Введение в глубокое обучение
nest it
Что такое «Глубокое обучение»?
Глубокое обучение - это функция искусственного интеллекта, которая имитирует работу человеческого мозга при обработке данных и создании шаблонов для использования в процессе принятия решений. Глубокое обучение - это подмножество машинного обучения в искусственном интеллекте (AI), в котором есть сети, способные к обучению, неконтролируемые из данных, которые не структурированы или не мечены

Также известен как глубокое структурированное обучение или иерархическое обучение
Алгоритмы глубокого обучения подобны тому, как нервная система структурирована, где каждый нейрон соединяется друг с другом и передает информацию.
Что такое нейронная сеть? Чтобы начать, начнем с искусственного нейрона, называемого персептроном. Так как работают персептроны? Персептрон принимает несколько двоичных входов, x 1, x 2, ... и производит один двоичный выход:
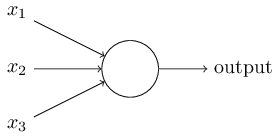
В показанном примере персептрон имеет три входа, x 1, x 2, x 3. В общем случае он может иметь больше или меньше входов. Розенблатт предложил простое правило для вычисления результата. Он представил веса , w 1, w 2, ..., действительные числа, выражающие важность соответствующих входных данных для выхода. Выход нейрона 0 или 1 определяется тем, что взвешенная сумма Σ jwjxj меньше или превышает некоторую пороговую величину . Подобно весам, порог представляет собой действительное число, которое является параметром нейрона. Для более точных алгебраических терминов:
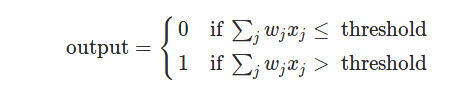
Вот и все, что работает персептрон!
Изучение алгоритмов звучит потрясающе. Но как мы можем разработать такие алгоритмы для нейронной сети? Предположим, у нас есть сеть персептронов, которую мы хотели бы использовать, чтобы научиться решать какую-то проблему.
Трудно понять, как постепенно изменять вес и предубеждения, чтобы сеть приблизилась к желаемому поведению. Возможно, есть какой-то умный способ обойти эту проблему. Но не сразу видно, как мы можем получить сеть персетронов, чтобы учиться.
Мы можем преодолеть эту проблему, введя новый тип искусственного нейрона, называемый сигмовидным нейроном . Сигмоидные нейроны подобны персептронам, но модифицированы так, что небольшие изменения в их весах и смещении вызывают лишь небольшое изменение в их выходе. Это важный факт, который позволит узнать сеть сигмовидных нейронов.
Подобно персептрону, сигмовидный нейрон имеет входы, x 1, x 2, .... Ааа! Но вместо 0 или 1 эти входы могут также принимать любые значения от 0 до 1.
Архитектура нейронной сети:
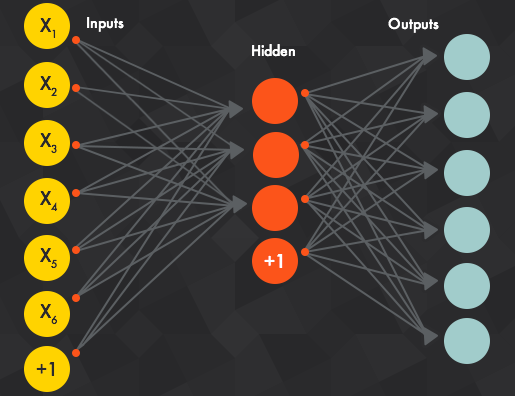
Значения входного слоя , или, другими словами, наши базовые данные, проходят через эту «сеть» скрытых слоев, пока они в конечном итоге не сходятся к выходному уровню. Выходной уровень - это наше предсказание: это может быть один узел, если модель просто выводит число или несколько узлов, если это проблема классификации много-классов.
Эти скрытые слои нейронной сети выполняют изменения в данных , в конечном счете , чувствовать, что его связь с целевой переменной. Каждый узел имеет вес, и он умножает его входное значение на этот вес. Сделайте это на нескольких разных уровнях, и Сеть может существенно манипулировать данными во что-то значимое.
