Big data
Capítulo 3. Métodos estadísticos y de aprendizaje automático para el tratamiento de big data
Página 9 de 16
CAPÍTULO 3
Métodos estadísticos y de aprendizaje automático para el tratamiento de big data
Introducción
Como hemos indicado, con frecuencia al hablar de big data se pone el énfasis en los aspectos tecnológicos referidos a la capacidad de recoger y almacenar datos, que ha crecido de manera exponencial en los últimos años gracias al uso masivo de sensores y dispositivos móviles. Sin embargo, una parte esencial de cualquier proyecto de big data consiste en emplear adecuadamente algoritmos para su procesamiento y, en particular, algoritmos que permiten aprender de los datos, de manera que la aplicación que se desarrolla pueda predecir comportamientos futuros y realizar tareas que entendemos como inteligentes. Son los aspectos que en la introducción se designan como estadísticos y de aprendizaje automático, que designaremos en lo que sigue como machine learning (ML).
En general, podemos dividir estos algoritmos en tres grandes bloques: de preprocesamiento, de análisis y de visualización. Se suelen aplicar de manera secuencial y constituyen el ciclo de desarrollo de un proyecto de ciencia de datos aunque, como veremos, dicho ciclo puede recorrerse múltiples veces hasta conseguir el comportamiento adecuado. Revisamos después los aspectos principales de las tres grandes tipologías metodológicas de análisis referidas al aprendizaje supervisado, al no supervisado y al aprendizaje por refuerzo.
Preprocesamiento, análisis y visualización
Comencemos describiendo la primera fase de preprocesamiento. Es probablemente la más mecánica y menos valorada en los proyectos de big data, pero puede ocupar hasta un 80% del tiempo total de un científico de datos. Si no se realiza de manera correcta, todos los resultados posteriores quedarán, en gran medida, invalidados. Como se acostumbra a decir, garbage in, garbage out. En esta fase se reciben los datos capturados en estado puro. Suelen provenir de fuentes diferentes, pueden encontrarse físicamente en servidores o bases de datos con ubicaciones distintas y se presentan en gran variedad de formatos, tanto estructurados (tablas y bases de datos) como no estructurados (texto libre, imágenes, audio, vídeo, etc.). Con frecuencia, la información que resulta realmente útil para elaborar un modelo suele ser un subconjunto relativamente pequeño de toda la almacenada, de modo que hay que identificar dónde se encuentra tal información y extraerla, como mencionábamos cuando hacíamos referencia a extraer valor de los datos. Además, rara vez ocurre que la información se encuentra de manera íntegra y limpia, por lo que una tarea siempre necesaria es proceder a la limpieza de los datos, por ejemplo para uniformar formatos, codificar caracteres, verificar que no existen valores corruptos, etc. También suele ocurrir que algunas entradas de una base de datos no contienen el valor requerido, encontrándose su campo vacío (null). Esto puede deberse a que dicho dato se ha perdido en la transmisión o, simplemente, a que el formulario de recogida de datos no obligaba a recogerlo para su validación y el dispositivo o persona que realizó la entrada dejó tal campo vacío. Existen numerosos métodos para rellenar la información ausente con criterios estadísticos, operación que se conoce como “imputación de datos”.
En una segunda fase de análisis se procede a construir modelos para apoyar las tareas deseadas: predecir precios de venta de inmuebles, predecir los clientes que se darán de baja de un servicio, clasificar imágenes para reconocimiento facial, segmentar los usuarios de una plataforma digital, etc. En esta fase concurren fundamentalmente conocimientos de tipo estadístico, matemático y de programación, para tomar los datos ya limpios, crear y entrenar un modelo y evaluar su eficiencia antes de ponerlo en producción. En función del tipo de problema que afrontamos solemos distinguir entre tres paradigmas: aprendizaje supervisado, aprendizaje no supervisado y aprendizaje por refuerzo, según desarrollamos más abajo. Como parte del ciclo de desarrollo, con frecuencia en el proceso de elaboración de un modelo se vuelve a la fase de preprocesamiento para crear variables nuevas a partir de los datos en estado puro. Si en la primera fase hablamos de extracción de variables (feature extraction), en la segunda tratamos de combinar estas para elaborar otras variables derivadas o secundarias que puedan resultar informativas de cara a la predicción (feature engineering). Por ejemplo, en un modelo para detectar fraude en pagos con tarjeta de crédito puede resultar útil utilizar la cantidad total retirada en operaciones durante la última hora, pero esa información no está presente en cada transacción, sino que hay que calcularla a partir de operaciones anteriores.
