ddd
dd
The final season of Game of Thrones apparently raised a lot of eyebrows, so I wanted to dig deeper on how people felt before, during and after the final episode of Game of Thrones by turning towards the ever non-soft-spoken Twitter community.
In this blogpost, we’ll look at how an end-to-end solution can be built to tackle this problem, using the technology stack available on Google Cloud Platform.
Let’s go!

The focus is more on realising a fully working solution, rather than perfecting a single component in the entire pipeline. So any of the individual blocks can certainly be perfected!
To keep it readable, I haven’t included all of the code, but everything can be found on this Github repo, fully commented.
The basic idea
The rough outline for the entire pipeline looks something like this:
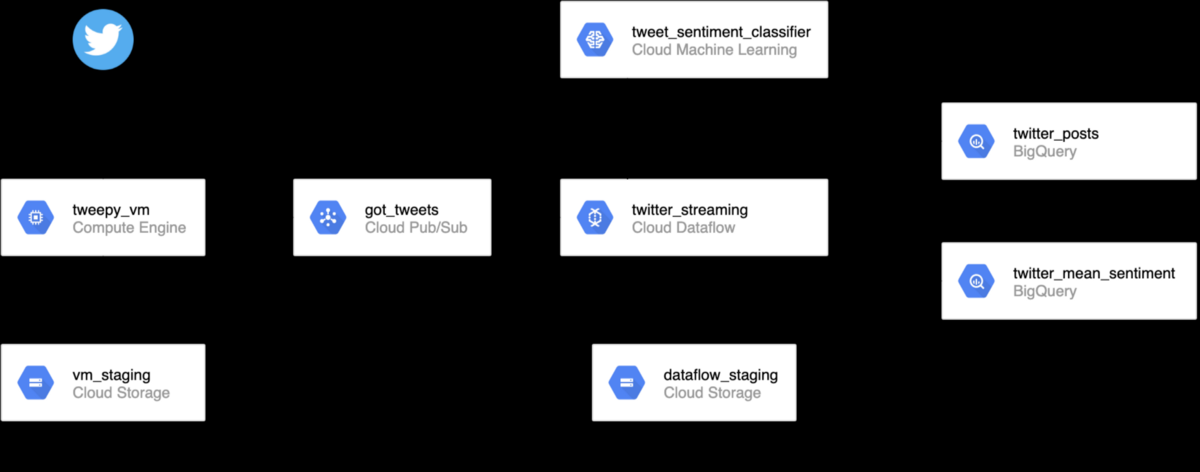
Basically, want can be done is:
- Have a script running on a VM, scraping tweets on Game of Thrones
- Have a PubSub topic to publish messages to
- Have a served ML model to classify tweet sentiment
- Have an Apache Beam streaming pipeline pick up the tweets and classify them
- Output the classified tweets to BigQuery, to do analyses on
In the rest of the post, we’ll glance over all of the various components separately, to finalize with a big orchestra of harmonious pipelining bonanza!
We will be relying heavily on Google Cloud Platform, with the following components:
- Compute Engine: to run the tweepy script on
- Cloud PubSub: to buffer the tweets
- Cloud Dataflow: managed Apache Beam runner
- AI Platform: to serve our ML model via an API
- BigQuery: to store our tweets in
1. Script on GCE to capture tweets

Capturing tweets related to several searchterms can easily be done using the tweepy API, like so: