Часть 2.
LenkaGorЧасть 2. Обучение с подкреплением
«Брось робота в лабиринт и пусть ищет выход»
Сегодня используют для:
- Самоуправляемых автомобилей
- Роботов пылесосов
- Игр
- Автоматической торговли
- Управления ресурсами предприятий
Популярные алгоритмы: Q-Learning, SARSA, DQN, A3C, Генетический Алгоритм
Наконец мы дошли до вещей, которые, вроде, выглядят как настоящий искусственный интеллект. Многие авторы почему-то ставят обучение с подкреплением где-то между обучением с учителем и без, но я не понимаю чем они похожи. Названием?
Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде.
Нейросеть играет в Марио
Средой может быть даже видеоигра. Роботы, играющие в Марио, были популярны еще лет пять назад. Средой может быть реальный мир. Как пример — автопилот Теслы, который учится не сбивать пешеходов, или роботы-пылесосы, главная задача которых — напугать вашего кота до усрачки с максимальной эффективностью.
Знания об окружающем мире такому роботу могут быть полезны, но чисто для справки. Не важно сколько данных он соберёт, у него всё равно не получится предусмотреть все ситуации. Потому его цель — минимизировать ошибки, а не рассчитать все ходы. Робот учится выживать в пространстве с максимальной выгодой: собранными монетками в Марио, временем поездки в Тесле или количеством убитых кожаных мешков хихихих.
Выживание в среде и есть идея обучения с подкреплением. Давайте бросим бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях норм работает, почему бы на и роботах не попробовать.
Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться никого там не убивать. Когда робот начинает хорошо себя чувствовать в искусственном GTA, его выпускают тестировать на реальные улицы.
Запоминать сам город машине не нужно — такой подход называется Model-Free. Конечно, тут есть и классический Model-Based, но в нём нашей машине пришлось бы запоминать модель всей планеты, всех возможных ситуаций на всех перекрёстках мира. Такое просто не работает. В обучении с подкреплением машина не запоминает каждое движение, а пытается обобщить ситуации, чтобы выходить из них с максимальной выгодой.

Помните новость пару лет назад, когда машина обыграла человека в Го? Хотя незадолго до этого было доказано, что число комбинаций физически невозможно просчитать, ведь оно превышает количество атомов во вселенной. То есть если в шахматах машина реально просчитывала все будущие комбинации и побеждала, с Го так не прокатывало. Поэтому она просто выбирала наилучший выход из каждой ситуации и делала это достаточно точно, чтобы обыграть кожаного ублюдка.
Эта идея лежит в основе алгоритма Q-learning и его производных (SARSA и DQN). Буква Q в названии означает слово Quality, то есть робот учится поступать наиболее качественно в любой ситуации, а все ситуации он запоминает как простой марковский процесс.
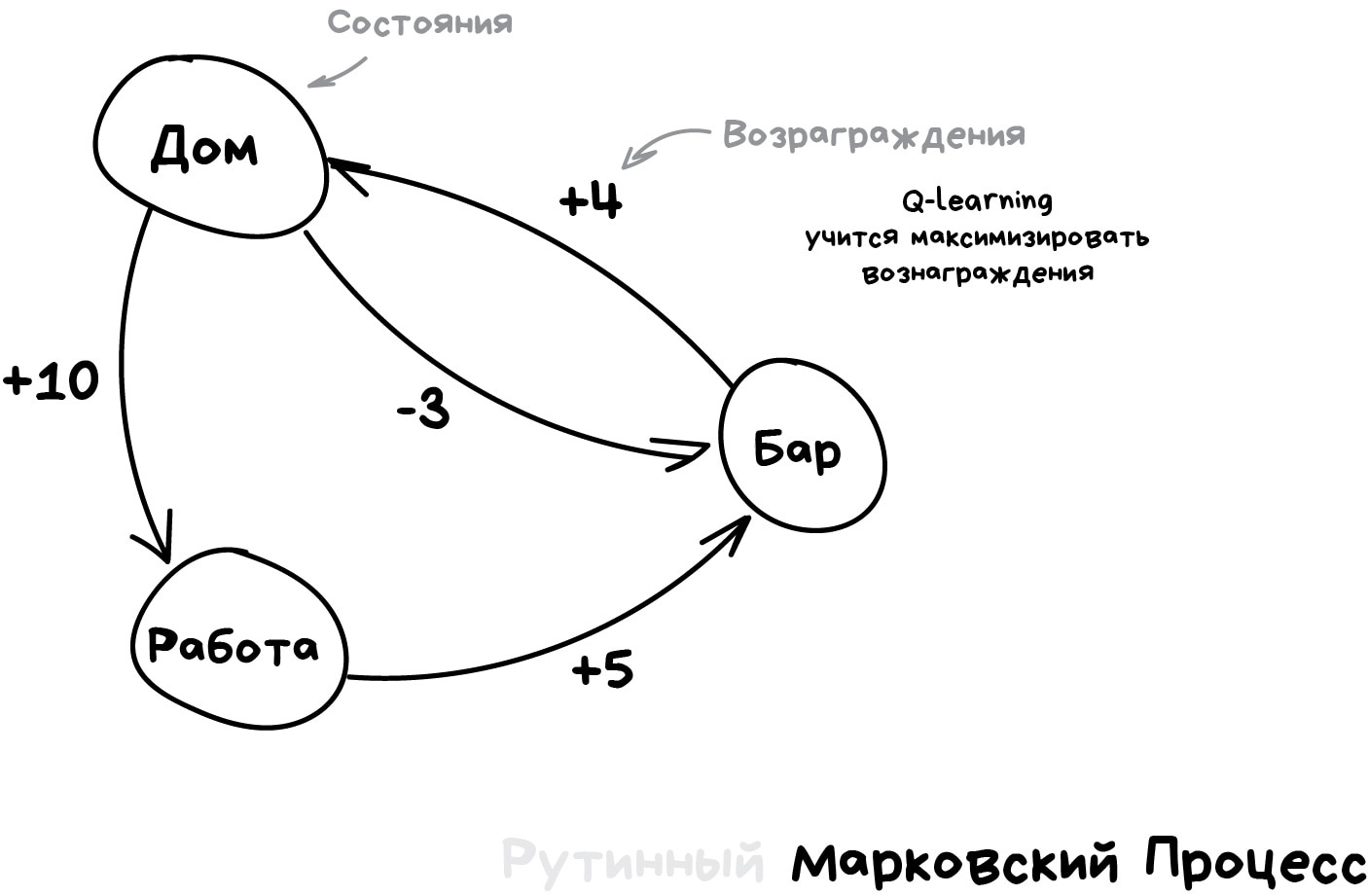
Машина прогоняет миллионы симуляций в среде, запоминая все сложившиеся ситуации и выходы из них, которые принесли максимальное вознаграждение. Но как понять, когда у нас сложилась известная ситуация, а когда абсолютно новая? Вот самоуправляемый автомобиль стоит у перекрестка и загорается зелёный — значит можно ехать? А если справа мчит скорая помощь с мигалками?