Por último, en muchos proyectos se requiere una tercera fase en la que debemos ser capaces de transmitir la información obtenida en el análisis de datos de manera efectiva. Esta tarea combina aspectos científicos en relación con la elaboración rigurosa de gráficas y diagramas con capacidades artísticas y de comunicación. Así, en un mundo con cada vez más presencia de datos en todos los niveles, la visualización efectiva resulta imprescindible para aprehender la realidad subyacente a los datos. Un excelente ejemplo de recopilación y visualización de datos es el proyecto Data USA7, una plataforma web con herramientas en JavaScript que recoge información de bases de datos públicas y las presenta de forma integrada a disposición de cualquier ciudadano de manera gratuita. Así, cualquier persona puede realizar sus propias visualizaciones de manera interactiva, lo que facilita entender el estado de cualquier aspecto socio-económico de esa nación.
Aprendizaje supervisado, no supervisado y por refuerzo
Como hemos indicado, los tres grandes paradigmas del aprendizaje automático son el supervisado, el no supervisado y el aprendizaje por refuerzo. Aunque los presentemos de manera diferenciada, en muchos problemas reales concurrirán varios de ellos junto con variantes intermedias. En general, en una aplicación concreta de ML la elección del modelo vendrá determinada fundamentalmente por la tipología de datos disponibles y, en menor medida, por los requisitos de eficiencia computacional (la memoria disponible, la necesidad de respuesta en tiempo real, etc.). También será relevante la naturaleza de la aplicación, fundamentalmente cómo de importante es que el modelo sea interpretable; es decir, si el objetivo es simplemente conseguir la mejor predicción posible, aunque usemos una caja negra o, por el contrario, debemos ser capaces de interpretar los parámetros del mismo.
En el caso supervisado se suministran pares de valores (Xi, Yi) i=1,…,N, donde X son las variables predictivas, Y representa las variables cuyos valores queremos predecir y N es el número de casos de los que disponemos. El problema consiste en ser capaz de predecir el valor de los datos Y dados los valores de X, es decir, aproximar la distribución de probabilidad condicionada p(Y|X). Si la variable Y es categórica, hablamos de un problema de clasificación, mientras que si es continua solemos decir que nos enfrentamos a un problema de regresión. Por ejemplo, si nos proporcionan los precios de venta de 100.000 viviendas, junto con características de cada una de ellas como su ubicación, la superficie o el año de construcción, podemos elaborar un modelo de regresión para poder predecir el precio de venta de otra vivienda, conocidas el resto de características. La empresa americana Zillow fue pionera en el uso de estos modelos para sus instrumentos de valoración; hoy en día, casi todos los portales inmobiliarios usan técnicas similares. Un ejemplo típico de clasificación es el asociado a los filtros antispam: las variables predictivas podrían incluir las palabras incluidas en el mensaje, la dirección del remitente, etc., y la variable a predecir es una etiqueta binaria que indica si el correo es no deseado (spam) o legítimo (ham).
En el aprendizaje no supervisado se suministran simplemente los valores de las variables observadas X, pero no disponemos de etiquetas o valores y. Se trata entonces de aprender cómo es la distribución de dichos datos, es decir, aproximar la distribución de probabilidad p(X) Basados en una aproximación de esta distribución (density estimation) podemos abordar problemas como detectar puntos que no parezcan haber sido generados por la misma distribución, esto es, datos anómalos (outlier detection), o bien detectar patrones de similaridad entre los mismos, agrupándolos en conjuntos de características similares (clustering). Un ejemplo consistiría en emplear los datos de interacción de los usuarios de una web (cuánto tiempo han permanecido en cada página, cuántos clics han hecho y dónde, etc.) para ser capaz de segmentar los potenciales clientes de dicha página en categorías como usuario experto, usuario nuevo, no humano (bot), etc.
