MongoDb
SanSYS
Скачать сервер можно отюда
https://www.mongodb.com/download-center/community
Установка не требуется, достаточно запустить
mongod -port 27011
Или указав точные директорию/порт
mongod --dbpath ./mongo11 --port 27022
Консоль для подключения - файл mongo[.exe]
Язык запросов в нуль != SQL, рекомендую лайтово глянуть https://docs.mongodb.com/manual/tutorial/query-documents/


Если не нравится пользоваться терминалом, то есть хороший GUI
https://studio3t.com/download-thank-you/?OS=win64
Что-то похожее на SQL таки есть, но его следует избегать

Книжечка сильно устаревшая))
Следующий код ничего не возвращает

Лучше искать индексы в конкретной коллекции, обычно это и нужно
https://docs.mongodb.com/manual/reference/method/db.collection.getIndexes/


План запроса
Конечно, как и в PG, если есть большая коллекция, то сканить её всю это плохо. А происходит ли это - можно узнать через план запроса. Если в explain ничего не передавать, то план запроса будет только от планнера, см. https://docs.mongodb.com/manual/reference/method/cursor.explain/

Индексирование
db.phones.ensureIndex(
{display: 1},
{unique: true, dropDups: true}
)
Метод уже устаревший и является алиасом для https://docs.mongodb.com/manual/reference/method/db.collection.createIndex/#db.collection.createIndex

Теперь индекс есть и план выглядит отлично


Значение executionTimeMillis существенно уменьшилось )
Построение индекса по вложенным полям


Встроенный профилировщик
Не все пользуются explain, потому на тестовых средах можно насильно включать профайлер https://docs.mongodb.com/manual/reference/method/db.setProfilingLevel/index.html
db.setProfilingLevel(2);
После планы запросов будут складироваться в db.system.profile

Агрегированные запросы
Пока всё было замечательно, но group by это полный атас (

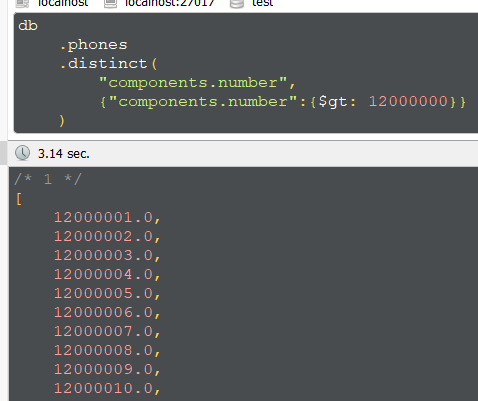
Но если будет много значений, то словишь ошибку
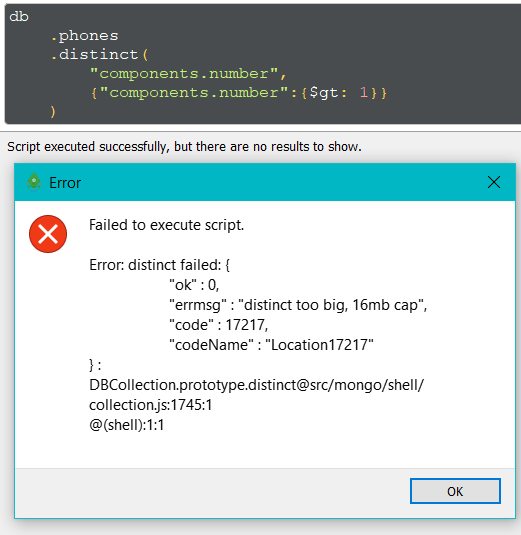



Рекомендую сходить в доку и посмотреть иные примеры метода aggregate
https://docs.mongodb.com/manual/reference/operator/aggregation/group/index.html

Хранимки



Кластер
Для начала нужно запустить три сервера, с разными портами и директориями (три, пять, семь, классика):
mongod --replSet book --dbpath ./mongo1 --port 27011 mongod --replSet book --dbpath ./mongo2 --port 27012 mongod --replSet book --dbpath ./mongo3 --port 27013
После подключиться к любому:
mongo --port 27011
И выполнить инициалиацию:
rs.initiate({
_id: 'book',
members: [
{_id: 1, host: 'localhost:27011'},
{_id: 2, host: 'localhost:27012'},
{_id: 3, host: 'localhost:27013'}
]
})
Через команду rs.status() дождаться появления первичной ноды
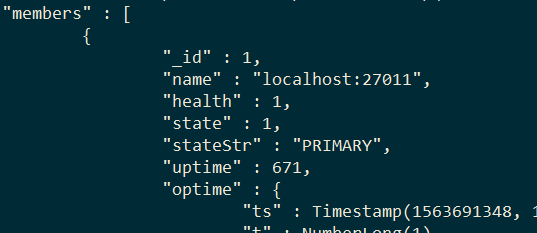
Для проверки - в первичную ноду вставляю новое значение:
book:PRIMARY> db.echo.insert({say: 'Hi there!'})
WriteResult({ "nInserted" : 1 })
И стопаю её )
В логах оставшихся нод наблюдается паника

Но если подключиться ко второй ноде - видно, что она стала первичной и вставленное значение присутсвует
$ mongo --port 27012
book:PRIMARY> db.echo.find()
{ "_id" : ObjectId("5d340ad9cfb70cde3e8b8ab8"), "say" : "Hi there!" }

Если неудобно смотреть JSON через консоль, то можно юзать Robo

Казалось бы - есть рабочие реплики и отлаженный фейловер, но любая работа с не мастер нодами - фейл (и запись, и чтение). Они только для репликации и фейловера







Шардинг

Именно так можно размазать чтение, но клиенту нежелательно иметь знания обо всех шардах.
Кратко, как настраивается:
- запускается несколько узлов в режиме поддержки шардинга (shards)
- запускается отдельный узел-конфигурации (config servers)
- Запускается отдельный роутер - точка входа для клиентов (Routers)

https://docs.mongodb.com/manual/sharding/



Про опечатки - речь идёт про операцию обновления, т.е. нельзя писать вот так:
db.inventory.updateMany(
{ "qty": { $lt: 50 } },
{ "size.uom": "in", status: "P" }
)
Нужно явно указывать обновляемое подмножество:
db.inventory.updateMany(
{ "qty": { $lt: 50 } },
{
$set: { "size.uom": "in", status: "P" }
}
)
Иначе сервер затрёт весь документ вашим маленьким доком
P.S.: Консолек будет много ;)
