Все что надо знать о нейронных сетях
The Geek Log
Если вы читали любую из статей по ИИ (искусственный интеллект), вы наверняка сталкивались с термином «нейронная сеть». Она вполне может быть одной из наиболее фундаментально подрывных технологий, существующих на сегодняшний день. Если не углубляться в математику, а вместо этого искать аналогии и анимации, то можно понять что как работает.
Мысли как подбор
Одна из ранних вариаций ИИ учила, что если вы загружаете как можно больше информации в мощный компьютер и даете ему как можно больше направлений для понимания этих данных, он должен уметь «думать». Эта идея лежала в основе Шахматных компьютеров, таких как IBM Deep Blue: путем исчерпывающего программирования всех возможных шахматных движений в компьютер, а также известных стратегий, а затем придав ему достаточную мощность, программисты IBM создали машину, которая теоретически могла бы рассчитывать все возможные движения и результаты последующих ходов, чтобы переиграть своего противника. Это действительно работает, так учились шахматисты ещё в 1997 году.
(Этот метод отличается от AlphaGo Google, что использует самообучающуюся нейросеть чтоб в конечном счете победить человека в Go, по сравнению с Deep Blue, использовавший жестко закодированную функцию, написанную человеком).
При таком типе вычислений машина полагается на фиксированные правила, которые были жестко запрограммированы инженерами по принципу if-else (если-то); Это, безусловно, мощная суперкомпьютерная технология, но не «мышление».
Обучающие машины для обучения
За прошедшее десятилетие ученые возродили старую концепцию, которая основана не на массиве энциклопедической памяти, а на простом и систематическом способе анализа входных данных, и свободно моделируются после человеческого мышления. Известная как глубокое обучение или нейронные сети, эта технология существует с 1940-х годов, но из-за сегодняшнего экспоненциального распространения данных - изображений, видео, голосового поиска, привычек просмотра и более - наряду с наддувом и доступными процессорами, Способного приступить к реализации своего истинного потенциала.
Машины - они такие же, как мы!
Искусственная (в отличие от нейронной) нейронная сеть (ANN) - это алгоритмическая конструкция, которая позволяет машинам учиться всему от голосовых команд и кубирования плейлиста до композиции музыки и распознавания изображений. Типичный ANN состоит из тысяч взаимосвязанных искусственных нейронов, Последовательно сложенные в строках, известные как слои, образуя миллионы соединений. Во