En el aprendizaje supervisado siempre disponemos de una métrica para determinar la bondad de la predicción, pues podemos comparar los valores que predice el modelo con los valores observados. De hecho, como veremos más adelante, los parámetros del modelo se ajustan para optimizar una elección concreta de dicha métrica. Sin embargo, en el aprendizaje no supervisado no podemos evaluar de manera cuantitativa el rendimiento de los modelos. Quizás por este motivo se han desarrollado mucho más las técnicas para aprendizaje supervisado durante los últimos años. Una entidad bancaria que quiera desarrollar un sistema de detección de fraude en pagos con tarjeta electrónica tendrá resultados mucho mejores si dispone de los datos de transacciones (importe, lugar, tipo de comercio, hora, etc.) anotados como fraude/legítimo, que si dispone solo de los datos sin anotar.
Por último, el aprendizaje por refuerzo es el paradigma más flexible de ML. En él se simula la forma de aprender en mamíferos, con la que un agente puede interactuar con el medio realizando acciones que reciben cierta recompensa y transforman su estado. El objetivo es maximizar la recompensa esperada a largo plazo eligiendo en cada momento la acción más adecuada, teniendo en cuenta no solo la recompensa que se recibirá en dicho instante como resultado de la acción inmediata, sino también la secuencia de posibles estados y futuras recompensas. Este tipo de problemas requiere un equilibrio entre las denominadas “explotación” y “exploración” del conocimiento adquirido: la primera supondría escoger acciones que nos aporten la mayor recompensa inmediata, mientras que la segunda supone probar otras acciones que quizás nos aporten una mayor recompensa acumulada en el futuro. Quizás el mayor hito reciente de los algoritmos de aprendizaje por refuerzo ha sido en juegos de estrategia y, en particular, en el juego del Go, que por su complejidad se consideraba el caballo de batalla para los algoritmos de IA. El programa AlphaGo, desarrollado por Google Deep Mind, consiguió derrotar por primera vez al campeón mundial en marzo de 2016. El mejor algoritmo actual, AlphaGo Zero, ya no emplea datos de partidas anteriores ni ningún tipo de supervisión humana o conocimiento específico. El programa hace tabula rasa, con conocimiento solo de las reglas del juego, y explora estrategias alcanzando un nivel superior al de los humanos en pocas horas a base de jugar contra sí mismo. Tras muchas partidas jugadas, la señal de refuerzo (partida ganada o perdida) se propaga para conseguir una evaluación adecuada de la fortaleza de una posición y, por tanto, de la jugada que se ha de efectuar. Los modelos de aprendizaje profundo por refuerzo (Deep RL), que están en la base del algoritmo de AlphaGo, tendrán sin duda un importante desarrollo en el futuro.
En tareas más generales que los juegos de estrategia, uno de los retos principales de la investigación radica en cómo fijar un buen sistema de recompensas para lograr que un agente aprenda a realizar la acción deseada. En un programa de ajedrez, la recompensa ha de ser únicamente por ganar la partida, ya que fijar recompensas por captura de piezas como hito intermedio puede conducir a estrategias que, a pesar de capturar muchas de ellas, terminen por perder la misma. En problemas complejos, un algoritmo de aprendizaje por refuerzo puede buscar estrategias para resolver la tarea deseada realizando acciones que tengan consecuencias no previstas o incluso peligrosas. El desarrollo de algoritmos robustos de aprendizaje por refuerzo que reúnan todos los requisitos de seguridad necesarios para su puesta en marcha en tareas cotidianas es uno de los campos abiertos más importantes en inteligencia artificial.
Entrenamiento, validación y test
Nos centraremos en este epígrafe en problemas de aprendizaje supervisado para describir el ciclo típico de elaboración de un modelo, comentando algunas de las características comunes de los problemas de aprendizaje estadístico. Los modelos estadísticos de tipo paramétrico suelen aproximar la distribución de probabilidad p(Y|X) a través de familias de distribuciones indexadas por parámetros, intentándose fijar el valor de estos parámetros de manera que la distribución obtenida explique adecuadamente los datos observados. Este proceso de ajuste se conoce como aprendizaje en el contexto de ML. Para ello hemos de ser capaces de estimar dichos parámetros a partir de un conjunto de datos y luego evaluar el modelo resultante sobre otro conjunto de datos obtenido a partir de la misma distribución.
