Building
James LeeThe K-Nearest Neighbors algorithm, K-NN for short, is a classic machine learning work horse algorithm that is often overlooked in the day of deep learning. In this tutorial, we will build a K-NN algorithm in Scikit-Learn and run it on the MNIST dataset. From there, we will build our own K-NN algorithm in the hope of developing a classifier with both better accuracy and classification speed than the Scikit-Learn K-NN.
K-Nearest Neighbors Classification Model
The K-Nearest Neighbors algorithm is a supervised machine learning algorithm that is simple to implement, and yet has the ability to make robust classifications. One of the biggest advantages of K-NN is that it is a lazy-learner. This means the model requires no training, and can get right to classifying data, unlike its other ML siblings such as SVM, regression, and multi-layer perceptions.
How K-NN Works
To classify some given data point, p, a K-NN model will first compare p to every other point it has available in its data base using some distance metric. A distance metric is something such as Euclidean distance, a simple function that takes two points, and returns the distance between these two points. Thus, it can be assumed that two points with a smaller distance between them are more similar than two points with a larger distance between them. This is the central idea behind K-NN.
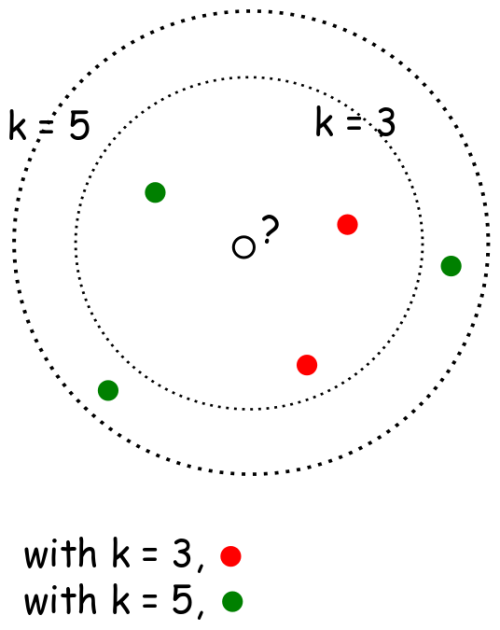
This process will return an unordered array, where each entry in the array holds the distance between p and one of the n data points in the models data base. So the returned array will be of size n. This is where the K part of K-nearest neighbors comes in: k is some arbitrary value selected (usually between 3–11) that tells the model how many most similar points to p it should consider when classifying p. The model will then take those k most similar values, and use a voting technique to decide how to classify p, as exemplified by the image below.
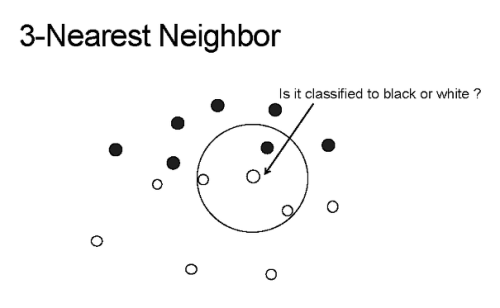
The K-NN model in the image has a k value of 3, and the point in the center with the arrow pointing to it is p, the point that needs to be classified. As you can see, the three points in the circle are the three points closest to, or most similar to p. So using a simple voting technique, p would be classified as “white”, as white makes up the majority of the k most similar values.
Pretty cool! Surprisingly, this simple algorithm can achieve superhuman results in certain situations, and can be applied to a wide variety of problems, as we will see next.
Implementing a K-NN Algorithm in Scikit-Learn to Classify MNIST Images
The Data:
For this example, we will be using the ubiquitous MNIST data set. The MNIST data set is one of the most common data sets used in machine learning, as it is easy to implement, yet acts as a solid method for proving out models.

MNIST is a data set of 70,000 handwritten digits numbered 0–9. No two handwritten digits are the same, and some can be very hard to correctly classify. The human benchmark for classifying MNIST is about 97.5% accuracy, so our goal is to beat that!
The Algorithm:
We will be using the KNeighborsClassifier() from the Scikit-Learn Python library to start. This function takes many arguments, but we will only have to worry about a few in this example. Specifically, we will only be passing a value for the n_neighbors argument (this is the k value). The weights argument gives the type of voting system used by the model, where the default value is uniform, meaning each of the k points is equally weighted in classifying p. The algorithm argument will also be left at its default value of auto, as we want Scikit-Learn to find the optimal algorithm to use for classifying the MNIST data itself.
Below, I embed a Jupyter Notebook that builds the K-NN classifier with Scikit-Learn. Here we go!
Fantastic! We built a very simple K-nearest neighbors model using Scikit-Learn, that got extraordinary performance on the MNIST data set.
The problem? Well it took a long time to classify those points (8 minutes and almost 4 minutes, respectively, for the two data sets), and ironically K-NN is still one of the fastest classification methods. There has to be a faster way…
Building a Faster Model
Most K-NN models use Euclidean or Manhattan distance as the go-to distance metric. These metrics are simple and perform well in a wide variety of situations.
One distance metric that is seldom used is cosine similarity. Cosine similarity is generally not the go-to distance metric as it violates the triangle inequality, and doesn’t work on negative data. However, cosine similarity is perfect for MNIST. It is fast, simple, and gets slightly better accuracy than other distance metrics on MNIST. But to really eke out the best performance possible, we will have to write our own K-NN model. After making a K-NN model on our own, we should get better performance than the Scikit-Learn model, and maybe even better accuracy. Lets take a look at the notebook below where we build our own K-NN model.
As shown in the notebook, the K-NN model we made ourselves outperforms the Scikit-Learn K-NN in terms of both classification speed (by a sizable margin) and accuracy (1% improvement on one data set)! Now, we can move ahead with implementing this model in practice, knowing that we have developed a truly speedy algorithm.
Conclusion
That was a lot, but we learned a couple valuable lessons. First, we learned how K-NN works, and how to implement it with ease. But most importantly, we learned that it is important to always consider the problem you are trying to solve and the tools you have available for solving that problem. At times, it is best to take the time experimenting with — and yes, building your own models — when solving a problem. As proved in the notebooks, it can pay huge dividends: our second, proprietary model gave use a 1.5–2 times speedup, saving the entity using the model a lot of time.
If you want to learn more, I encourage you to checkout this GitHub repository, where you will find a more thorough analysis between the two models, and some more interesting features about our faster K-NN model!
Please leave any comments, criticism, or questions in the comments!