многих случаях слои связаны только со слоем нейронов до и после них через входы и выходы. (Это сильно отличается от нейронов в человеческом мозге, которые взаимосвязаны во всех отношениях)
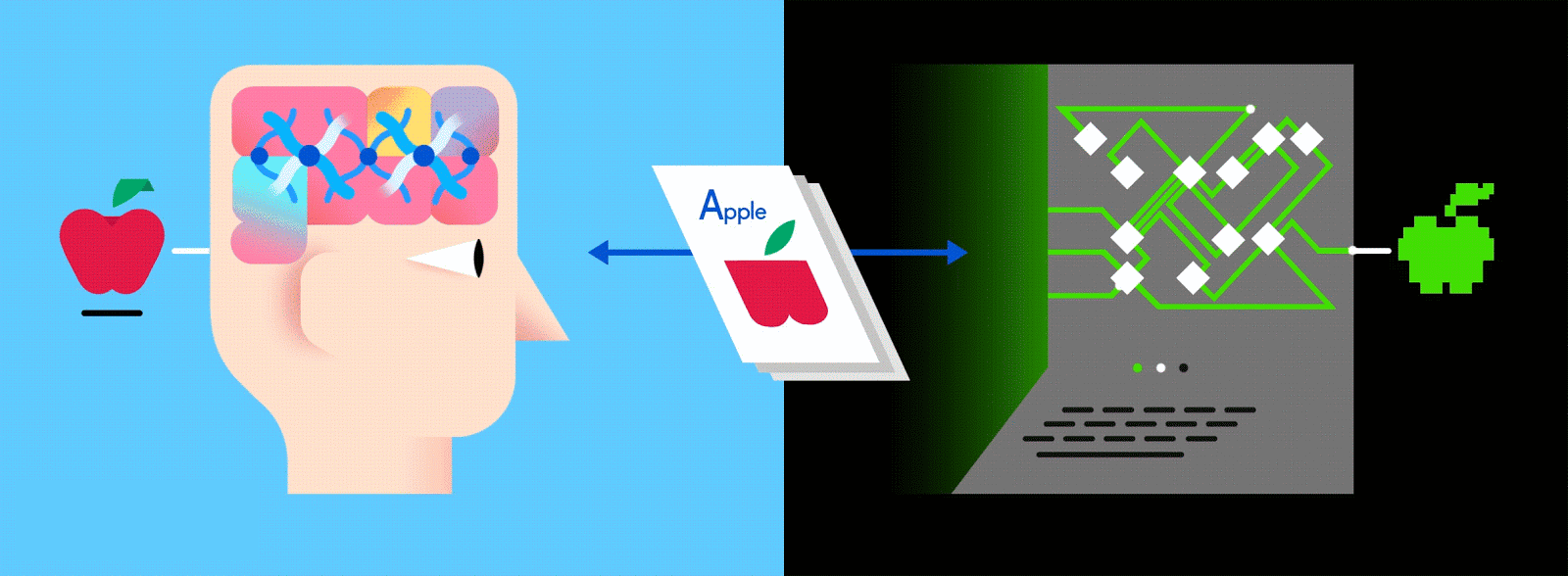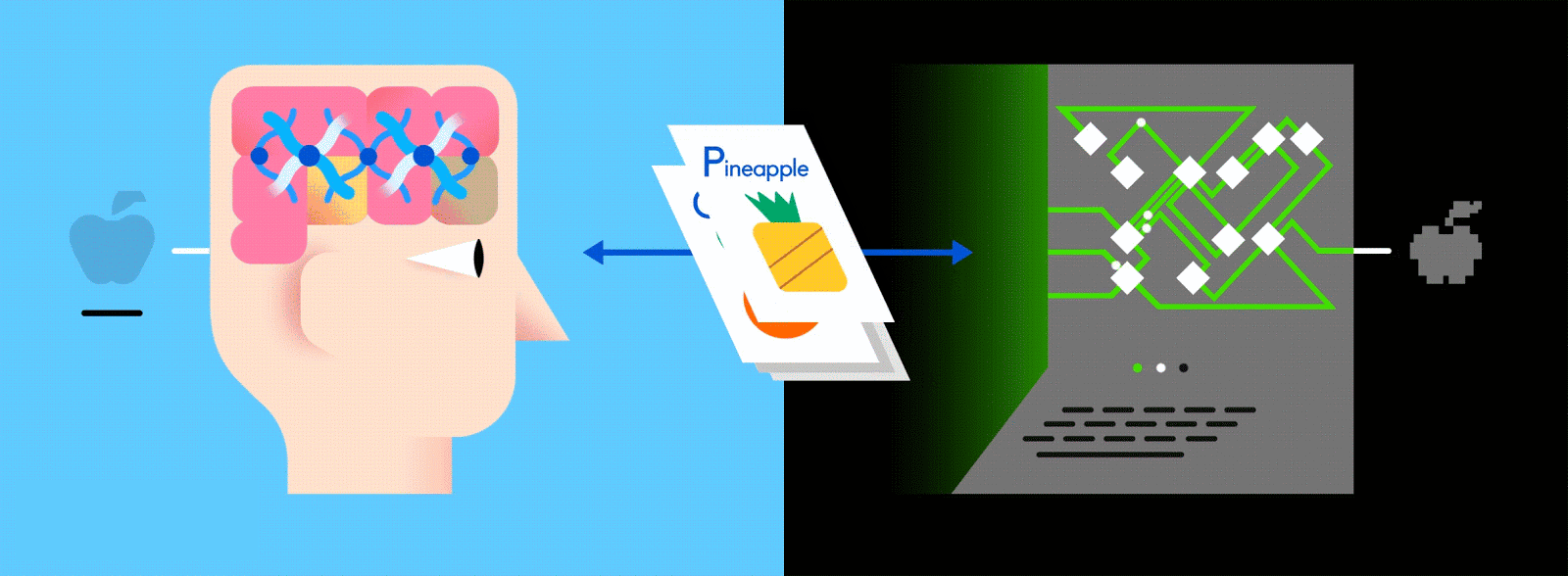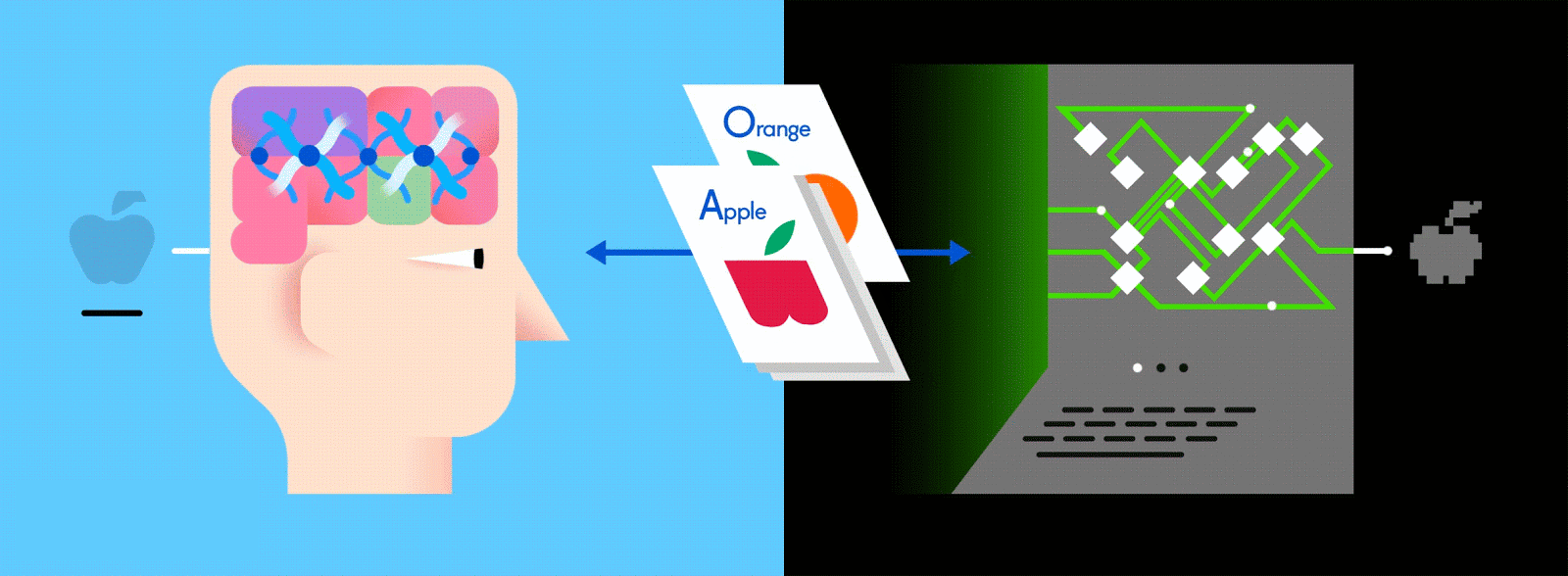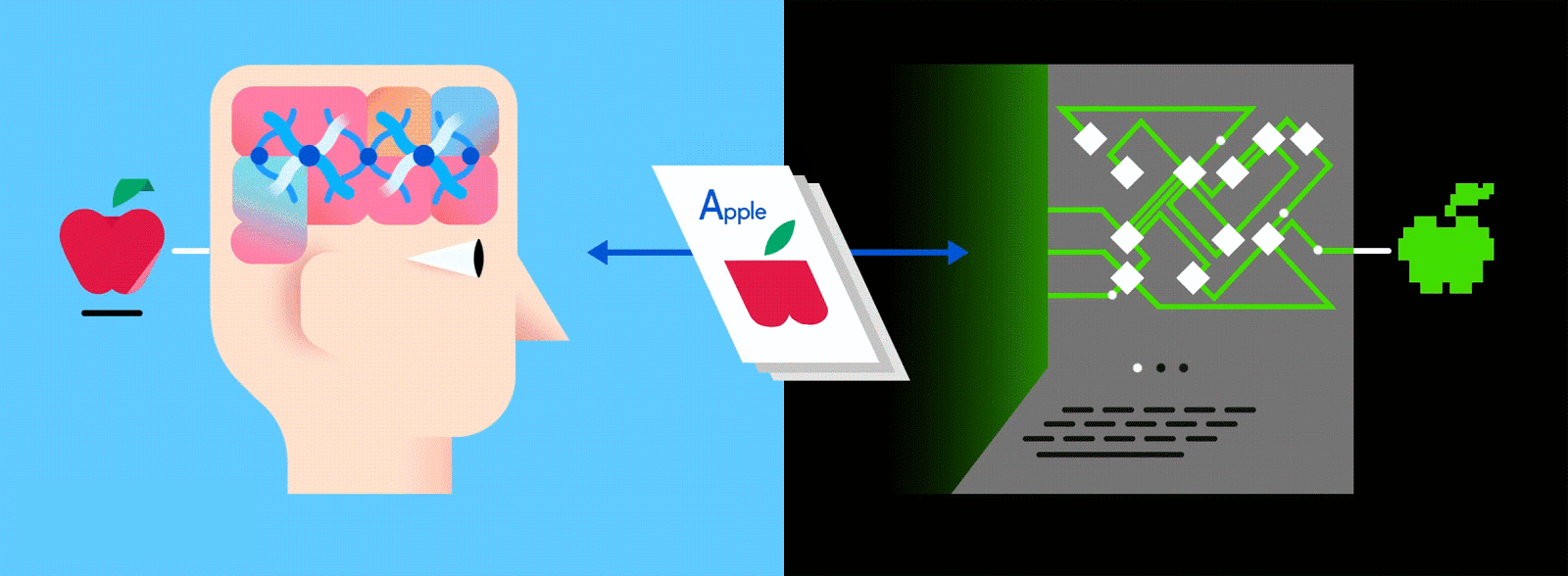
Многоуровневый ANN считается одним из основных способов получения современного машинного обучения, и его подача огромным количеством помеченных данных позволяет ему научиться интерпретировать эти данные как (а иногда и лучше) человека.
Возьмем, к примеру, распознавание изображений, опирается на определенный тип нейронной сети, называемой сверточной нейронной сетью (CNN), называемый так потому, что использует математический процесс, известный как свертка, чтобы иметь возможность анализировать изображения нелитературными способами, Например, идентифицировать частично скрытый объект или объект, который можно просматривать только с определенных углов. (Существуют и другие типы нейронных сетей, в том числе рекуррентные нейронные сети и нейронные сети с обратной связью, но они менее полезны для идентификации таких вещей, как изображения, что является примером, который мы собираемся использовать ниже).