Por este motivo, el conjunto de datos observados suele dividirse en tres subconjuntos denominados, respectivamente, de “entrenamiento”, de “validación” y de “test”. La manera en que se hace esta división puede depender de la aplicación específica —por ejemplo si se han de tomar en consideración aspectos temporales—, pero pensemos por el momento que el conjunto original se divide de manera puramente aleatoria. Utilizamos el conjunto de entrenamiento para entrenar un modelo de nuestra elección: mostraremos todos los datos de este conjunto al modelo para fijar el valor de sus parámetros libres. Esto supone la optimización de una función de coste que mide cuán distantes están las predicciones del modelo de los datos observados e intenta ajustar los parámetros para que este error sea lo menor posible. Con el modelo entrenado podemos evaluar su rendimiento sobre otro conjunto de datos, diferente del que hemos utilizado en esta fase, pero procedente de la misma distribución.
Figura 2
Dependencia del error con la complejidad del modelo y sobreajuste.

Observemos, sin embargo, que en realidad no tenemos por qué limitarnos a un único modelo, sino que ajustaremos distintos con diferentes arquitecturas o características, todos ellos sobre el conjunto de entrenamiento y realizando pruebas sobre el conjunto de validación para seleccionar el mejor de ellos (model selection). Por último, el mejor modelo se evaluará sobre un tercer conjunto de datos no utilizado hasta el momento para tener una estimación fiable de su rendimiento final. Un error frecuente en la construcción de modelos es emplear información sobre el conjunto final de test en la elaboración del modelo (data leakage), lo que puede conducir a obtener resultados mejores de los que se conseguirían cuando el modelo se ponga en producción. Como buena práctica, repetiremos la división del conjunto de datos original en distintos subconjuntos de entrenamiento, validación y test, repitiendo todo el proceso para disponer de una estimación más robusta del rendimiento final.
Si representamos el error cometido por el modelo en los conjuntos de entrenamiento y de test nos encontraremos muchas veces con una situación como la descrita en la figura 2. Empleando modelos más flexibles y expresivos —es decir, con mayor capacidad para ajustar los datos, por ejemplo porque incluyen una mayor cantidad de parámetros ajustables— podemos llegar a reducir el error de entrenamiento tanto como queramos. Sin embargo, suele comprobarse que los modelos tan complejos no generalizan bien; esto es, su predicción es mucho peor sobre nuevos ejemplos de la misma distribución, por lo que crece el error en el conjunto de test. En una situación como esta decimos que el modelo sobreajusta los datos (overfitting). Por este motivo hemos de escoger modelos más parsimoniosos en los que se encuentre un equilibrio entre la capacidad de ajuste a los datos y la capacidad de generalización.
Figura 3
Frontera de decisión en un problema de clasificación binaria. De izquierda a derecha: infrajuste (λ alto), óptimo y sobreajuste (λ bajo).

Una forma de lograr este equilibrio es introducir un término en la función de coste que penalice la complejidad del modelo, lo que se consigue típicamente añadiendo un término proporcional al tamaño de los coeficientes con una constante de proporcionalidad. Esta técnica de regularización permite alcanzar el equilibrio mencionado anteriormente: con valores bajos de la constante conseguimos modelos más flexibles aumentando el riesgo de sobreajuste, mientras que valores muy altos de la misma producen modelos demasiado sencillos que no llegarán a ajustar bien los datos de entrenamiento, como se ilustra en la figura 3. El valor óptimo del parámetro de regularización se fija experimentalmente, probando modelos con diferentes valores sobre el conjunto de validación y seleccionando el mejor valor. Por este motivo, tal constante se suele denominar “hiperparámetro”.
Existen numerosos algoritmos y modelos de aprendizaje supervisado, de forma que incluso una descripción meramente superficial de todos ellos excedería nuestros objetivos en este libro. Nos conformaremos con presentar las características generales de las principales clases de algoritmos. El lector interesado puede aprender más consultando la información final del capítulo. Una excepción al comentario anterior son los algoritmos de redes neuronales profundas (deep learning), que por su importancia reciente merecen una descripción más detallada en el siguiente epígrafe.