Ответ — хрен знает, никак, магии не бывает, исследователи постоянно этим занимаются, изобретая свои костыли. Одни прописывают все ситуации руками, что позволяет им обрабатывать исключительные случаи типа проблемы вагонетки. Другие идут глубже и отдают эту работу нейросетям, пусть сами всё найдут. Так вместо Q-learning'а у нас появляется Deep Q-Network (DQN).
Reinforcement Learning для простого обывателя выглядит как настоящий интеллект. Потому что ух ты, машина сама принимает решения в реальных ситуациях! Он сейчас на хайпе, быстро прёт вперёд и активно пытается в нейросети, чтобы стать еще точнее (а не стукаться о ножку стула по двадцать раз).
Потому если вы любите наблюдать результаты своих трудов и хотите популярности — смело прыгайте в методы обучения с подкреплением (до чего ужасный русский термин, каждый раз передёргивает) и заводите канал на ютюбе! Даже я бы смотрел.
Помню, у меня в студенчестве были очень популярны генетические алгоритмы (по ссылке прикольная визуализация). Это когда мы бросаем кучу роботов в среду и заставляем их идти к цели, пока не сдохнут. Затем выбираем лучших, скрещиваем, добавляем мутации и бросаем еще раз. Через пару миллиардов лет должно получиться разумное существо. Теория эволюции в действии.
Так вот, генетические алгоритмы тоже относятся к обучению с подкреплением, и у них есть важнейшая особенность, подтвержденная многолетней практикой — они нахер никому не нужны.
Человечеству еще не удалось придумать задачу, где они были бы реально эффективнее других. Зато отлично заходят как студенческие эксперименты и позволяют кадрить научруков «достижениями» особо не заморачиваясь. На ютюбе тоже зайдёт.
Часть 3. Ансамбли
«Куча глупых деревьев учится исправлять ошибки друг друга»
Сегодня используют для:
- Всего, где подходят классические алгоритмы (но работают точнее)
- Поисковые системы (★)
- Компьютерное зрение
- Распознавание объектов
Популярные алгоритмы: Random Forest, Gradient Boosting
Теперь к настоящим взрослым методам. Ансамбли и нейросети — наши главные бойцы на пути к неминуемой сингулярности. Сегодня они дают самые точные результаты и используются всеми крупными компаниями в продакшене. Только о нейросетях трещат на каждом углу, а слова «бустинг» и «бэггинг», наверное, пугают только хипстеров с теккранча.
При всей их эффективности, идея до издевательства проста. Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причём даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Ансамбль можно собрать как угодно, хоть случайно нарезать в тазик классификаторы и залить регрессией. За точность, правда, тогда никто не ручается. Потому есть три проверенных способа делать ансамбли.
Стекинг Обучаем несколько разных алгоритмов и передаём их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.
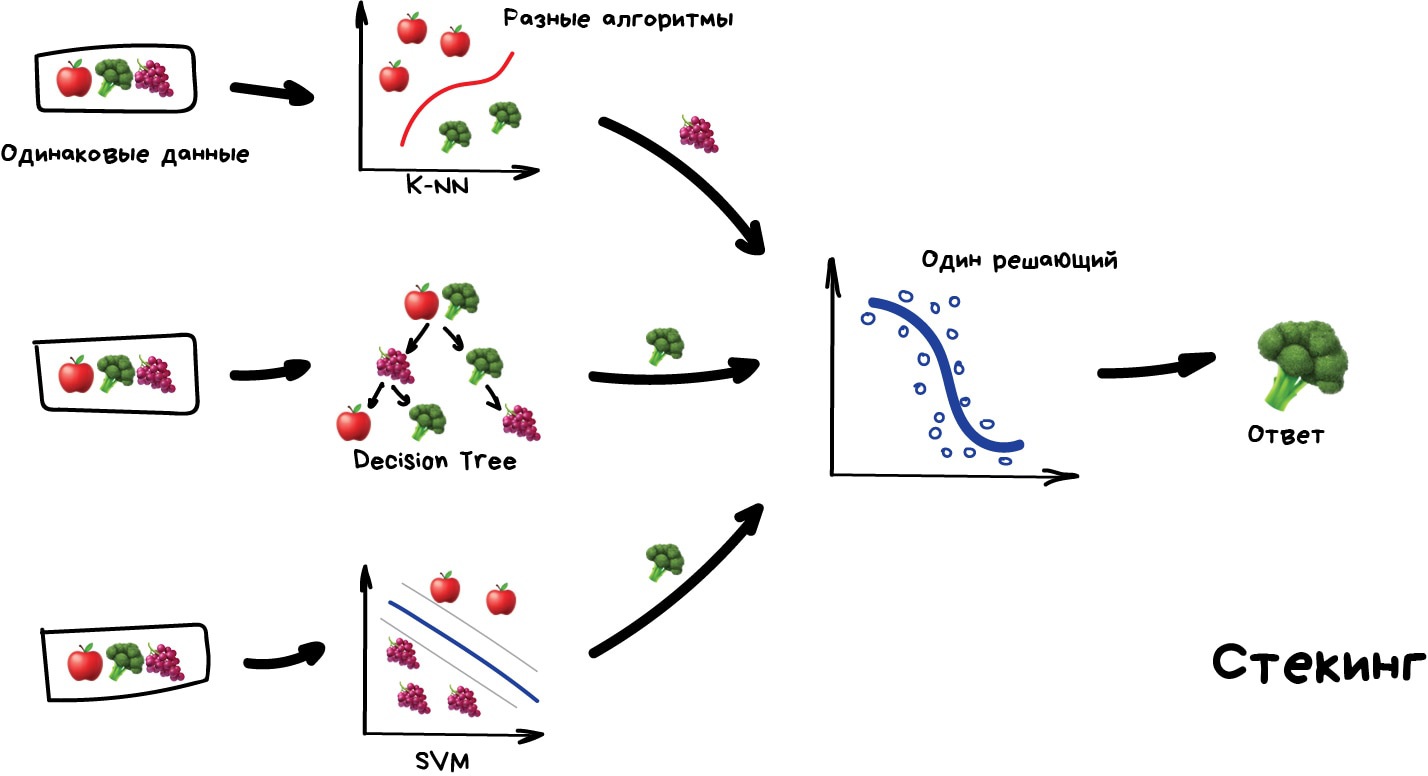
Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию.
Чисто из опыта — стекинг на практике применяется редко, потому что два других метода обычно точнее.
Беггинг Он же Bootstrap AGGregatING. Обучаем один алгоритм много раз на случайных выборках из исходных данных. В самом конце усредняем ответы.
Данные в случайных выборках могут повторяться. То есть из набора 1-2-3 мы можем делать выборки 2-2-3, 1-2-2, 3-1-2 и так пока не надоест. На них мы обучаем один и тот же алгоритм несколько раз, а в конце вычисляем ответ простым голосованием.
