полустатические - это стеки, очереди, деки, дерева.
Динамические - линейные и разветвленные связные списки, графы, дерева.
5). По характеру упорядоченности элементов в структуре: линейные и нелинейные.
Линейные структуры в зависимости от характера взаимного расположения элементов в памяти разделяют на структуры с последовательным распределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с произвольным связным распределением элементов в памяти (односвязные и двусвязные линейные списки).
Нелинейные структуры - многосвязные списки, дерева, графы.
6). По виду памяти, используемой для сохранности данных: структуры данных для оперативной и для внешней памяти.
Структуры данных для оперативной памяти - это данные, размещенные в статической и динамической памяти компьютера. Все вышеприведенные структуры данных - это структуры для оперативной памяти.
Структуры данных для внешней памяти называют файловыми структурами или файлами. Примерами файловых структур есть последовательные файлы, файлы, организованные разделами, В-деревья.
2. Обработка прямоугольных таблиц данных. Фильтрация, сортировка, индексирование.
Обработка прямоугольных таблиц данных.
При работе с табличным процессором на экран выводится прямоугольная таблица, в клетках которой могут находиться числа, пояснительные тексты и формулы для расчета значений в клетке по имеющимся данным.
Особенность электронных таблиц заключается в возможности применения формул для описания связи между значениями различных ячеек. Расчет по заданным формулам выполняется автоматически. Изменение содержимого какой-либо ячейки приводит к пересчету значений всех ячеек, которые с ней связаны формульными отношениями и, тем самым, к обновлению всей таблицы в соответствии с изменившимися данными.
Фильтрация таблицы оставляет на экране только те строки, которые отвечают заданным критериям, при этом остальные строки оказываются скрытыми.
Сортировка - это расположение строк в таблице в определенном порядке. Чаще всего необходимо сортировать строки по данным одного или нескольких столбцов.
Индексирование таблицы Индекс— объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путём последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска.
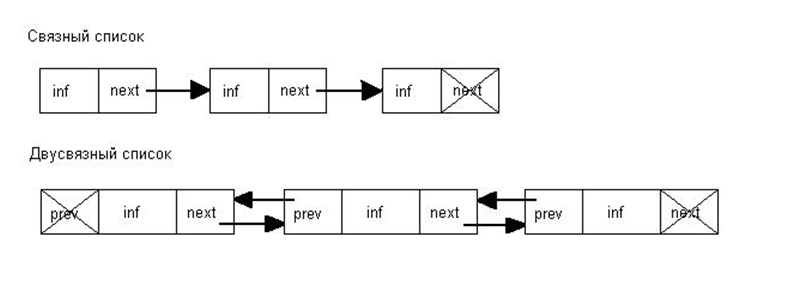
3. Линейные односвязные и двусвязные списки. Рекурсивное описание данных. Операции над списками.
Линейный список представляет собой упорядоченный набор элементов, в котором включение новых элементов и исключение существующих могут выполняться в любом месте списка. Каждый элемент списка характеризуется одним и тем же набором полей. Логическая структура
Односвязные и двусвязные списки
Рекурсивное описание данных
Реку́рсия — определение, описание, изображение какого-либо объекта или процесса внутри самого этого объекта или процесса, то есть ситуация, когда объект является частью самого себя.

Операции над списками
1) Перебор элементов списка.
Эта операция выполняется для линейных списков очень часто и состоит в последовательном доступе к элементам списка – ко всем до конца списка либо до нахождения искомого элемента. Для каждого из перебираемых элементов осуществляется некоторая обработка его информационной части: сравнение с образцом, печать, модификация и прочее.
2) Вставка элемента в список.
Это поиск элемента списка, изменение его адреса на следующиё элемент списка на новый, который имеет адрес на следующий элемент такой же как до операции имел предыдущий.

3) Удаление элемента из списка.
При удалении элемента Эл3 из списка, прежде всего, выполняется поиск этого элемента в списке, а затем его удаление.