Типы нейронной сети
1. Прямая нейронная сеть - искусственный нейрон:
- Простейшая форма ANN, где данные
- вход перемещается в одном направлении
- Данные проходят через входные узлы и выходят на выходные узлы
- Имеет фронтальную волну распространения и без обратного распространения, обычно используя классификационную функцию активации.
- Применение первичных нейронных сетей Feed обнаруживается в компьютерном видении и распознавании речи, когда классификация целевых классов сложна. Эти нейронные сети реагируют на шумные данные и просты в обслуживании.
Код для реализации прямого распространения с использованием numpy:
import numpy as np
def sigmoid(x):
"""
Calculate sigmoid
"""
return 1/(1+np.exp(-x))
# Network size
N_input = 4
N_hidden = 3
N_output = 2
np.random.seed(42)
# Make some fake data
X = np.random.randn(4)
weights_input_to_hidden = np.random.normal(0, scale=0.1, size=(N_input, N_hidden))
weights_hidden_to_output = np.random.normal(0, scale=0.1, size=(N_hidden, N_output))
# TODO: Make a forward pass through the network
hidden_layer_in = np.dot(X, weights_input_to_hidden)
hidden_layer_out = sigmoid(hidden_layer_in)
print('Hidden-layer Output:')
print(hidden_layer_out)
output_layer_in = np.dot(hidden_layer_out, weights_hidden_to_output)
output_layer_out = sigmoid(output_layer_in)
print('Output-layer Output:')
print(output_layer_out)
2. Рекуррентная нейронная сеть (RNN) - длительная краткосрочная память.
- Работает по принципу сохранения выходного слоя и подачи его обратно на вход, чтобы помочь в прогнозировании исхода слоя.
- Первый слой формируется аналогично первичной нейронной сети подачи с продуктом суммы весов и признаков.
- Так выглядит базовая повторяющаяся нейронная сеть,
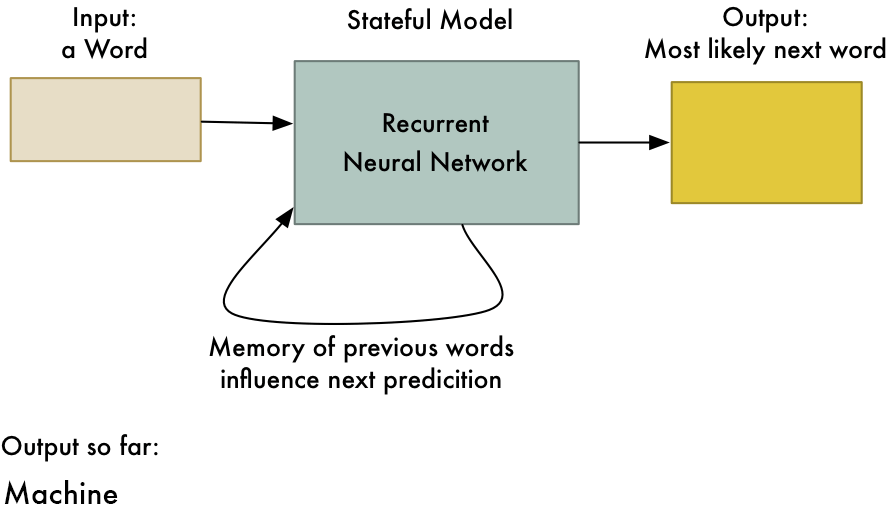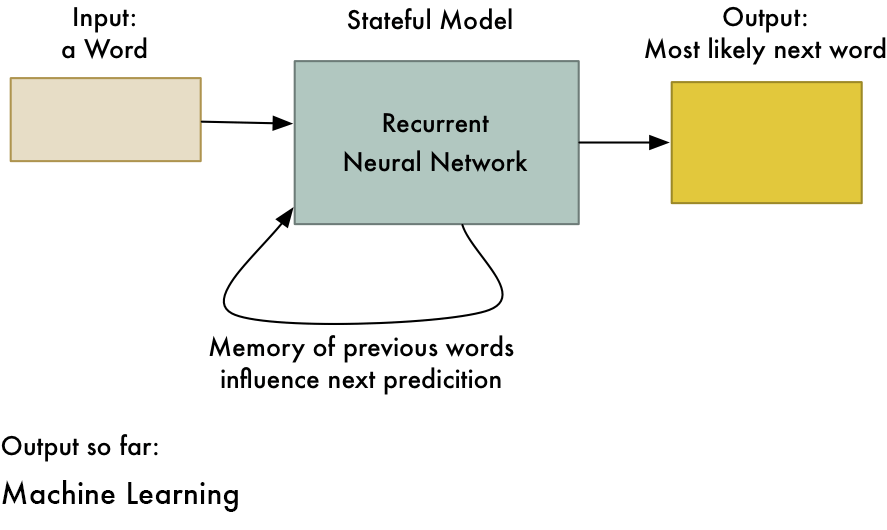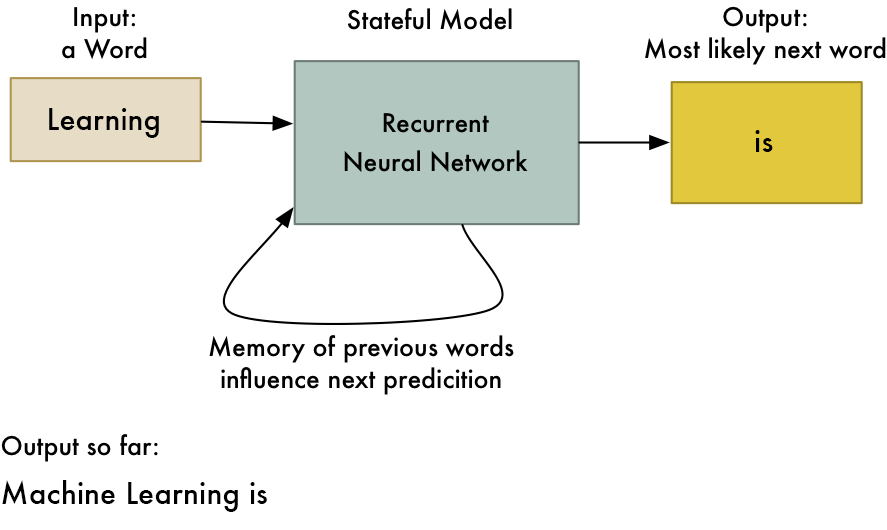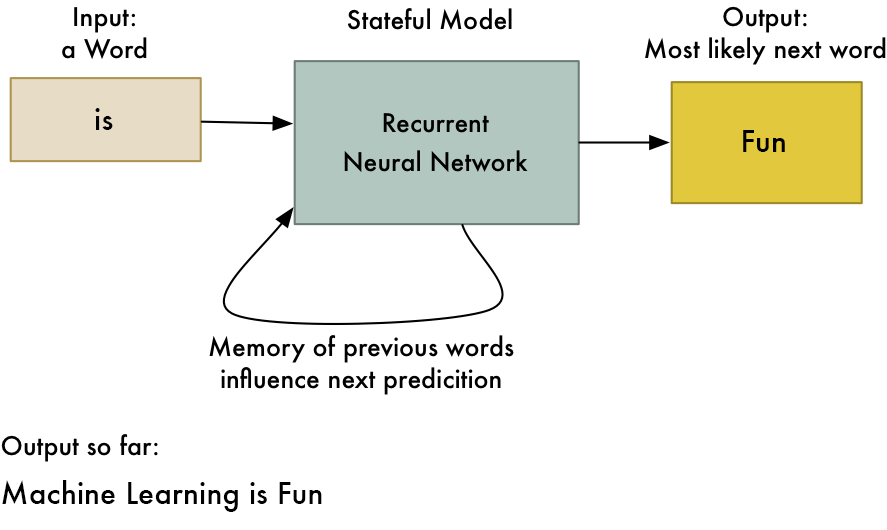
- Применение рекуррентных нейронных сетей можно найти в моделях преобразования текста в речь (TTS).
3. Сверточная нейронная сеть:
- Подобно восходящим нервным сетям, где у нейронов есть обучаемые способности и предвзятости.
- Его применение связано с обработкой сигналов и изображений, которые занимают OpenCV в области компьютерного зрения.