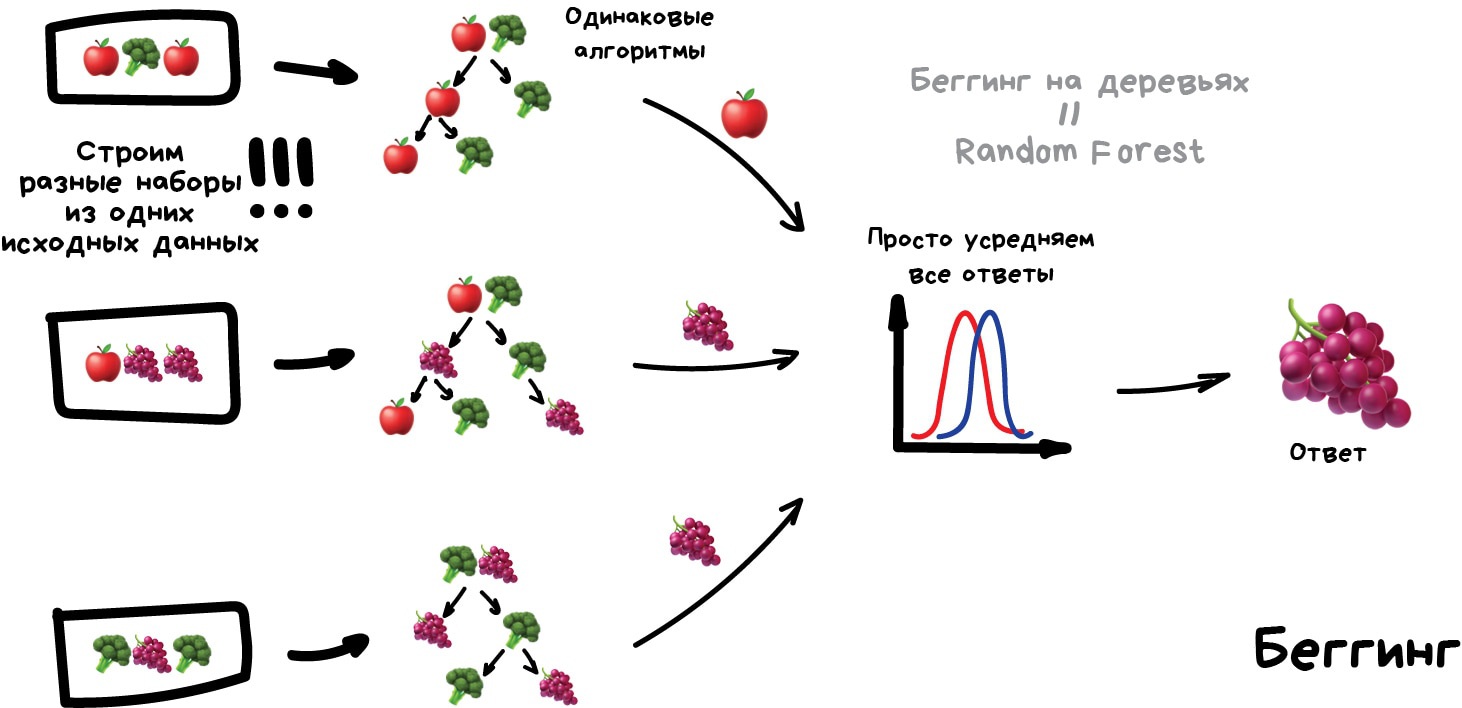
Самый популярный пример беггинга — алгоритм Random Forest, беггинг на деревьях, который и нарисован на картинке. Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Дикая способность параллелиться даёт беггингу преимущество даже над следующим методом, который работает точнее, но только в один поток. Хотя можно разбить на сегменты, запустить несколько... ах кого я учу, сами не маленькие.

Бустинг Обучаем алгоритмы последовательно, каждый следующий уделяет особое внимание тем случаям, на которых ошибся предыдущий.
Как в беггинге, мы делаем выборки из исходных данных, но теперь не совсем случайно. В каждую новую выборку мы берём часть тех данных, на которых предыдущий алгоритм отработал неправильно. То есть как бы доучиваем новый алгоритм на ошибках предыдущего.
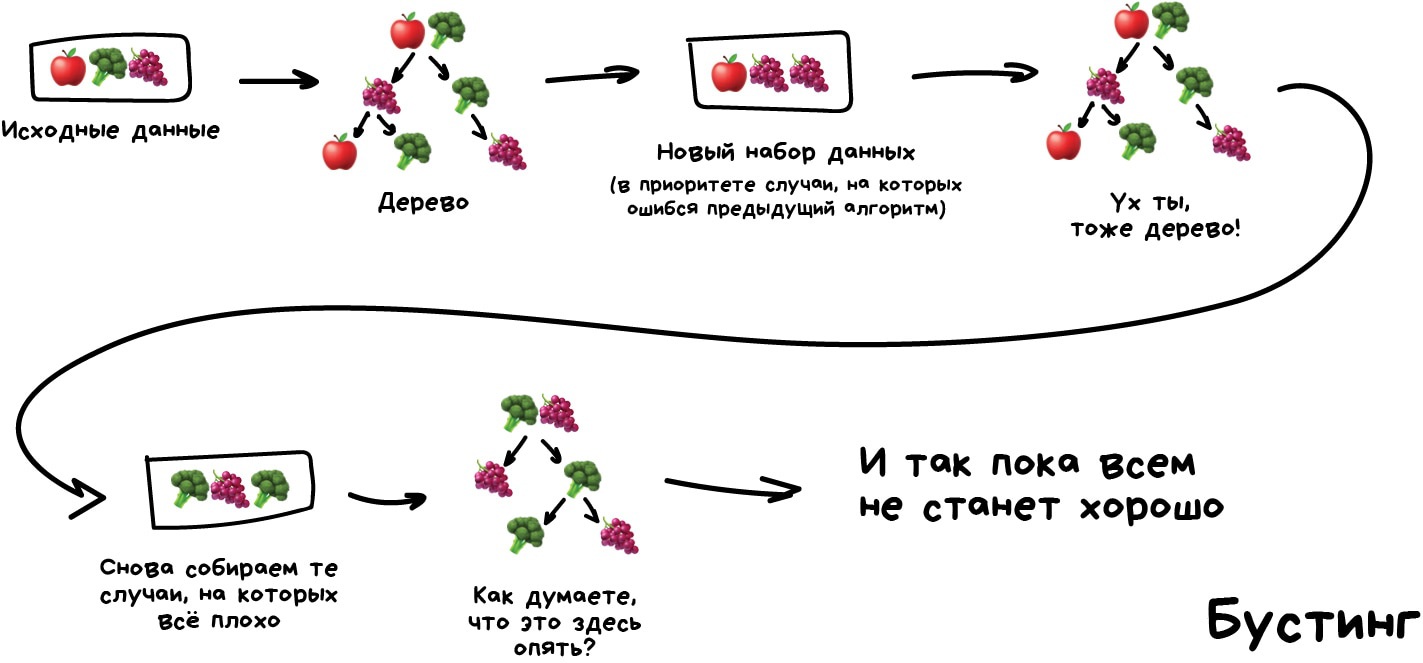
Плюсы — неистовая, даже нелегальная в некоторых странах, точность классификации, которой позавидуют все бабушки у подъезда. Минусы уже названы — не параллелится. Хотя всё равно работает быстрее нейросетей, которые как гружёные камазы с песком по сравнению с шустрым бустингом.