4. Стек. Использование стека для вычисления арифметических выражений.
Стек — это упрощенный вариант связанного списка. Новые узлы могут добавляться в стек и удаляться из стека только сверху. По этой причине, стек часто называют структурой вида последним пришел — первым обслужился (LIFO). На стек ссылаются через указатель на верхний элемент стека. Связывающий элемент в последнем узле стека установлен равным NULL,чтобы пометить границу стека.
Возможны три операции со стеком: добавление элемента (иначе проталкивание, push), удаление элемента (pop) и чтение головного элемента (peek)
2 Рисунка

Использование стека для вычисления арифметических выражений
Инфиксная — запись, в которой знак арифметической операции расположен между операндами (А+В).
Префиксная - форма записи, в которой знак операции предшествует операндам (+АВ).
Постфиксная - запись, в которой знак операции располагается следом за операндами (АВ+).
5. Очередь. Операции добавления и удаления элементов. Очередь приоритетов.
Очередь — это такой линейный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение — с другой стороны (называемой началом или головой очереди).
Операции добавления и удаления элементов.
Добавление элемента (принято обозначать словом enqueue — поставить в очередь) возможно лишь в конец очереди, выборка — только из начала очереди (что принято называть словом dequeue — убрать из очереди), при этом выбранный элемент из очереди удаляется.

Очередь с приоритетом — абстрактный тип данных в программировании, поддерживающий две обязательные операции — добавить элемент и извлечь максимум.
ПРИМЕР: очереди с приоритетом можно рассмотреть список задач работника. Когда он заканчивает одну задачу, он переходит к очередной — самой приоритетной (ключ будет величиной, обратной приоритету) — то есть выполняет операцию извлечения максимума. Начальник добавляет задачи в список, указывая их приоритет, то есть выполняет операцию добавления элемента.
6. О-большое нотация определения сложности алгоритма. Временная и емкостная сложность алгоритма. Функция роста.
О-большое нотация определения сложности алгоритма
O – это верхнее ограничение сложности алгоритма.
К примеру есть список чисел: 2 3 8 7 9 1 0
N – это количество элементов в списке, тогда N = 6
Для того что бы найти элемент со значением 3 необходимо потратить к примеру N^2 секунд.
Математически это можно обозначить
О(N^2) = 6^2 = 36
В другом алгоритме время для поиска элемента N log N
Математически
О(N log N) = 6*log 6 = 15
В результате время для поиска элемента в 2 раза меньше чем при первом алгоритме.
О-большое нотация определения сложности алгоритма
O(m) - константная сложность поиск страницы с загнутой страницы в справочнике за 1 сек.(во всех случаях)
O(log n) - логарифмическая сложность, поиск страницы с буквой начиная с середины и каждый раз выбирая сторону второго открытия с середины(в худшем случаи log n в лучшем 1)
O(n) - линейная сложность, поиск номера в несортированном списке.(в лучшем 1, в худшем n)
O(n log n) - квазилогорифмическая сложность, Вначале нужно все страницы просортировать, а потом найти нужную используя поиск с середины, к примеру извлечение страницы из старой книги и добавление в новую
O(n^m) - полимеальная сложность, m циклов по n иттераций. Книг столько сколько и записей, нужно удалить 1 цифру в каждой книге и в каждой записи.
O(m^n) - экспоненциальная сложность
O(n!) - фрактальная сложность
m - константа
n - количество входных данных
Временная и емкостная сложность алгоритма - это сложность для выполнения алгоритма измеряемая во времени или в объеме данных.
Функция роста - это функция согласно, которой будем расти переменная.
7. Простые методы сортировки. Сложность алгоритмов простых алгоритмов сортировки.
Простые методы сортировки.
Под сортировкой обычно понимают процесс перестановки объектов
данного множества в определенном порядке.