Все на сетевом обучении
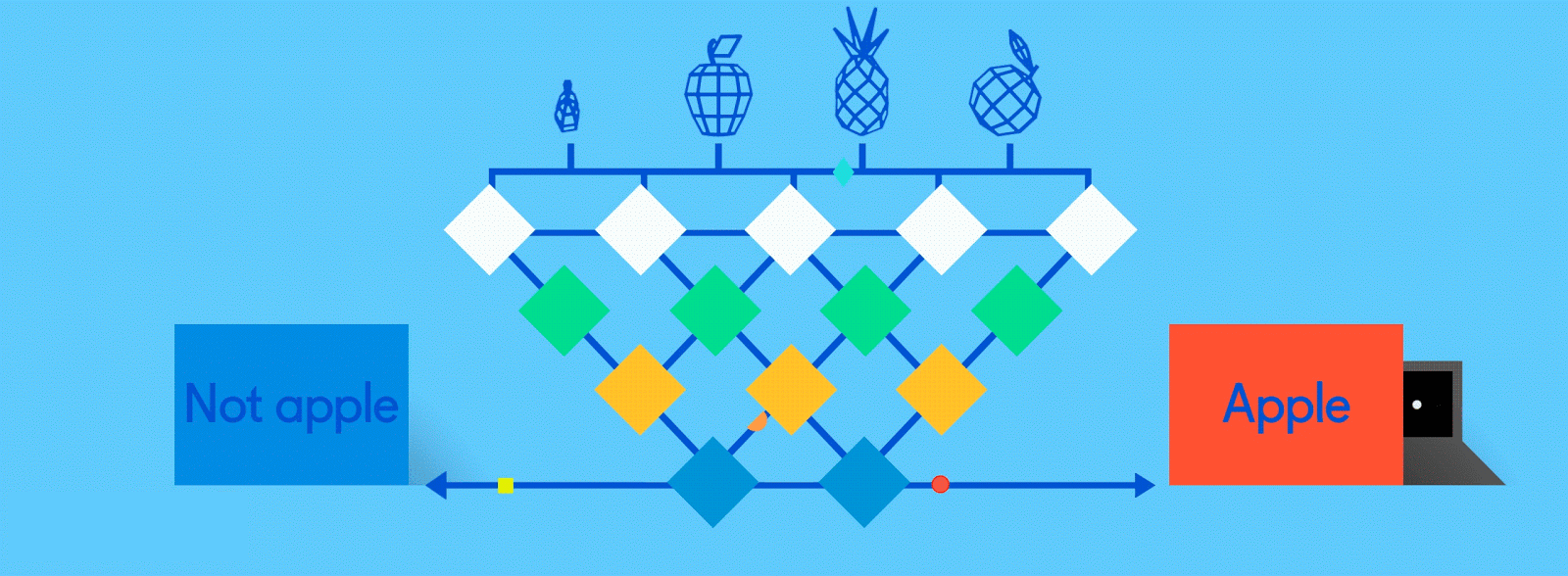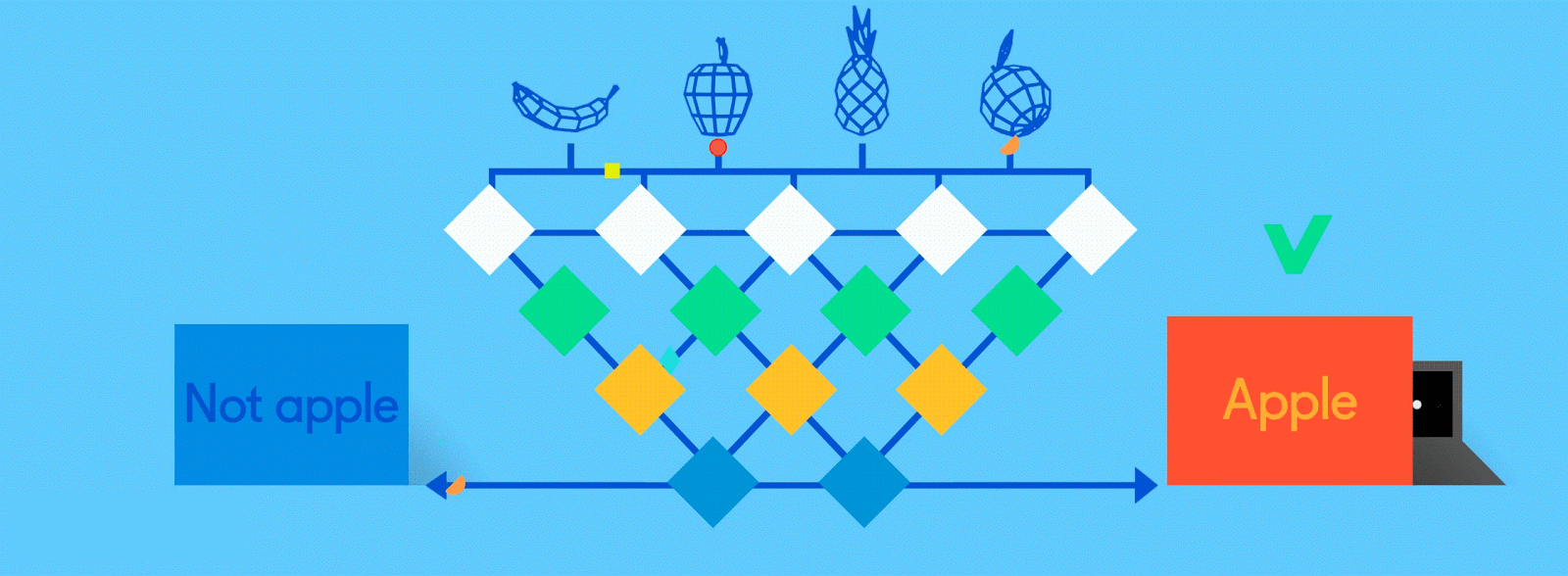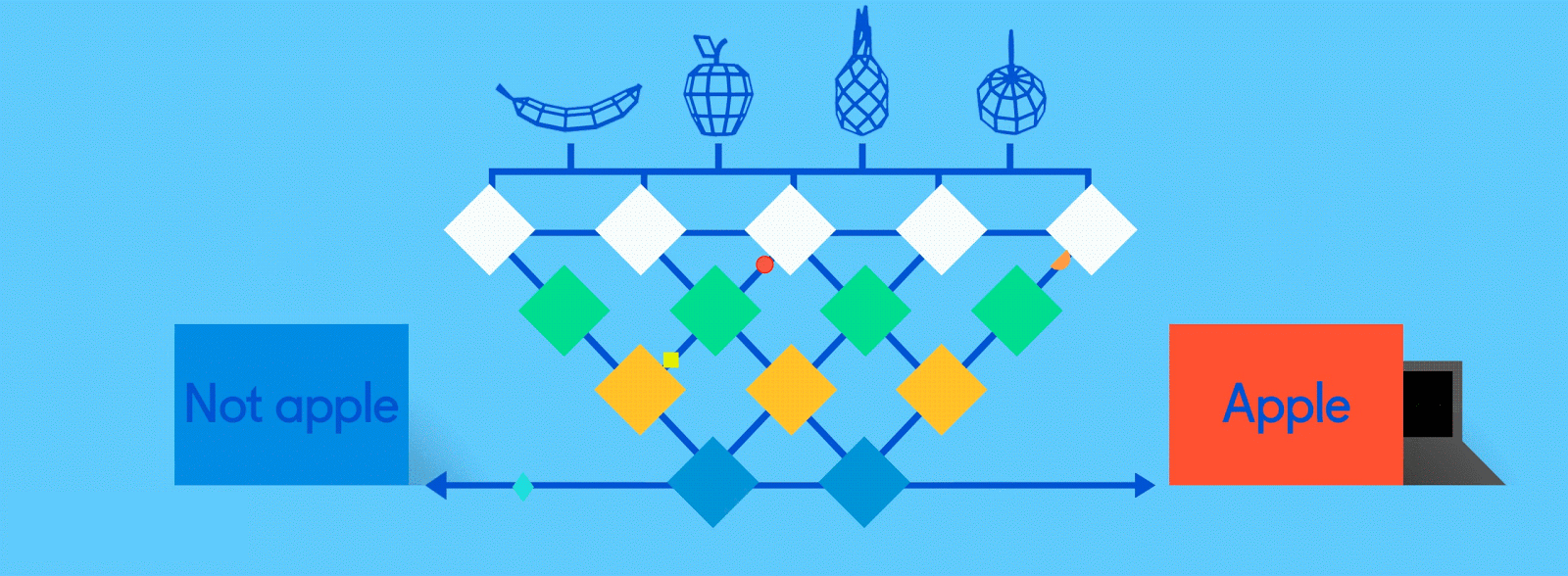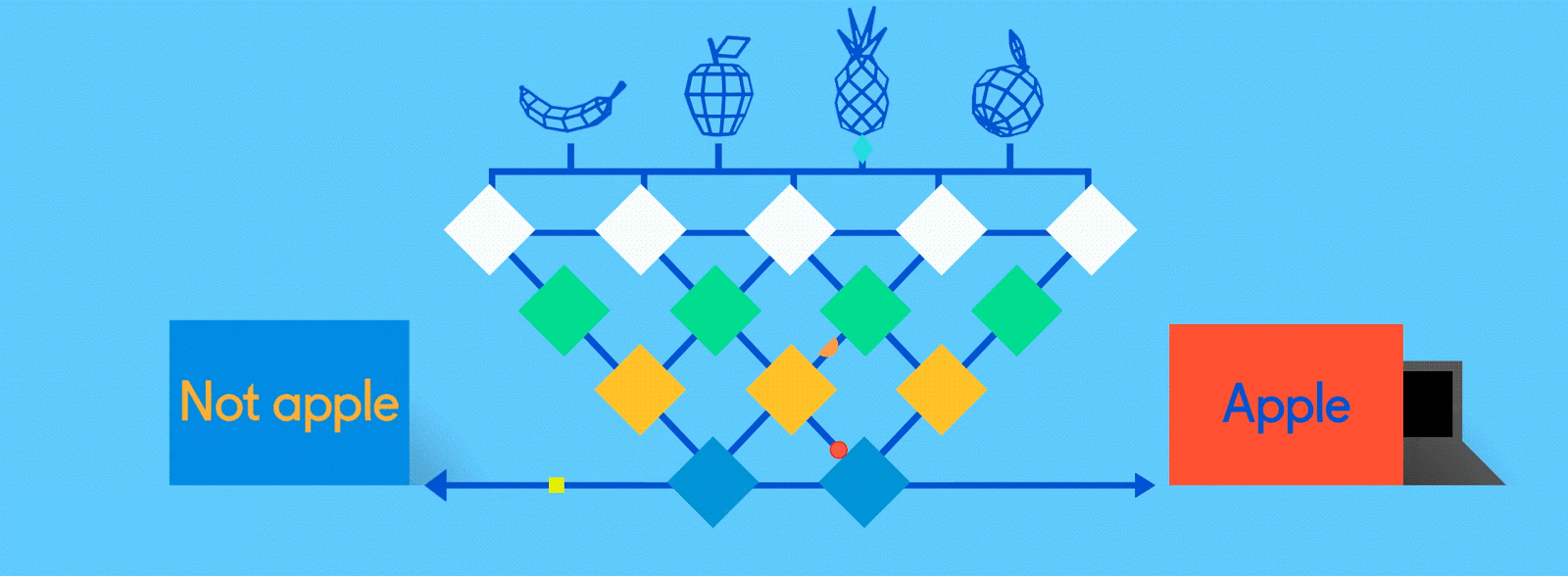
Итак, как же обучаются нейронные сети? Давайте посмотрим на очень простую, но эффективную процедуру, называемую контролируемым обучением. Здесь мы подаем нейронной сети огромное количество обучающих данных, помеченных людьми, чтобы нейронная сеть могла по сути проверять себя, когда она учится.