Нужен реальный пример работы бустинга — откройте Яндекс и введите запрос. Слышите, как Матрикснет грохочет деревьями и ранжирует вам результаты? Вот это как раз оно, Яндекс сейчас весь на бустинге. Про Google не знаю.
Сегодня есть три популярных метода бустинга, отличия которых хорошо донесены в статье CatBoost vs. LightGBM vs. XGBoost
Часть 4. Нейросети и глубокое обучение
«У нас есть сеть из тысячи слоёв, десятки видеокарт, но мы всё еще не придумали где это может быть полезно. Пусть рисует котиков!»
Сегодня используют для:
- Вместо всех вышеперечисленных алгоритмов вообще
- Определение объектов на фото и видео
- Распознавание и синтез речи
- Обработка изображений, перенос стиля
- Машинный перевод
Популярные архитектуры: Перцептрон, Свёрточные Сети (CNN), Рекуррентные Сети (RNN), Автоэнкодеры
Если вам хоть раз не пытались объяснить нейросеть на примере якобы работы мозга, расскажите, как вам удалось спрятаться? Я буду избегать этих аналогий и объясню как нравится мне.
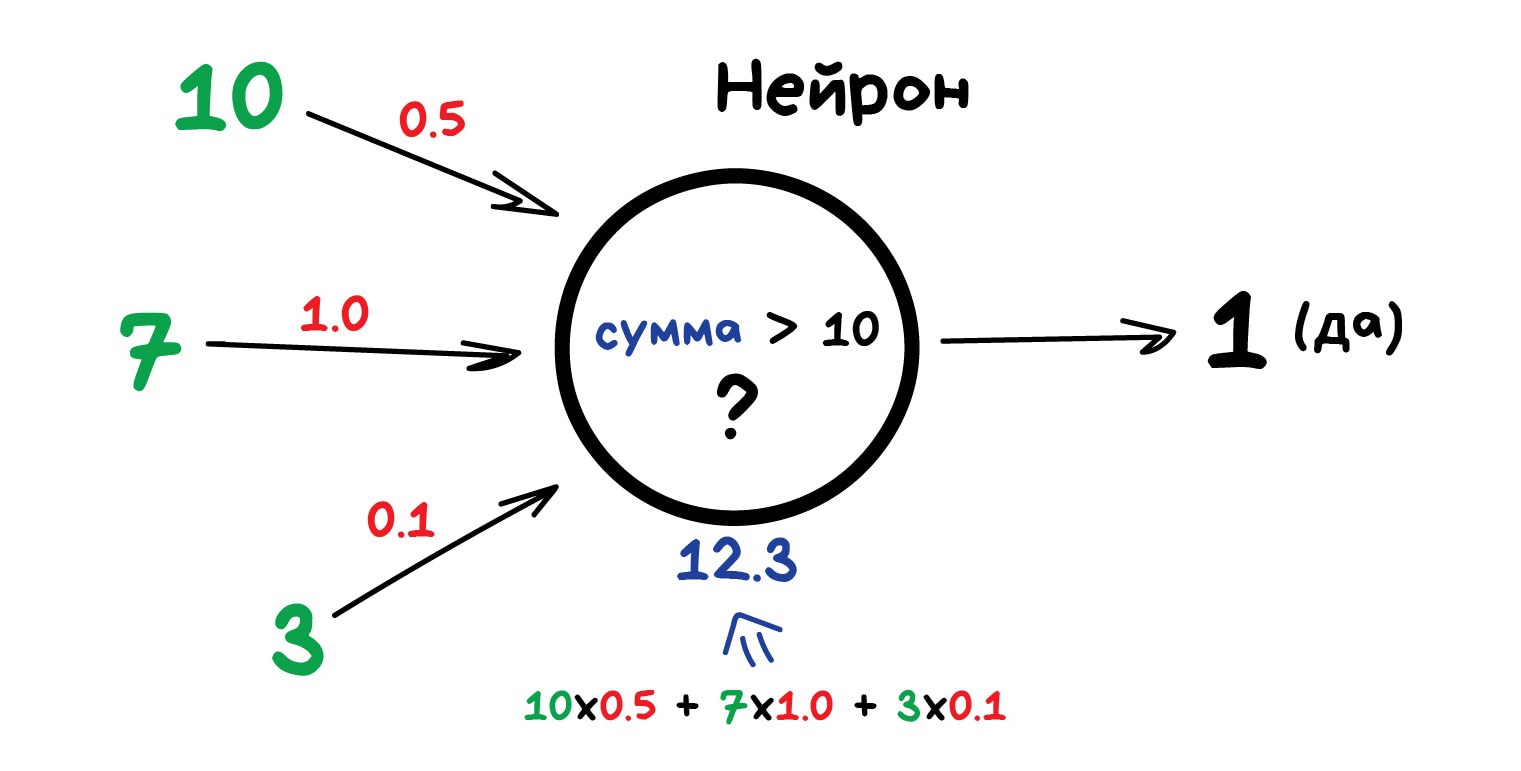
Любая нейросеть — это набор нейронов и связей между ними. Нейрон лучше всего представлять просто как функцию с кучей входов и одним выходом. Задача нейрона — взять числа со своих входов, выполнить над ними функцию и отдать результат на выход. Простой пример полезного нейрона: просуммировать все цифры со входов, и если их сумма больше N — выдать на выход единицу, иначе — ноль.
Связи — это каналы, через которые нейроны шлют друг другу циферки. У каждой связи есть свой вес — её единственный параметр, который можно условно представить как прочность связи. Когда через связь с весом 0.5 проходит число 10, оно превращается в 5. Сам нейрон не разбирается, что к нему пришло и суммирует всё подряд — вот веса и нужны, чтобы управлять на какие входы нейрон должен реагировать, а на какие нет.