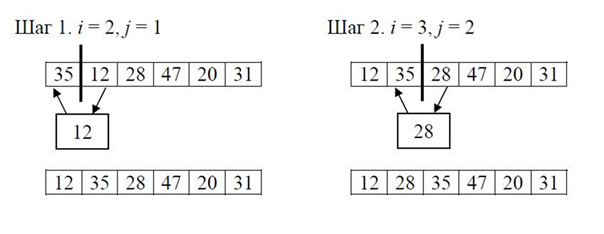
Сортировка с помощью прямого включения.
Сортировка с помощью прямого включения
Делится мысленно на 2 части (отсортированные и неотсортированные)
Каждый следующий элемент вставляется в нужное место пройденных элементов.
Сортировка прямым выбором
При прямом выборе для поиска одного элемента с наименьшим ключом просматриваются все элементы входной последовательности и найденный элемент помещается как очередной элемент в конец готовой последовательности.

Сортировка с помощью прямого обмена
Алгоритм сортировки прямым обменом основан на принципе сравнения и обмена пары соседних элементов до тех пор, пока не будут отсортированы все элементы.

Сложность алгоритмов простых алгоритмов сортировки.
Затрачивается большое количество времени.
8. Метод Шелла. Выбор приращений в методе Шелла.
Метод Шелла
Шаг разбиение из 10 будет 10/2
D=5
Рассматривается 1 элемент и 1+D = 6 элемент
Сравнивается и заменяется если меньше
Также (2,7)(3,8)(4,9)(5,10)
Теперь D2 = Целов(5/2) = 2
Применяем сортировку вставками в каждой группе:
2 группы: (1,3,5,7,9)(2,4,6,8,10)
Теперь D3 = Целов(2/2) = 1
Применяем сортировку вставками в каждой группе:
2 группы: (1,2,3,4,5,6,7,8,9,10)
Выбор приращений в методе Шелла
Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
9. Рекурсия. Быстрая сортировка.
Реку́рсия — определение, описание, изображение какого-либо объекта или процесса внутри самого этого объекта или процесса, то есть ситуация, когда объект является частью самого себя.
Быстрая сортировка, сортировка Хоара (англ. quicksort), часто называемая qsort (по имени в стандартной библиотеке языка Си) — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром во время его работы в МГУ в 1960 году.
Один из самых быстрых известных универсальных алгоритмов сортировки массивов: в среднем O(n*log n) обменов при упорядочении n элементов; из-за наличия ряда недостатков на практике обычно используется с некоторыми доработками.
j - двигаем в -1 пока не встретим элем <-15
1 шаг - i остановился(17), j - переместился
3 шаг j - остановился(-21)
Следовательно i and j меняются местами значениями эл мас
3 этап
После замены
i +1
j -1
И все повторяется со 2 этапов
Меняем местами
4 Этап
После замены
i +1
j -1
Если i>j - первый этап закончин
В результате все элементы справа больше -15
все элементы слевы меньше -15
2
Рассмотрим массив вправа от опорного
i = индекс опорного j последний справо
Повторяется 2 этап
И продолжаем
Если получаем ситуацию i=j по индексу
Если j уходит за конец массива а i дошел до конца, то произошло разбиение до 1го элема
выписываем оставшиеся справа элементы до j
И возвращяемся на шаг назад
сортируем левую часть
После проведение тех же действий
Опять возвращаемся на 2 шага назад, и проводим те же действия
10. Поиск в упорядоченных и неупорядоченных таблицах. Временная сложность поиска. Бинарный поиск.
Двоичный поиск:
Применяется для упорядоченных массивов. При двоичном поиске используется метод деления пополам.
11. Двоичные деревья. Сбалансированные деревья. Построение сбалансированного двоичного дерева.
Двоичное дерево – это дерево, у которого не более 2х потомков
Сбалансированное дерево — разница в высоте между правым и левым поддеревом не превышает константу, обычно это 1.
Самый важный параметр высота дерева, и чем больше высота тем больше искать.
