machine learning
@trifonovС текстами о машинном обучении и нейросетях двойственная ситуация. С одной стороны, их написано уже стопицот, вроде бы тема избитая, и все давно всё понимают. А с другой, когда поднимается паническая волна вроде «фейсбуку пришлось срочно отключить чат-ботов, создавших непонятный людям язык», видно, что никто по-прежнему ничего не понимает.
Мне кажется, проблема в том, что большинство таких текстов не даёт людям быстро ухватить суть. Из их красивых слов про «обучение на опыте» и «движение к искусственному интеллекту» становится ясно «машины умнеют, а ты нет», но неясны две главные вещи: в чём принципиальное новшество, и пора ли запасаться консервами к войне со Скайнетом.
Поэтому я написал стопицот первый текст (дисклеймер: я сам ничего не понимаю).
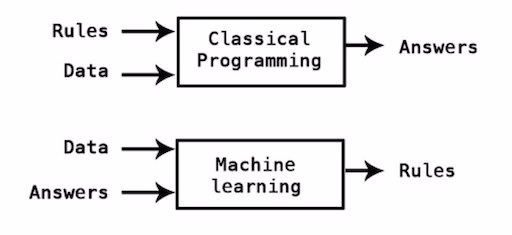
На вопрос «в чём новшество» ёмко отвечает эта схема (взял отсюда), изложу примерно то же более развёрнуто.
Как традиционно работали программы? Представим приложение-калькулятор. Сначала разработчик прописывает чёткие правила. Потом пользователь тыкает в приложение. Оно применяет правила к тому, как тыкнули, и выводит ответы. Все счастливы.
Но прописать компьютеру строгие формализованные правила для калькулятора несложно, а что делать с задачей вроде «найти на фотографии кота»? Каким должен быть алгоритм, который узнает даже кота, наполовину спрятавшегося за занавеской? А ведь с этой задачей легко справляется ребёнок. Ребёнок не пытается формализовать её, у него нет строгого определения кота, ему не требуется присутствие на снимке конкретно усов или хвоста. Он просто видел достаточно котов, чтобы уловить общую закономерность.
И машинное обучение помогает решить эту задачу аналогичным способом: скормить компьютеру достаточно много фотографий с котами, чтобы он, сопоставив их все, вывел закономерность и дальше ориентировался на неё при виде новых фотографий.
В результате, как изображено на схеме, к подходу «задать строгие правила и по ним получать ответы» добавился подход «сначала дать много ответов, а дальше вывести из них правила».
Новый подход не гарантирует абсолютной точности. Привычный калькулятор будет всегда складывать два числа правильно, а распознавание может и упустить кота, и найти лишнего (приняв за него собаку). Но оно может работать достаточно хорошо, чтобы от его использования была явная польза.
В случае, когда требуется написать калькулятор или что-то ещё с очень конкретными условиями, традиционный подход остаётся вне конкуренции. Зато многие другие задачи, в которых компьютер раньше страшно уступал человеку (от перевода до распознавания голоса), с машинным обучением вышли на новый уровень. Google Фото сейчас уже не просто распознаёт котов, а сгруппировало мне снимки конкретно моего кота. И когда приложение Gmail впервые предложило мне варианты ответа на пришедшее письмо (оно с мая делает это для англоязычной переписки), я восхитился «какая умная штука, я реально вот так и хочу ответить», и в то же время невольно возмутился «эта умная штука читает мою почту».
Но хотя в текстах о подобных вещах используют слова «искусственный интеллект», важно понимать, что речь идёт об инструментах для выполнения конкретных задач, а не каком-то общем «интеллекте». Хотя smart reply в Gmail действительно использует доступ к моим письмам, это совершенно не «осознанное чтение переписки» в человеческом смысле слова. Распознавание котов может «справляться даже лучше человека» в вопросе распознавания котов — и только. Это настолько же узкий прикладной инструмент, как калькулятор.
Что тогда значат слова «искусственный интеллект»? В общем-то, ничего конкретного. Есть понятие «машинное обучение» с конкретным значением. Есть «глубинное обучение»/«нейросети» — тут речь об одном из подвидов машинного обучения, вокруг которого больше всего хайпа. А есть «искусственный интеллект» — и это словосочетание без строгого определения, которое все используют как хотят (Гугл применяет к своим проектам с машинным обучением, фантасты — к апокалиптичным сценариям), так что в итоге оно только сбивает людей с толку.
Поэтому, с одной стороны, машинное обучение привело к действительно масштабному прорыву, компьютеры стали действовать более «по-человечески» и справляться с «более человеческими» задачами. А с другой — на текущем этапе речь совершенно не идёт о general intelligence или самосознании. Думаю, что опасаться восстания сегодняшних нейросетей — примерно то же, что опасаться восстания калькуляторов. Возможно, когда-нибудь Скайнет нас всех ещё убьёт, но это будет явно не на нынешней итерации развития технологий.
Так что, если вы видите заголовок в духе «фейсбуку пришлось срочно отключить своих чатботов, придумавших свой язык», присмотритесь внимательно к источнику — тогда окажется, что в фейсбуке не паниковали «боты слишком поумнели», а допустили ошибку при постановке задачи, и спокойно отключили, чтобы перезапустить с правильными настройками.