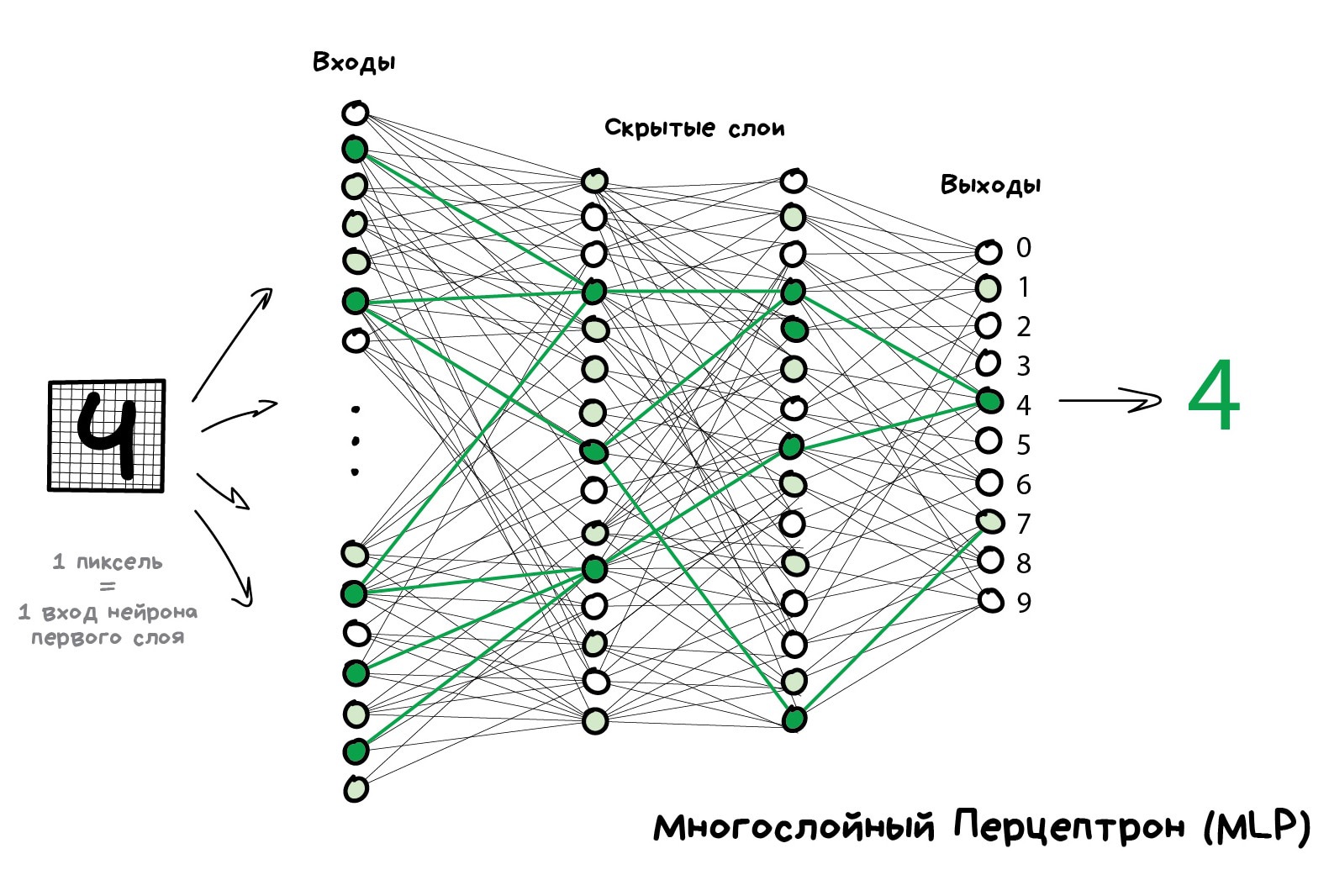
Чтобы сеть не превратилась в анархию, нейроны решили связывать не как захочется, а по слоям. Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя. Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего.
Если нафигачить достаточное количество слоёв и правильно расставить веса в такой сети, получается следующее — подав на вход, скажем, изображение написанной от руки цифры 4, чёрные пиксели активируют связанные с ними нейроны, те активируют следующие слои, и так далее и далее, пока в итоге не загорится самый выход, отвечающий за четвёрку. Результат достигнут.
В реальном программировании, естественно, никаких нейронов и связей не пишут, всё представляют матрицами и считают матричными произведениями, потому что нужна скорость. У меня есть два любимых видео, в которых весь описанный мной процесс наглядно объяснён на примере распознавания рукописных цифр. Посмотрите, если хотите разобраться.
Такая сеть, где несколько слоёв и между ними связаны все нейроны, называется перцептроном (MLP) и считается самой простой архитектурой для новичков. В боевых задачах лично я никогда её не встречал.
Когда мы построили сеть, наша задача правильно расставить веса, чтобы нейроны реагировали на нужные сигналы. Тут нужно вспомнить, что у нас же есть данные — примеры «входов» и правильных «выходов». Будем показывать нейросети рисунок той же цифры 4 и говорить «подстрой свои веса так, чтобы на твоём выходе при таком входе всегда загоралась четвёрка».
Сначала все веса просто расставлены случайно, мы показываем сети цифру, она выдаёт какой-то случайный ответ (весов-то нет), а мы сравниваем, насколько результат отличается от нужного нам. Затем идём по сети в обратном направлении, от выходов ко входам, и говорим каждому нейрону — так, ты вот тут зачем-то активировался, из-за тебя всё пошло не так, давай ты будешь чуть меньше реагировать на вот эту связь и чуть больше на вон ту, ок?
Через тысяч сто таких циклов «прогнали-проверили-наказали» есть надежда, что веса в сети откорректируются так, как мы хотели. Научно этот подход называется Backpropagation или «Метод обратного распространения ошибки». Забавно то, что чтобы открыть этот метод понадобилось двадцать лет. До него нейросети обучали как могли.
Второй мой любимый видос более подробно объясняет весь процесс, но всё так же просто, на пальцах.
Хорошо обученная нейросеть могла притворяться любым алгоритмом из этой статьи, а зачастую даже работать точнее. Такая универсальность сделала их дико популярными. Наконец-то у нас есть архитектура человеческого мозга, говорили они, нужно просто собрать много слоёв и обучить их на любых данных, надеялись они. Потом началась первая Зима ИИ, потом оттепель, потом вторая волна разочарования.
Оказалось, что на обучение сети с большим количеством слоёв требовались невозможные по тем временам мощности. Сейчас любое игровое ведро с жифорсами превышает мощность тогдашнего датацентра. Тогда даже надежды на это не было, и в нейросетях все сильно разочаровались.
Пока лет десять назад не бомбанул диплёрнинг.
На английской википедии есть страничка Timeline of machine learning, где хорошо видны всплески радости и волны отчаяния.
В 2012 году свёрточная нейросеть порвала всех в конкурсе ImageNet, из-за чего в мире внезапно вспомнили о методах глубокого обучения, описанных еще в 90-х годах. Теперь-то у нас есть видеокарты!
Отличие глубокого обучения от классических нейросетей было в новых методах обучения, которые справлялись с большими размерами сетей. Однако сегодня лишь теоретики разделяют, какое обучение можно считать глубоким, а какое не очень. Мы же, как практики, используем популярные «глубокие» библиотеки типа Keras, TensorFlow и PyTorch даже когда нам надо собрать мини-сетку на пять слоёв. Просто потому что они удобнее всего того, что было раньше. Мы называем это просто нейросетями.
Расскажу о двух главных на сегодняшний момент.