В памяти хранить в списке с двумя левым и правым адресом на элемент.
Для построения каждый элемент сравниваем поочередно с текущем, если больше то с право если меньше то с лево.
Операции добавление, поиска и удаления занимает O(log n)
Для построения сбалансированного дерева, нужно поддерживать баланс.
Построение самобалансирующееся двоичное дерево поиска.
Nil – черные
Если не получается баланс то передвигается один узел выше в том месте где нет перевешивает.
Правила:
Один бит для указания цвета
Корень должен быть черным
У красного узла только черные
любой путь от корня до конца должен содержать одинаковое число черных узлов.
12. Двоичные деревья поиска. Способы обхода дерева. Операции добавления, удаления, поиска элементов.
Двоичные деревья поиска
Бинарное дерево поиска
Условия
1 Для каждой вершины с лево расположены все элементы меньше значения вершины, а с права - больше
Из этого свойства понятно как искать элементы, сравнивать где искать с лево или с права
2 Высота дерева ровна логарифму N
Если мы хотим добавить элемент к примеру 11. Мы его ищем, если его нет, туда мы его и добавляем.
Удаление за log n
Добавление
Можно сбалансировать дерево
После каждого добавления можно делать балансировку дерева методоб красно черное дерево
N log N - время создания дерева поиска
Прямой порядок прохождения бинарного дерева («сверху-вниз», «в глубину»):
1. попасть в корень,
2. пройти в прямом порядке левое поддерево,
3. пройти в прямом порядке правое поддерево.
Прохождение бинарного дерева в обратном порядке («снизу-вверх»):
1. пройти в обратном порядке левое поддерево
2. пройти в обратном порядке правое поддерево
3. попасть в корень.
Симметричный обход («слева-направо»):
1. пройти в симметричном порядке левое поддерево,
2. попасть в корень,
3. пройти в симметричном порядке правое поддерево.
13. Б-деревья. Представление Б-деревьев. Область применения.
B-дерево — структура данных, дерево поиска. С точки зрения внешнего логического представления, сбалансированное, сильно ветвистое дерево во внешней памяти.
Сбалансированность означает, что длина любых двух путей от корня до листьев различается не более, чем на единицу.
Ветвистость дерева — это свойство каждого узла дерева ссылаться на большое число узлов-потомков.
B-деревом называется дерево, удовлетворяющее следующим свойствам:
1) Каждый узел содержит хотя бы один ключ. Ключи в каждом узле упорядочены. Корень содержит от 1 до 2t-1 ключей. Любой другой узел содержит от t-1 до 2t-1 ключей. Листья не являются исключением из этого правила. Здесь t — параметр дерева, не меньший 2 (и обычно принимающий значения от 50 до 2000).
2) Каждый узел B-дерева, кроме листьев, можно рассматривать как упорядоченный список, в котором чередуются ключи и указатели на потомков.
3) Глубина всех листьев одинакова.
Свойство 2 можно сформулировать иначе: каждый узел B-дерева, кроме листьев, можно рассматривать как упорядоченный список, в котором чередуются ключи и указатели на потомков.
Применение:
Структура B-дерева применяется для организации индексов во многих современных СУБД.
B-дерево может применяться для структурирования (индексирования) информации на жёстком диске (как правило, метаданных)
Время доступа к произвольному блоку на жёстком диске очень велико (порядка миллисекунд), поскольку оно определяется скоростью вращения диска и перемещения головок. Поэтому важно уменьшить количество узлов, просматриваемых при каждой операции.
14. Пирамидальная сортировка. Временная сложность пирамидальной сортировки. Способы реализации.
Пирамидальная сортировка — алгоритм сортировки, работающий в худшем, в среднем и в лучшем случае (то есть гарантированно) за Θ(n log n) операций при сортировке n элементов. Количество применяемой служебной памяти не зависит от размера массива (то есть, O(1)).
Для начала вносим все элементы в дерево заполняя с лево на право.