Para concluir esta discusión, y teniendo en cuenta la gran cantidad de modelos posibles, podemos preguntarnos cuál es el que más nos conviene utilizar. Esta pregunta aparentemente inocente puede tener respuestas más o menos elaboradas. Una respuesta sencilla podría ser: si disponemos de suficientes datos de entrenamiento, la mejor elección será probablemente un modelo de redes neuronales profundas. En efecto, sobre datos estándar como imágenes, texto escrito por humanos, etc., las redes neuronales profundas superan a muchos otros algoritmos en tareas como clasificación de imágenes, detección de objetos, clasificación de texto o traducción automática. Sin embargo, un resultado conocido popularmente como el teorema “no free lunch” (Wolpert, 1996) nos recuerda que no existe un único modelo capaz de superar sistemáticamente a otro sobre todas las posibles distribuciones de datos. Es decir, la elección concreta del mejor modelo depende de cómo sean los datos y la tarea a realizar.
Aprendizaje profundo
El conjunto de modelos conocido colectivamente como de aprendizaje profundo (deep learning) supone un claro ejemplo de rebranding científico y ha marcado el renacer de una disciplina que ha presentado, desde su inicio en los años sesenta del pasado siglo, fases como la actual, de enorme actividad, alternadas con otras de menor interés por parte de la comunidad científica especializada. En esencia, los modelos de aprendizaje profundo son modelos muy flexibles que pueden llegar a tener cientos de miles de parámetros ajustables y son, por tanto, capaces de aprender distribuciones en espacios de dimensión alta para realizar tareas complejas. Otra característica es que al estar dichos parámetros distribuidos por capas, la red aprende conceptos en diferentes grados de abstracción de manera jerárquica. El auge actual de este tipo de modelos se debe, fundamentalmente, a dos motivos: la disponibilidad de grandes conjuntos de datos anotados para entrenamiento y el aumento de la potencia computacional, además de otros factores técnicos que trataremos más adelante.
Como hemos comentado anteriormente, un modelo con muchos parámetros ajustables precisa gran cantidad de ejemplos para su entrenamiento con el fin evitar problemas de sobreajuste. En tareas de clasificación de imágenes, la base de datos de ImageNet contiene 14 millones de estas anotadas por humanos, con varios cientos de imágenes para cada categoría típica como “espada” o “melocotón”. De entre ellas, al menos un millón contienen, además, la localización del objeto dentro de la imagen (Bounding Box), necesaria para entrenar modelos de detección de objetos. Cada año, la competición ImageNet Large Scale Visual Recognition Challenge (ILSVC) pone a prueba los mejores algoritmos (casi todos basados en redes neuronales, especialmente de unos años a esta parte) para clasificar imágenes de objetos en 1.000 categorías, entre ellas 90 razas de perros. Los algoritmos actuales superan ya la capacidad humana: la red que venció la competición en 2017 (Hu, 2018) tenía un error top-5 (el número de veces que la categoría correcta no se encuentra entre las 5 más probables) de 2,25%, mientras que la capacidad humana se estima que tiene un error top-5 de 5% para la misma tarea (Russakovsky, 2015).
Los modelos complejos necesitan grandes cantidades de datos anotados con etiquetas, pero ¿cómo podemos obtener dichos datos? Algunos datos generados por aplicaciones incorporan las etiquetas de manera automática por el propio dispositivo que los produce: por ejemplo, los tuits contienen datos de geolocalización, lenguaje o edad del emisor, y mucha de la información que se genera en redes sociales es anotada por los propios usuarios sin que estos sean plenamente conscientes de ello. Además, existen plataformas donde se generan bases de datos anotadas para tareas específicas; de entre ellas la más conocida probablemente sea Amazon Mechanical Turk8. Esta plataforma de crowdsourcing permite a personas de todo el mundo realizar tareas que requieran inteligencia humana para anotar datos, a cambio de una modesta remuneración por el tiempo empleado.
El segundo factor que ha permitido el desarrollo de las redes neuronales profundas han sido los avances constantes en la capacidad de computación, necesarios para ser capaces de procesar las ingentes cantidades de datos necesarias para entrenar dichos modelos, así como el desarrollo de algoritmos que lo posibilitan, en particular los denominados “algoritmos estocásticos de descenso del gradiente”.
