Homepage
DraftSavedLearn more about joining the Partner Program

Dane Mitrev
Draft
A Cognitive Extraction Engine: Unified document structure and persistence made possible
Research papers’ structure differs heavily among different disciplines, topics, journals and authors. By default, a research paper is written in a specific way and using a specific format that it is a means of efficiently communicating scientific findings to the broad community of scientists in a uniform manner. Nevertheless, the scientific community in general, has tried to follow some kind of structure that at least makes distinction between main segments of a document such as an introduction and conclusion. Very often this structuring is loose and depends on the journal, authors’ preferences etc. However, there is a need for a common structure in order to be able to do efficient information retrieval as well as to be able to persist the information in a predefined custom format.
The abovementioned challenge, among a couple of others is addressed by cognitive extraction engines. The idea of such cognitive system is: given a set of research papers, to be able to build a scalable system that includes a model to automate the document structuring, classify the whole document into different segments, categorise the segments into textual classes and sub-classes and finally, persist the classified entities into a pre-defined format. This end-to-end approach will allow a raw document to be transformed into a TUD-XML custom formatted document. A processing pipeline is given in the image below and each of the processing modules is explained in the following sections.
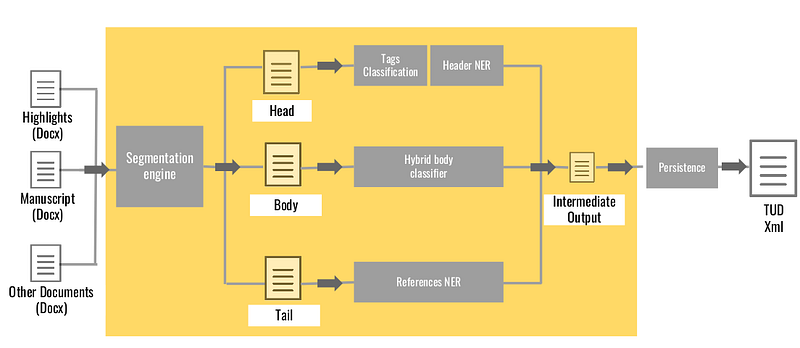
Segmentation Engine
The first module in the cognitive extraction engine is the segmentation engine, whose objective is to identify and categorise specific text regions in the document. In the described cognitive system it comprises of classifying the text into three different segments, namely: Header, Paragraphs and References. The segmentation model uses content-based features such as tokens’ specificity and document summary information, and it can be further improved by incorporating structure based features.
Tags Classification
The “Header” as the first output of the segmentation engine is then fed to the tags classification module. The tags classifier model extracts the following tags in the header segment: article title, author names, author affiliation, corresponding author info, keywords, and abstract. It uses LSTM network as classifier which stores the sequential information and makes decision based on collective information of the sequential data.
Header NER Model
The NER model which also takes the “Header” as input will classify the following tags into named entities: author names (first name, last name), author affiliation (affiliation organization, affiliation address, affiliation city, affiliation post/pin code, affiliation country), corresponding author info (author name, author organization, author address, author email). It actually uses a bi-directional LSTM on character embeddings and GloVe embeddings. It is able to extract the optimum contextual representation of every word.
Hybrid body classifier
The paragraph classifier or Hybrid body classifier (as described here) is the module that takes the document’s body as an input and it is able to classify the chunks of text into: paragraph or heading (at first level) and then classify the headings furthermore into section, subsection, title etc. The first level uses a rule-based probabilistic model and the second level uses a Naive Bayes as classifier.
References NER model
The references module is taking the document’s tail (as shown in the flowchart) as an input and it classifies the following tags into named entities: Authors’ names, Article title, Journal name, Volume etc. Similarly to the Header NER model the classifier is a bi-directional LSTM using character embeddings as well as GloVe embeddings of each of the words.
Conclusion
The cognitive extraction engine described above reaches 54.48% of accuracy on tags classification. There are some improvement directions possible for each of the separate modules such as: Structure-based features for the document segmentation model (including position and sequence-based features), probabilistic sequential model for the references classification, model training with larger amounts of real data (including noise) etc.