Формирование гипотез, запуск A/B-теста и анализ его результатов
https://t.me/AProfit
A/B-тестирование — обязательный подход к проверке продуктовых гипотез. Сегодня сложно удивить менеджера или аналитика тем, что организация проводит A/B-тесты на постоянной основе. Крупнейшие ИТ-компании инвестируют большие суммы в формирование отдельных команд, которые занимаются развитием платформ для запуска A/B-тестов, поиском и внедрением новых методик анализа результатов A/B-тестов.
Грамотное и плодотворное A/B-тестирование — это не просто разделение трафика на равные и неравные доли и оценка нескольких чисел в онлайн-калькуляторе. Это совокупность целого ряда статистических методов — тех самых, о которых вы читали в учебниках и изучали в университете.
В этой статье мы пошагово рассмотрим подход AIC к проведению А/В-тестирования — от процесса формирования гипотез до анализа результатов A/B-теста и их интерпретаций.
Важно: все примеры показаны на открытых dataframe. Пожалуйста, отнеситесь к этому с пониманием — мы не можем распространять реальные данные компаний.
- Для демонстрации основного подхода к A/B-анализу был выбран стандартный dataframe в R-iris.
- В описании процесса формирования гипотез применялись вымышленные аналитиками AIC данные.
Первый шаг: Формирование правильной гипотезы
Хорошая гипотеза рождается на стыке качественных и количественных данных. Большие данные покажут вам, где болит, а качественные погрузят в контекст проблемы.
Качественные данные указывают исследователю на проблемы реальных пользователей, которые обязательно должны быть подкреплены количественными показателями. Иначе можно столкнуться с тем, что мы начнем решать проблемы одного пользователя и упустим действительно важные вещи.

Процесс формирования гипотез начинается со знакомства с количественными данными. На этом этапе аналитики исследуют поведение пользователей, выявляют особенности продукта и находят узкие места.
Количественные данные собирают в следующие структуры:
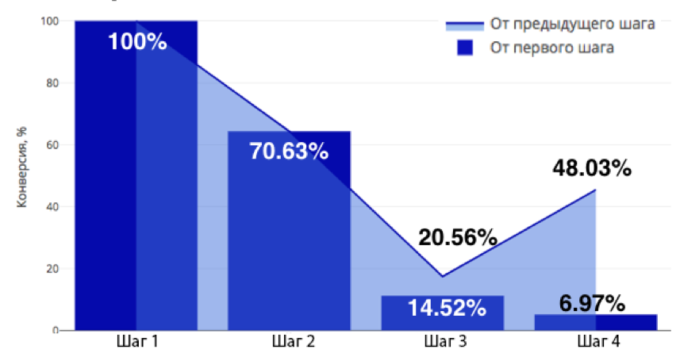
- Воронки.Воронка — самое наглядное представление линейного движения пользователя по направлению к целевому действию. Она доступна для понимания даже тем, кто никогда не сталкивался с анализом данных: в простой форме воронка показывает поведение пользователей и выявляет самые проблемные шаги.
- Стоит отметить, что самая частая ошибка при построении воронки — отсутствие разделения на сегменты. Допуская такую ошибку, вы рискуете упустить из вида проблемы отдельных групп пользователей.
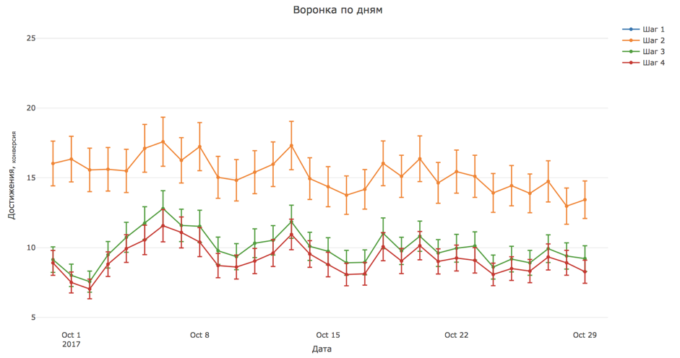
- Представление данных в динамике.