Свёрточные Нейросети (CNN)
Свёрточные сети сейчас на пике популярности. Они используются для поиска объектов на фото и видео, распознавания лиц, переноса стиля, генерации и дорисовки изображений, создания эффектов типа слоу-мо и улучшения качества фотографий. Сегодня CNN применяют везде, где есть картинки или видео. Даже в вашем айфоне несколько таких сетей смотрят на ваши голые фотографии, чтобы распознать объекты на них. Если там, конечно, есть что распознавать хехехе.

Картинка выше — результат работы библиотеки Detectron, которую Facebook недавно заопенсорсил
Проблема с изображениями всегда была в том, что непонятно, как выделять на них признаки. Текст можно разбить по предложениям, взять свойства слов из словарей. Картинки же приходилось размечать руками, объясняя машине, где у котика на фотографии ушки, а где хвост. Такой подход даже назвали «handcrafting признаков» и раньше все так и делали.
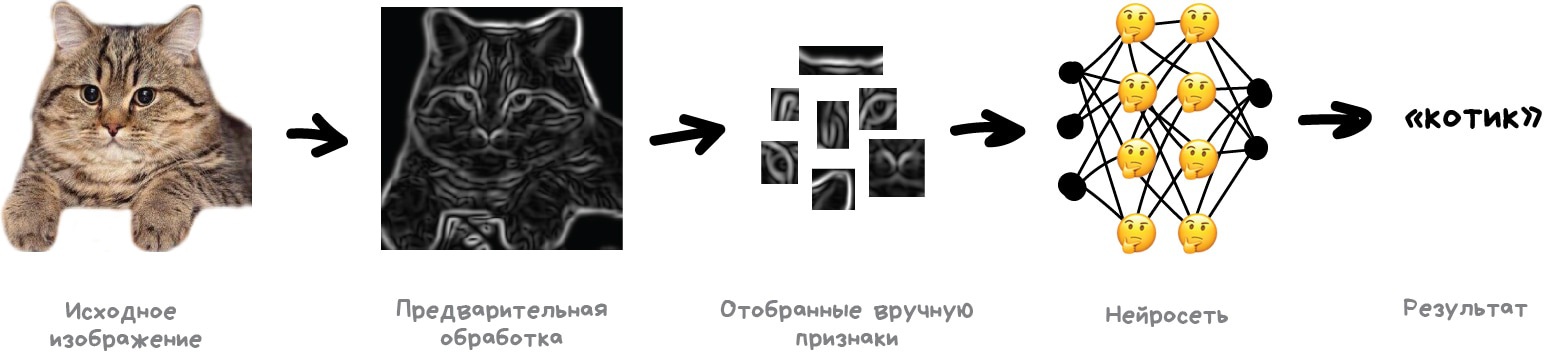
Проблем у ручного крафтинга много.
Во-первых, если котик на фотографии прижал ушки или отвернулся — всё, нейросеть ничего не увидит.
Во-вторых, попробуйте сами сейчас назвать хотя бы десять характерных признаков, отличающих котиков от других животных. Я вот не смог. Однако когда ночью мимо меня пробегает чёрное пятно, даже краем глаза я могу сказать котик это или крыса. Потому что человек не смотрит только на форму ушей и количество лап — он оценивает объект по куче разных признаков, о которых сам даже не задумывается. А значит, не понимает и не может объяснить машине.
Получается, машине надо самой учиться искать эти признаки, составляя из каких-то базовых линий. Будем делать так: для начала разделим изображение на блоки 8x8 пикселей и выберем какая линия доминирует в каждом — горизонтальная [-], вертикальная [|] или одна из диагональных [/]. Могут и две, и три, так тоже бывает, мы не всегда точно уверены.
На выходе мы получим несколько массивов палочек, которые по сути являются простейшими признаками наличия очертаний объектов на картинке. По сути это тоже картинки, просто из палочек. Значит мы можем вновь выбрать блок 8x8 и посмотреть уже, как эти палочки сочетаются друг с другом. А потом еще и еще.
Такая операция называется свёрткой, откуда и пошло название метода. Свёртку можно представить как слой нейросети, ведь нейрон — абсолютно любая функция.
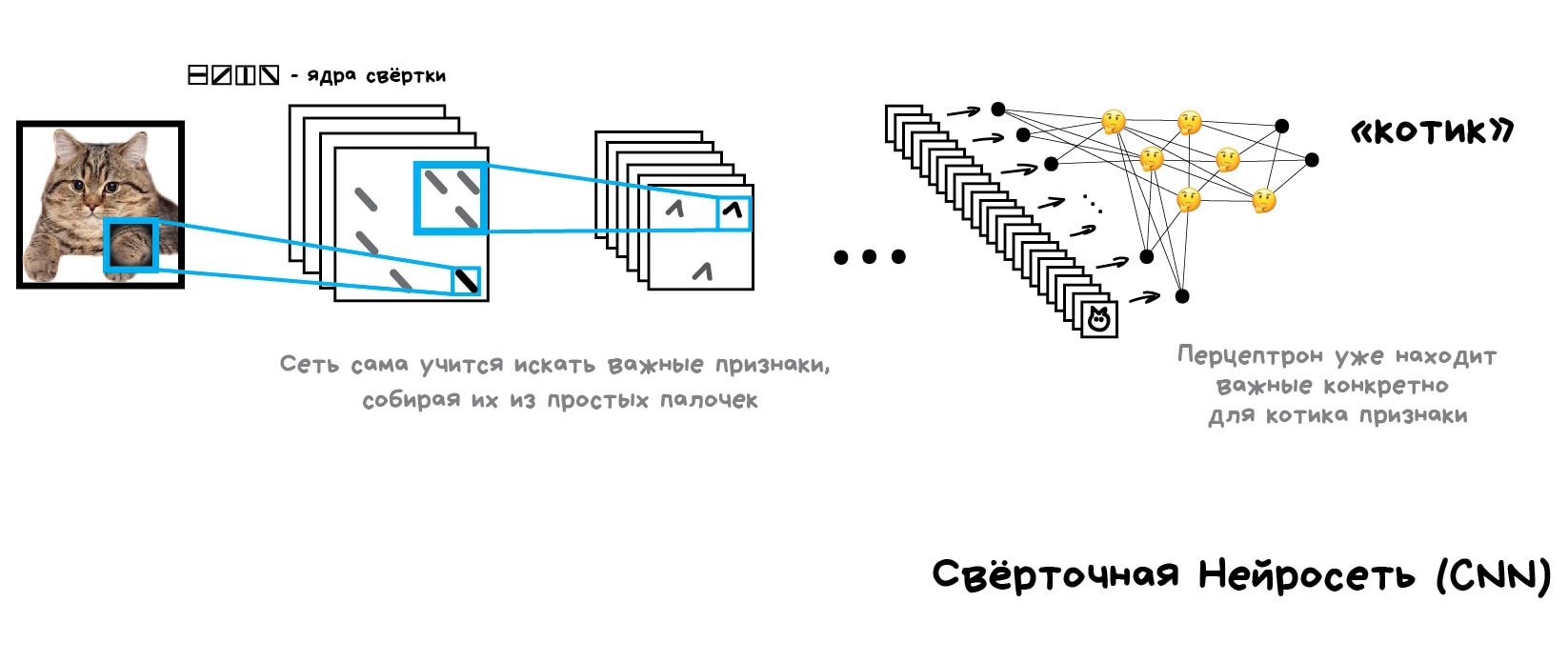
Когда мы прогоняем через нашу нейросеть кучу фотографий котов, она автоматически расставляет большие веса тем сочетаниям из палочек, которые увидела чаще всего. Причём неважно, это прямая линия спины или сложный геометрический объект типа мордочки — что-то обязательно будет ярко активироваться.