Предположим, что эти помеченные данные состоят из изображений яблок и апельсинов, соответственно. Изображения являются данными; «Яблоко» и «Оранжевый» являются ярлыками, в зависимости от изображения. При подаче изображений сеть разбивает их на самые основные компоненты, то есть ребра, текстуры и фигуры. Когда картина распространяется по сети, эти основные компоненты объединяются, чтобы сформировать более абстрактные концепции, то есть кривые и различные цвета, которые в сочетании друг с другом начинают выглядеть как стебель, целый апельсин или как зеленые, так и красные яблоки.
По завершении этого процесса сеть пытается сделать прогноз о том, что на картинке. Во-первых, эти предсказания будут казаться случайными догадками, поскольку реального обучения еще не было. Если входное изображение - яблоко, но предсказано «оранжевое», внутренние уровни сети необходимо будет отрегулировать.
Корректировки осуществляются посредством процесса, называемого обратным продвижением, чтобы увеличить вероятность предсказания «яблока» для того же изображения в следующий раз. Это повторяется снова и снова, пока прогнозы не станут более или менее точными. Так же, как, когда родители учат своих детей распознавать яблоки и апельсины в реальной жизни, для компьютеров тоже, практика усовершенствует результаты.
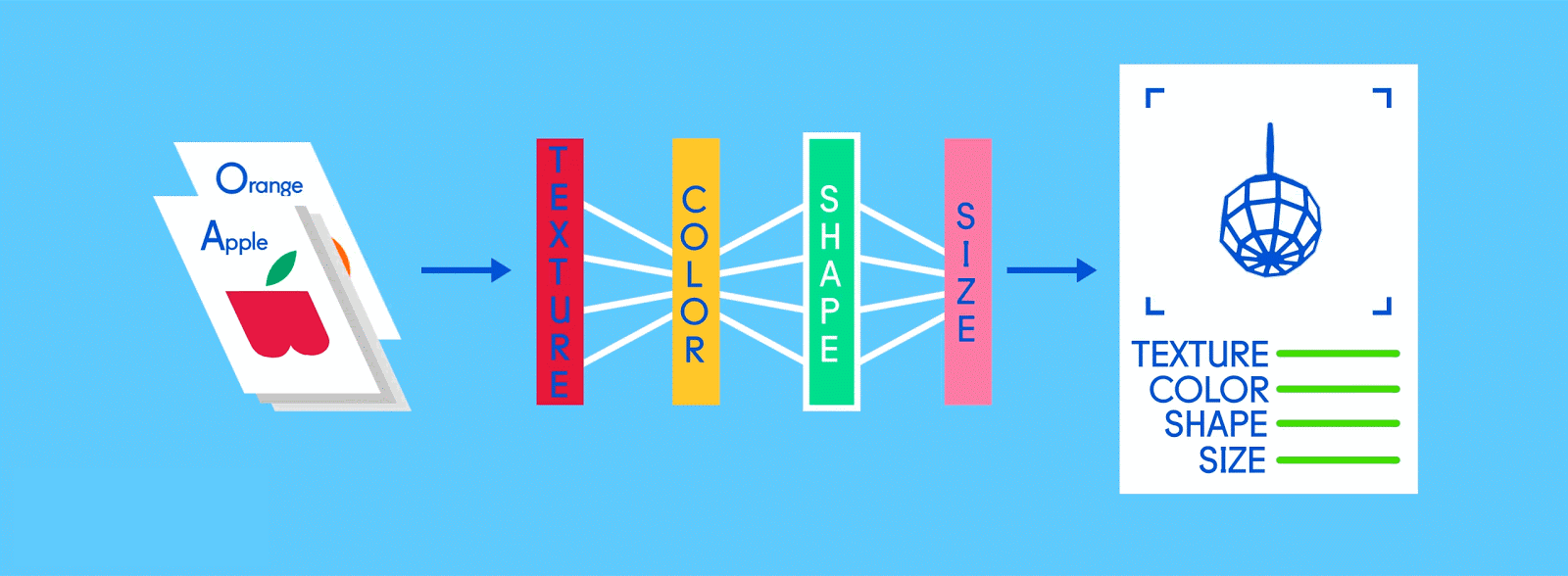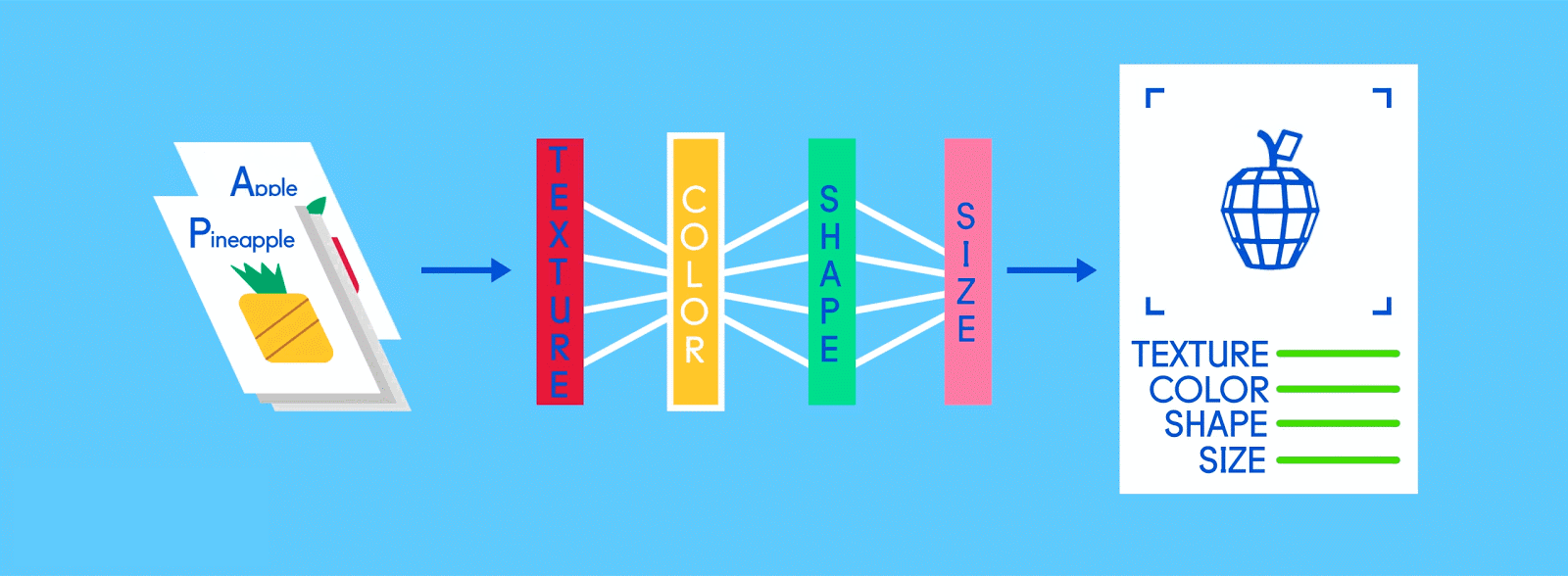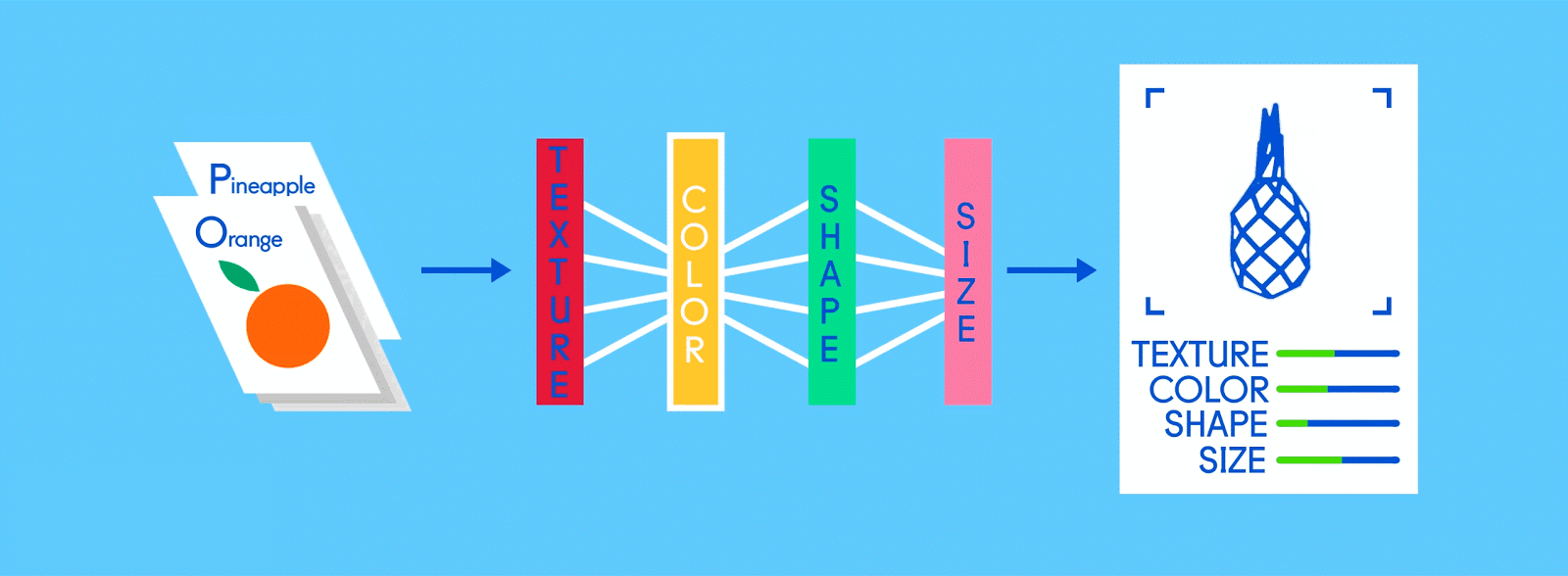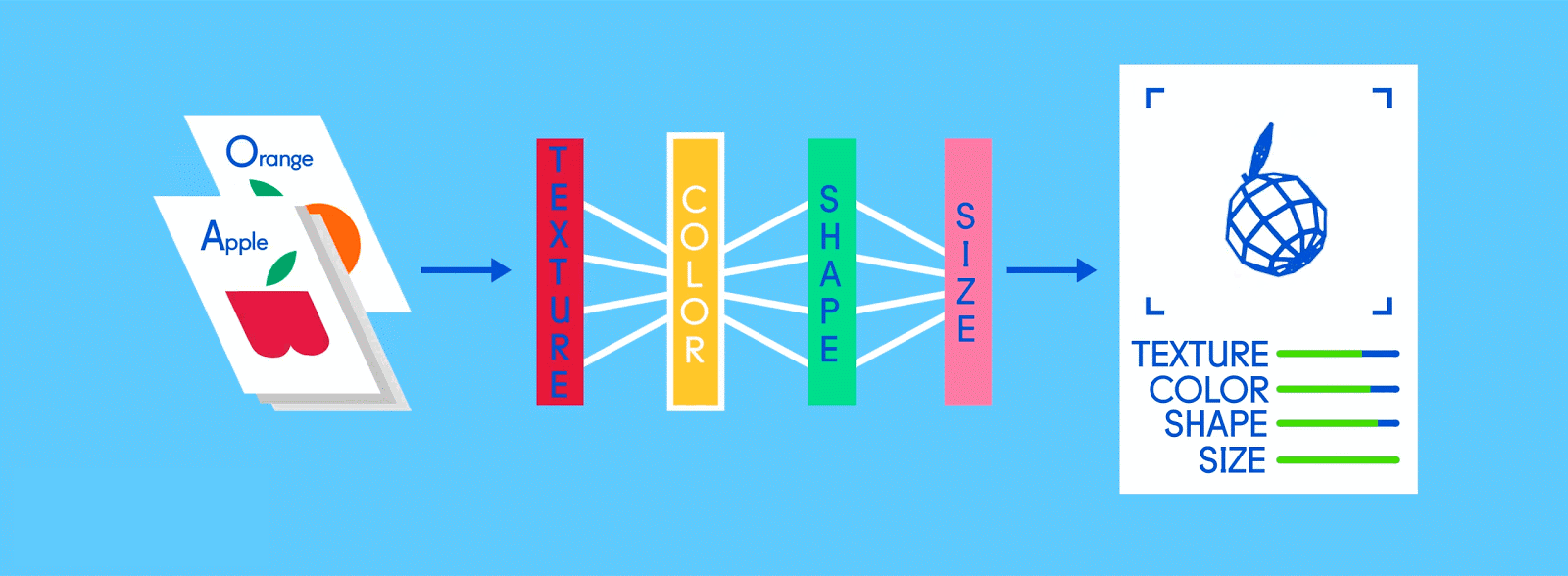
Поскольку одна и та же сеть ищет две разные вещи - яблоки и апельсины - конечный результат сети выражается в процентах. В этом случае мы предполагаем, что сеть уже немного отстает в своем обучении, поэтому прогнозы здесь могут быть, скажем, 75 процентов «яблоко» и 25 процентов «оранжевого». Или, если это раньше в Обучение может быть более неточным и определить, что это 20 процентов «яблоко» и 80 процентов «оранжевый».