- Важно учитывать динамику поведения пользователей в зависимости от дней, недель, месяцев или любых других периодов, которые подходят под бизнес-цикл вашего продукта. Основная ценность метода в том, что он позволяет отличить случайные колебания в данных от статистически значимого роста и падения ключевых метрик.
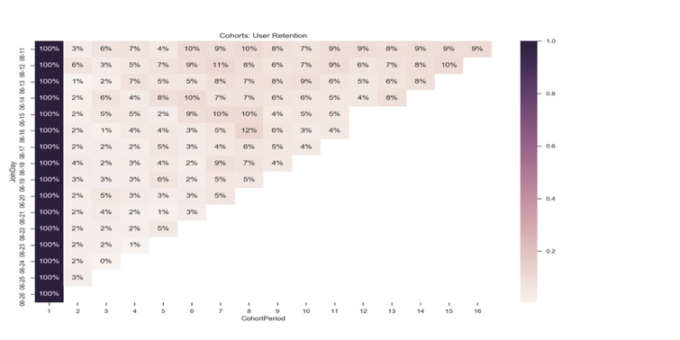
- Построение когорт.Не все пользователи, пришедшие на продукт, сразу же совершают целевое действие, будь то заполнение анкеты, покупка товара или приобретение услуги. Уход человека с одного из шагов воронки еще не говорит о наличии проблемы. Скорее всего, клиент просто ушел подумать или поискать альтернативные предложения. Построение когорт способно показать реальную картину прохождения воронки и возвращения пользователей на отдельные этапы. При построении когорт также важно проводить сегментацию.
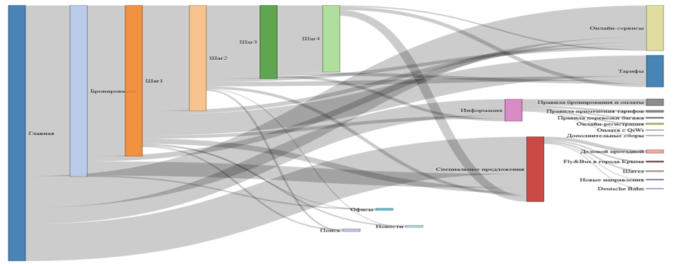
- Сценарии или нелинейные воронки.
- Пользователи в продукте ведут себя нелинейно. И чаще всего их реальное поведение оказывается совершенно не таким, как мы себе представляем. Построение сценариев переходов на основе реальных данных помогает трезво посмотреть на поведение аудитории.
- Данные по результатам исследований.
- После того, как узкие места продукта выявлены, самое время приступить к подробному исследованию найденных проблем. Для этого нужно подобрать оптимальный набор количественных и качественных методов.
- Среди них — очные и удаленные юзабилити-исследования, глубинные интервью, включенные наблюдения и прочее. Методов много, поэтому в процессе их выбора важно исходить из бизнес-задачи и не браться за все подряд. Этой теме мы посвятим отдельную статью в скором времени.
- После того, как собраны все необходимые данные, можно приступать к формированию и приоритизации гипотез.
- Приоритизация гипотез.Список сформулированных гипотез может получиться очень большим, поэтому он требует приоритизации и определения периодов запуска экспериментов. Для ранжирования гипотез существует несколько методов, среди них — PIE, CXC и другие. Подробнее о приоритете мы расскажем в отдельной статье.

Второй шаг: Запуск A/B-теста
На практике часто приходится работать с продуктами с долгим и сложным циклом разработки. У клиентов практически не остается времени на проработку гипотез, их реализацию и запуск экспериментов, поэтому эту часть работ мы берем на себя.