На выходе же мы поставим простой перцептрон, который будет смотреть какие сочетания активировались и говорить кому они больше характерны — кошке или собаке.

Красота идеи в том, что у нас получилась нейросеть, которая сама находит характерные признаки объектов. Нам больше не надо отбирать их руками. Мы можем сколько угодно кормить её изображениями любых объектов, просто нагуглив миллион картинок с ними — сеть сама составит карты признаков из палочек и научится определять что угодно.
По этому поводу у меня даже есть несмешная шутка:
Дай нейросети рыбу — она сможет определять рыбу до конца жизни. Дай нейросети удочку — она сможет определять и удочку до конца жизни...
Рекуррентные Нейросети (RNN)
Вторая по популярности архитектура на сегодняшний день. Благодаря рекуррентным сетям у нас есть такие полезные вещи, как машинный перевод текстов (читайте мой пост об этом) и компьютерный синтез речи. На них решают все задачи, связанные с последовательностями — голосовые, текстовые или музыкальные.
Помните олдскульные голосовые синтезаторы типа Microsoft Sam из Windows XP, который смешно произносил слова по буквам, пытаясь как-то склеить их между собой? А теперь посмотрите на Amazon Alexa или Алису от Яндекса — они сегодня не просто произносят слова без ошибок, они даже расставляют акценты в предложении!
Нейросеть учится разговаривать
Потому что современные голосовые помощники обучают говорить не буквами, а фразами. Но сразу заставить нейросеть целиком выдавать фразы не выйдет, ведь тогда ей надо будет запомнить все фразы в языке и её размер будет исполинским. Тут на помощь приходит то, что текст, речь или музыка — это последовательности. Каждое слово или звук — как бы самостоятельная единица, но которая зависит от предыдущих. Когда эта связь теряется — получатся дабстеп.
Достаточно легко обучить сеть произносить отдельные слова или буквы. Берём кучу размеченных на слова аудиофайлов и обучаем по входному слову выдавать нам последовательность сигналов, похожих на его произношение. Сравниваем с оригиналом от диктора и пытаемся максимально приблизиться к идеалу. Для такого подойдёт даже перцептрон.
Вот только с последовательностью опять беда, ведь перцептрон не запоминает что он генерировал ранее. Для него каждый запуск как в первый раз. Появилась идея добавить к каждому нейрону память. Так были придуманы рекуррентные сети, в которых каждый нейрон запоминал все свои предыдущие ответы и при следующем запуске использовал их как дополнительный вход. То есть нейрон мог сказать самому себе в будущем — эй, чувак, следующий звук должен звучать повыше, у нас тут гласная была (очень упрощенный пример).
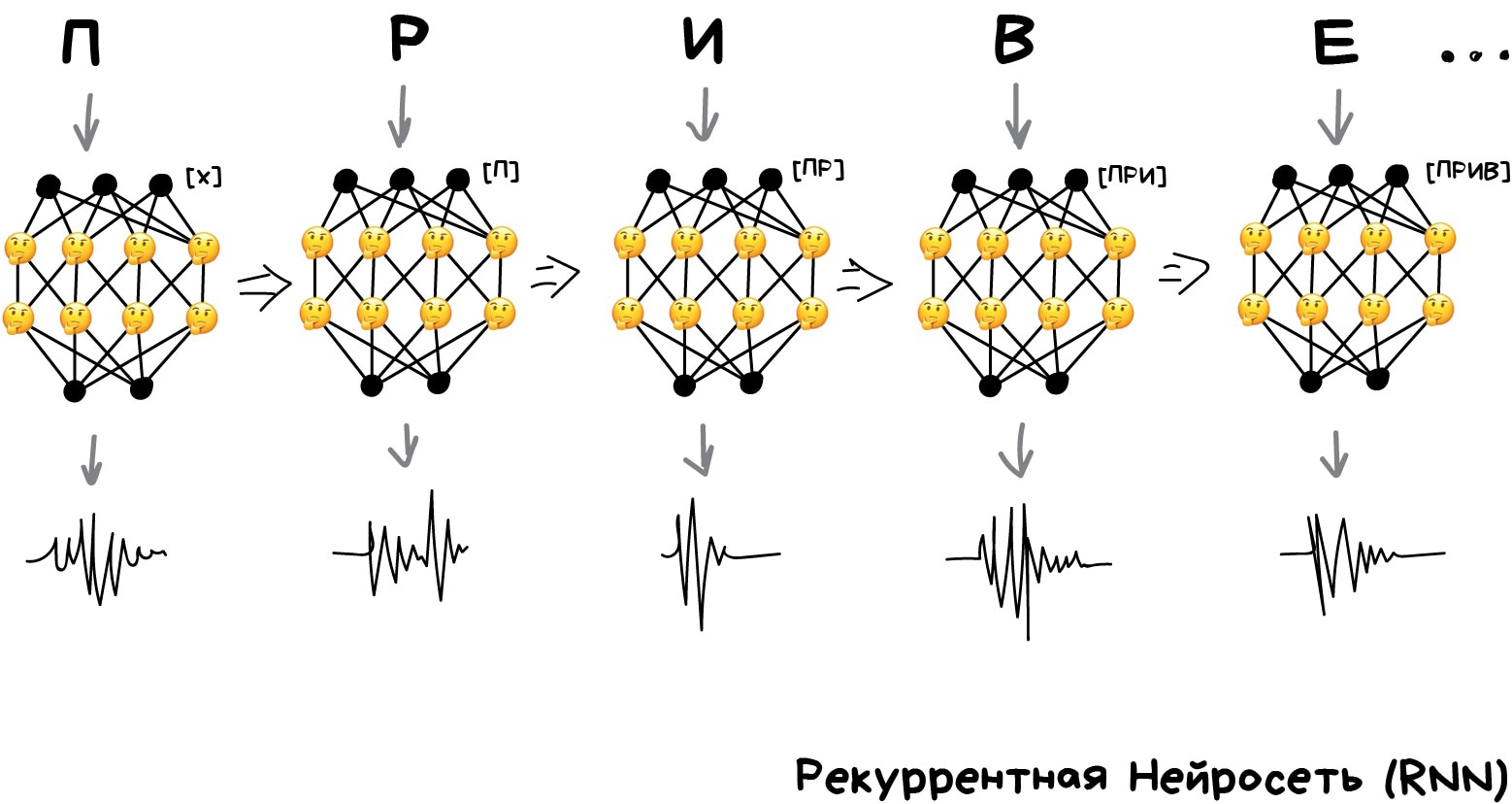
Была лишь одна проблема — когда каждый нейрон запоминал все прошлые результаты, в сети образовалось такое дикое количество входов, что обучить такое количество связей становилось нереально.
