Первый шаг
Vitriol&Ludicio
Поехали, теперь начнем писать наш первый парсер.В этой статье я постараюсь как можно больше уменьшить объем теории и заострится на практике.
Как работает браузер, интернет, протоколы, сейчас я не буду рассказывать...
для этого есть, собственно, сам интернет можете погуглить, а эту статью я планировал сделать больше практической.
Писать будем на python, поэтому, я надеюсь, вы позаботитесь сами о среде программирования...
Нам понадобится установить BeautifulSoup т.к. данная библиотека не является библиотекой python по умолчанию.
И да...писать будем на 3 питоне, а не на 2.
BeautifulSoup я устанавливал через pip.Кстати мы будем использовать 4 версию .
Установка происходит следующим образом :
Лично я буду писать в windows поэтому...Я просто прописываю в командной строке "plp install beautifulsoup4" без кавычек.
Будем считать, что подготовку к кодингу сделали.
Начнем с малого:
from urllib.request import urlopen
html = urlopen("http://pythonscraping.com/pages/page1.html")
print(html.read())
Должно получится как-то так:

Вы можете писать скрипт в отдельном файле, а можете сразу писать в шеле как я.
Что мы написали и что мы получили:
from urllib.request import urlopen #Делает то, что написано, -импортирует функцию urlopen из модуля request библиотеки urllib
urllib - стандартная библиотека python и содержит функции для запроса данных в сети, всяких cookies и доже изменения метаданных(заголовков и пользовательского агента).
Советую разобраться с библиотекой urllib и прочитать ее документацию т.к. мы ей будем пользоваться довольно часто.
Функция urlopen необходима для того, чтобы открыть удаленный объект в сети и прочитать его.
html = urlopen("http://pythonscraping.com/pages/page1.html")# Здесь мы создаем переменную и присваиваем ей значение которое возвращает нам функция urlopen, открывая файл ссылки(page1.html).
Начнем разбираться с этой библиотекой:
Наиболее часто используемым объектом в библиотеке BeautifulSoup является, собственно, сам BeautifulSoup. Поэтому глянем как он работает...
Вот что я написал:
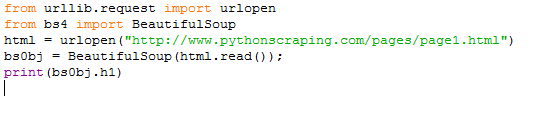
Вот что я получил:

Собственно вы также должны получить такой же результат.
Может вывести предупреждение, но не волнуйтесь, следующих статьях я вам объясню как от него избавится, наверно, если не забуду(^-^).
Объясняю что мы написали:
Как и в примере выше, мы импортируем библиотеку urlopen и вызываем функцию html. read(), чтобы получить HTML-контент страницы. Затем этот HTML-контент мы преобразуем в объект BeautifulSoup со следующей структурой: • html —» <html><head>...</head><body>...</body></html>
- head —> <head><title>A Useful Page<title></head>
- title -> <title>A Useful Page</title>
- body —> <body><hl>An Int...</hl><div>Lorem ip...</div> </body>
- hi —> <hl>An Interesting Title</hl>
- div —> <div>Lorem Ipsum dolor...</div>
Обратите внимание, что тег <hl>, который мы извлекли из страни цы, был вложен в два слоя внутри объекта BeautifulSoup (html -> body -» hi). Однако после излечения тега Н из объекта мы обращаемся к нему напрямую:

Фактически любой вызов функции из нижеприведенного списка сгенерирует один и тот же вывод:

Скажу одно, с помощью BeautifulSoup можно достать любую информацию из любого HTML(или XML) файла, при условии, что она заключена в определенный идентифицирующий тег или расположена рядом с ним.
Нууу, что я думаю на этом можно заканчивать статью, собственно мы достаточно сделали. Подводим итоги...
Во-первых мы определились с тем, на чем будем писать.
Во-вторых я вам показал как можно получить исходный код страницы.
В-третьих установили и посмотрели как работает BeautifulSoup.