Для запуска экспериментов мы чаще всего используем GTM или Google Optimize, где разделяем трафик, готовим визуальное представление гипотезы и задаем условия ее отображения (сегменты и тому подобное). В результате мы получаем возможность менять не только цвет и тексты, но и создавать новые функциональные сущности или развивать имеющиеся, а также успешно сегментировать гипотезы еще на этапе запуска. Это дает большое преимущество в условиях ограниченных технических и финансовых ресурсов.
Третий шаг: Анализ результатов A/B-теста
A/B-тестирование — это чистая статистика. Примитивно использовать онлайн-калькулятор для анализа результатов теста, потому что появляется высокий риск ошибки. В этом случае не учитываются особенности данных в динамике.
Для уверенности в достоверности полученных результатов нужно комплексно подходить к процессу анализа. Грамотный процесс аналитики должен содержать в себе шесть этапов.
Этап 1. Оценка вариации данных
Первый важный этап анализа данных эксперимента — расчет вариации данных внутри экспериментальных выборок. Чтобы считать данные пригодными для анализа, нужно убедиться, что уровень вариации случайной величины находится в допустимых пределах.
Коэффициент вариации рассчитывается по формуле: V = σ / х *100% , где V — коэффициент вариации, σ — стандартное отклонение случайной величины от средней, х — средняя арифметическая случайной величины.
Этап 2. Графическое представление разброса данных
Построение графиков box-plot дает наглядное представление о дисперсии данных внутри групп, наличии или отсутствии выбросов и уровне средней медианы.
Нижняя и высшая точка каждого box-plot представляет наименьшее и наибольшее наблюдаемые значения. Нижняя и верхняя границы широкой части — это вторая и третья квартиль, а линия внутри — медиана. Если на графике присутствуют точки, лежащие за пределами основного тела графика, то в выборке присутствуют выбросы.
Этап 3. Описательные статистики
Параллельно с построением box-plot рассчитываются основные описательные статистики по целевым действиям (шагам воронки). Для этого в R используется библиотека psych, позволяющая посчитать все описательные статистики для каждой переменной внутри переданного на вход dataframe.

Этап 4. Анализ характера распределения
Если эксперимент проходил в течение достаточного количества времени, а собранные данные обладают допустимым уровнем вариации, то распределение чаще всего оказывается нормальным. В любом случае важно точно выявить закон распределения пользователей, чтобы подобрать соответствующие методы оценки достоверности результатов.

Этап 5. Расчет гомогенности дисперсии
Расчет критерия Бартлета, или коэффициента гомогенности дисперсии позволяет выявить разницу межгрупповых дисперсий по всем веткам эксперимента.
Этап 6. Поиск различий и оценка достоверности результатов
Обработка данных делается для понимания природы самих данных и для уверенного выбора метода оценки результатов.
В зависимости от ситуации мы используем несколько методов оценки: критерий Мана-Утни, однофакторный дисперсионный анализ и дисперсионный анализ по Краскелу-Уолису.
- Критерий Мана-Уитни. В случаях, когда не выполняется условие нормального распределения, используется критерий Уилкоксона или метод Мана-Уитни. Он отлично себя ведет на ненормально-распределенных выборках, но не более двух. Метод ранговый, следовательно он не чувствителен к типу распределения.
- Однофакторный дисперсионный анализ. Если в ходе предварительного анализа было выявлено, что данные подчиняются закону нормального распределения, то лучший способ выявить разницы между группами и оценками достоверности различий — дисперсионный анализ. Этот метод самый точный: он внутригрупповую и межгрупповую дисперсию в ходе подсчета результатов. Очень важно, чтобы значения были распределены по нормальному закону. Иначе есть риск получить недостоверную значимость разницы средних по входным группам.
- Дисперсионный анализ по Краскелу-Уолису. Важное условие для применения классического однофакторного дисперсионного анализа — нормальность распределения зависимой переменной и однородность (гомоскедастичность) дисперсий во всех сравниваемых группах. Если наблюдается существенное нарушение этих условий и ситуацию не получается исправить нормализацией, следует использовать дисперсионный анализ по Краскелу-Уоллису.