Когда нейросеть не умеет забывать — её нельзя обучить (у людей та же фигня).
Сначала проблему решили в лоб — обрубили каждому нейрону память. Но потом придумали в качестве этой «памяти» использовать специальные ячейки, похожие на память компьютера или регистры процессора. Каждая ячейка позволяла записать в себя циферку, прочитать или сбросить — их назвали ячейки долгой и краткосрочной памяти (LSTM).
Когда нейрону было нужно поставить себе напоминалку на будущее — он писал это в ячейку, когда наоборот вся история становилась ненужной (предложение, например, закончилось) — ячейки сбрасывались, оставляя только «долгосрочные» связи, как в классическом перцептроне. Другими словами, сеть обучалась не только устанавливать текущие связи, но и ставить напоминалки.
Просто, но работает!
CNN + RNN = фейковый Обама
Озвученные тексты для обучения начали брать откуда угодно. Даже базфид смог выгрузить видеозаписи выступлений Обамы и весьма неплохо научить нейросеть разговаривать его голосом. На этом примере видно, что имитировать голос — достаточно простая задача для сегодняшних машин. С видео посложнее, но это пока.
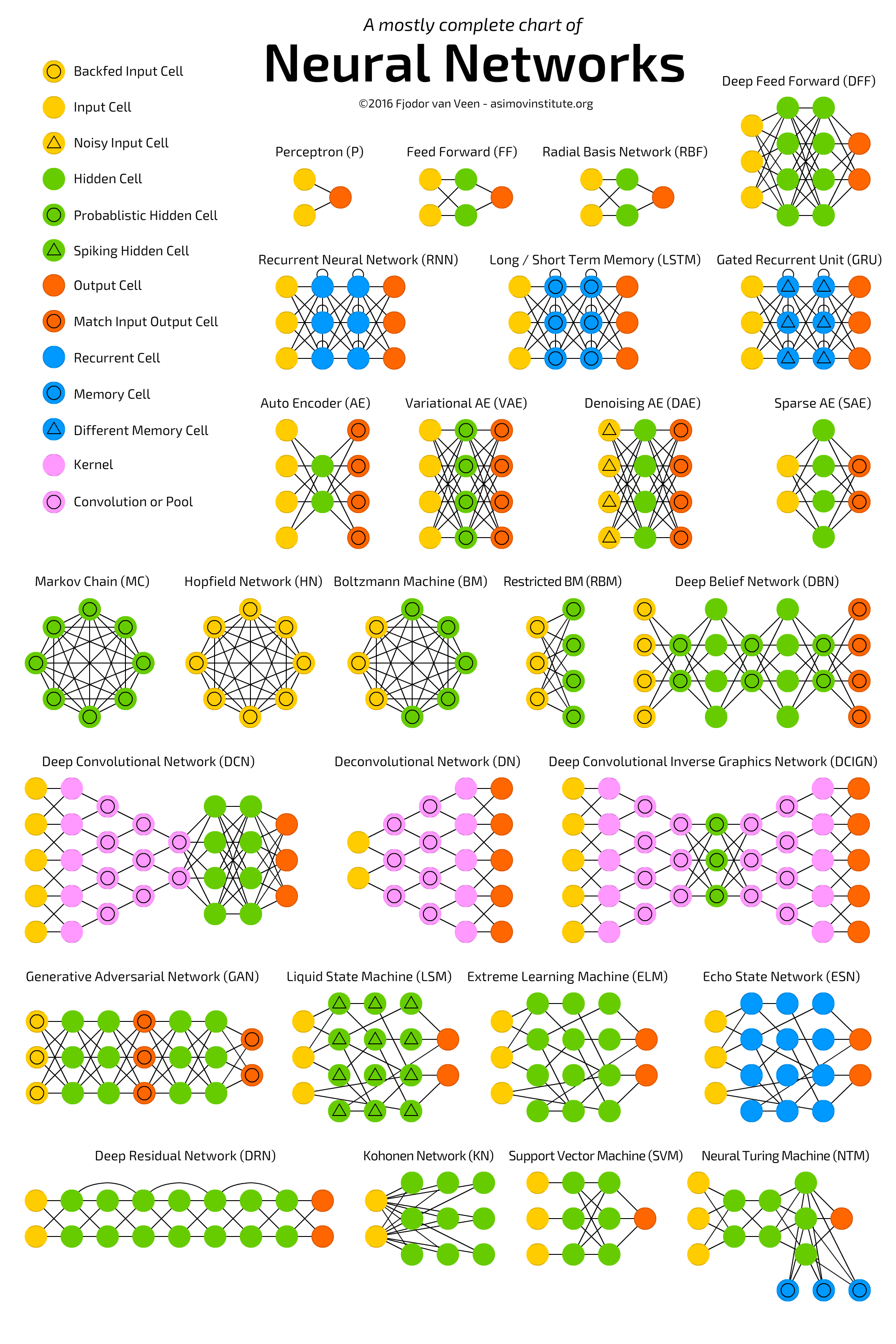
Про архитектуры нейросетей можно говорить бесконечно. Любознательных отправляю смотреть схему и читать
статью Neural Network Zoo, где собраны все типы нейронных сетей. Есть и русская версия.
Заключение: когда на войну с машинами?
На вопрос «когда машины станут умнее нас и всех поработят?» я всегда отвечаю, что он заранее неправильный. В нём слишком много скрытых условий, который примаются как как данность.
Вот мы говорим «станут умнее нас». Значит мы подразумеваем, что существует некая единая шкала интеллекта, наверху которой находится человек, собаки пониже, а глупые голуби тусят в самом низу. Получается человек должен превосходить нижестоящих животных во всём, так? А в жизни не так. Средняя белка может помнить тысячу тайников в орешками, а я не могу вспомнить где ключи. Получается интеллект — это набор разных навыков, а не единая измеримая величина? Или просто запоминание орешков в него не входит? А убивание человеков входит?
Ну и самый интересный для меня вопрос — почему мы заранее считаем, что возможности человеческого мозга ограничены? В интернетах обожают рисовать графики, на которых технологический прогресс обозначен экспонентой, а возможности кожаных мешков константой. Но так ли это?
Вот давайте, прямо сейчас в уме умножьте 1680 на 950. Да, знаю, вы даже пытаться не станете. Но дай вам калькулятор, это займёт две секунды. Значит ли это, что вы только что расширили возможности своего мозга с помощью калькулятора? Можно ли продолжать их расширять другими машинами? Я вот использую заметки на телефоне — значит ли это, что я расширяю свою память с помощью машины?
Получается, мы уже успешно расширяем способности нашего мозга с помощью машин. Или нет?
Подумайте. У меня всё.