Далее начинаем искать снизу самый меньший элемент сравнивая по уровням.
И передвигаем его на верх меняя местами.
После нахождение данного элемента записываем его с конца и меняем местами с последним элементом. И так повторяем пока не отсортируем.
Затем записывать с лево на право все элементы начиная с верхнего уровня в строку. Это и будет пирамидальная сортировка.
Для программной сортировки используется только одномерный массив

15. Принципы объектно-ориентированного программирования
Объектно-ориентированное программирование (ООП) — методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
Необходимо обратить внимание на следующие важные части этого определения: 1)объектно-ориентированное программирование использует в качестве основных логических конструктивных элементов объекты, а не алгоритмы; 2) каждый объект является экземпляром определенного класса; 3) классы образуют иерархии. Программа считается объектно-ориентированной, только если выполнены все три указанных требования. В частности, программирование, не использующее наследование, называется не объектно-ориентированным, а программированием с помощью абстрактных типов данных.
Принцыпы
Все объекты в программе могут взаимодействовать между собой по средствам публичного интерфейса, а вся его внутренняя механизация скрыта - это называется инкапсуляцией.
Если хорошо построить программу можно работать с каждой ее частью отдельно не обхватывая всю программу отдельно.
Позволяет упростить большие объекты составляя ее из более маленьких, за счет этого над программой могут работать бесчисленное количество разработчиков и не знать весь процесс целиком.
Возможность создавать объекты на основе уже существующих классов и добавлять к ним дополнительные элементы. - Это наследование.
Все языки строятся на основе ООП.
16. Классы. Объекты. Форматы описания классов
Класс — это элемент ПО, описывающий абстрактный тип данных и его частичную или полную реализацию.
Суть отличия классов от других абстрактных типов данных состоит в том, что при задании типа данных класс определяет одновременно как интерфейс, так и реализацию для всех своих экземпляров, а вызов метода-конструктора обязателен.
Класс - универсальный, комплексный тип данных, состоящий из тематически единого набора «полей» (переменных более элементарных типов) и «методов» (функций для работы с этими полями), то есть он является моделью информационной сущности с внутренним и внешним интерфейсами для оперирования своим содержимым (значениями полей).
Объект
Сущность в адресном пространстве вычислительной системы, появляющаяся при создании экземпляра класса
Объект в ООП — это сущность, способная сохранять свое состояние (информацию) и обеспечивающая набор операций (поведение) для проверки и изменения этого состояния.
Формат описания класса.
Type
<Имя класса>=Class
// члены класса
Поля
Свойства
Методы
End;
17. Типы отношений между классами
Как правило, любая программа, написанная на объектно-ориентированном языке, представляет собой некоторый набор связанных между собой классов.
Возможны следующие связи между классами:
агрегация ( Aggregation );
ассоциация ( Association );
наследование ( Inheritance );
метаклассы ( Metaclass ).
Агрегация
Отношение между классами типа "содержит" (contain) или "состоит из" называется агрегацией, или включением. Например, если аквариум наполнен водой и в нем плавают рыбки, то можно сказать, что аквариум агрегирует в себе воду и рыбок.
Ассоциация
Если объекты одного класса ссылаются на один или более объектов другого класса, но ни в ту, ни в другую сторону отношение между объектами не носит характера "владения", или контейнеризации, такое отношение называют ассоциацией (association).
В качестве примера можно рассмотреть программиста и его компьютер. Между этими двумя объектами нет агрегации, но существует четкая взаимосвязь. Так, всегда можно установить, за какими компьютерами работает какой-либо программист, а также какие люди пользуются отдельно взятым компьютером.
Наследование
Из общих объектов создаются другие, более специализированные. Механизм создания таких подобъектов называется наследованием.
Метакласс
Для любого объекта существует шаблон, описывающий свойства и поведение этого объекта, значит, его можно определить и для класса. Такой шаблон, задающий различные классы, называется метаклассом.