Ниже представлено представление ConvNet, в этой нейронной сети входные функции берутся в пакетном режиме, как фильтр. Это поможет сети запомнить изображения по частям и может вычислить операции.
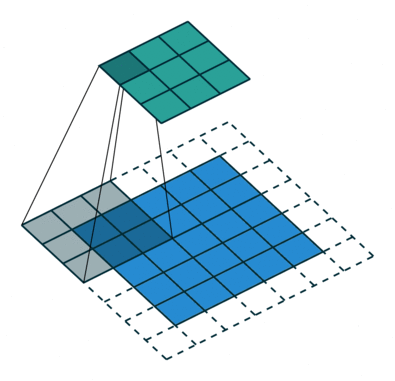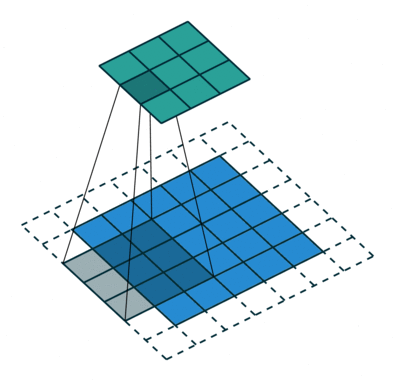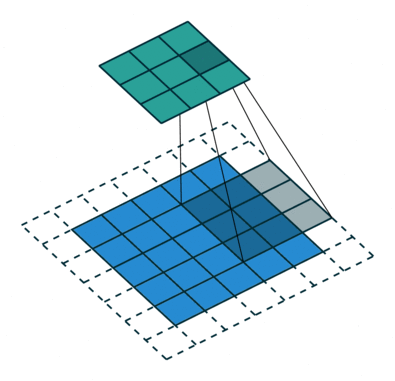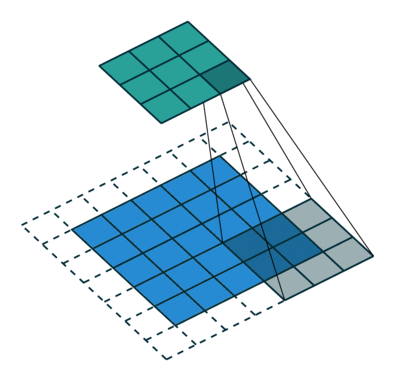
Существуют и другие продвинутые типы нейронных сетей, а также самоорганизующаяся нейронная сеть Kohonen, модульная нейронная сеть, радиальная базовая функция Neural Network.
Некоторые библиотеки Deep Learning:
TensorFlow - это библиотека программного обеспечения с открытым исходным кодом для численного расчета с использованием графиков потока данных. Узлы на графике представляют собой математические операции, в то время как ребра графа представляют собой многомерные массивы данных (тензоры), передаваемые между ними. Гибкая архитектура позволяет развернуть вычисления на один или несколько процессоров или графических процессоров на настольном, серверном или мобильном устройстве с помощью единого API. »
Caffe - « Caffe2» стремится обеспечить простой и простой способ экспериментировать с глубоким обучением и использовать вклад сообщества в новые модели и алгоритмы. Вы можете довести свои творения до масштабов, используя мощь графических процессоров в облаке или в массах на мобильных устройствах с кросс-платформенными библиотеками Caffe2. »
Torch - « Факел» - это научная вычислительная среда с широкой поддержкой алгоритмов машинного обучения, которая сначала ставит GPU. Он прост в использовании и эффективен благодаря легкому и быстрому языку сценариев LuaJIT и базовой реализации C / CUDA. »
Theano - « Theano» - это библиотека Python, которая позволяет вам определять, оптимизировать и оценивать математические выражения, особенно с многомерными массивами (numpy.ndarray). Используя Theano, можно достичь скоростей, соперничающих с реалистичными реализациями C для задач, связанных с большими объемами данных. Он также может превосходить C на процессоре на много порядков, воспользовавшись новейшими графическими процессорами. »
ConvNetJS- « ConvNetJS - это библиотека Javascript для обучения моделей Deep Learning (Neural Networks) полностью в вашем браузере. Откройте вкладку, и вы тренируетесь. Нет требований к программному обеспечению, нет компиляторов, нет установок, нет графических процессоров, нет пота. »