Figura 4
Arquitectura esquemática de una red neuronal (perceptrón multicapa).
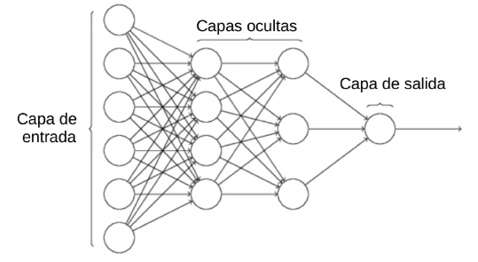
Sin entrar en detalles matemáticos, podemos dar algunas ideas sobre cómo funciona una red neuronal profunda. En la figura 4 se presenta esquemáticamente la arquitectura de una red con cuatro capas. En la capa de entrada (input layer) se introduce un vector de datos correspondiente a cada ejemplo del conjunto de entrenamiento. Si se tratase de una imagen en color, la capa de entrada tomaría el valor de cada uno de los píxeles en los tres canales RGB (rojo, verde, azul; por sus siglas en inglés); si fuera un texto, su codificación en un alfabeto, etc. En cada nodo de la primera capa se calcula una suma ponderada de los valores de la capa de entrada y el resultado se pasa a través de una función de transferencia. Estas operaciones están inspiradas en el funcionamiento de las neuronas del sistema nervioso, que captan información de muchas otras neuronas y, en el momento en que la suma de todos los estímulos excede cierto umbral, transmiten el impulso nervioso a través de su axón. El proceso se repite en cada capa, que toma como entrada la salida de la capa anterior. Por último, en la última capa la salida es un único vector de M componentes —si se trata de un problema de clasificación en M clases9— que expresa la probabilidad de que la imagen de entrada pertenezca a cada una de las clases. Los parámetros ajustables del modelo son las matrices de pesos en cada capa y dichos pesos se ajustan de la siguiente manera: en la propagación directa (forward-prop) se emplean los pesos aprendidos hasta el momento para predecir un vector de probabilidades, dicho vector se compara con el valor real de la clase a la que pertenece la imagen y el proceso se repite sobre todos los ejemplos de entrenamiento, llegando a una medida del error promedio en la predicción. En el proceso inverso (back-prop) se actualizan los pesos usando el gradiente de la función objetivo. El ciclo se repite hasta conseguir la convergencia en la función de error y, por tanto, conseguir que la red haya aprendido a clasificar correctamente diferentes imágenes incurriendo en el mínimo error. Una vez la red ha sido entrenada, la predicción es muy rápida sobre cada nuevo ejemplo; sin embargo, el proceso de entrenamiento de redes de grandes dimensiones requiere cálculos intensivos sobre gran cantidad de datos.
En los últimos años ha proliferado el uso de bibliotecas de software como TensorFlow, Torch, Keras o Theano para programar modelos de redes neuronales en apenas 20 líneas de código. Estas bibliotecas (frameworks) contienen todas las funciones de alto nivel y están diseñadas para paralelizar la computación en el proceso de entrenamiento, en el que los pesos se actualizan tras procesar un pequeño subconjunto (batch) de los datos de entrenamiento. Dado que la mayor parte de cálculos necesarios consiste en multiplicar matrices o tensores de gran tamaño, desde hace unos años se utilizan tarjetas gráficas de propósito general (GPU) para el entrenamiento de redes profundas, pues contienen miles de pequeños procesadores que posibilitan un gran paralelismo en la computación10.
Algunos campos de aplicación del aprendizaje automático
Aunque en los siguientes capítulos abordaremos el impacto de la ciencia de datos y la IA en diversos ámbitos de la sociedad, querríamos cerrar este capítulo con una breve enumeración de los principales campos de desarrollo de esta disciplina.
Visión artificial
Este campo recoge toda la tecnología desarrollada para adquirir, procesar, analizar y entender imágenes de manera automática, habilitando a un sistema informático para desarrollar tareas propias de esta capacidad humana. La visión artificial es un campo multidisciplinar donde confluyen, entre otras, la óptica, el procesamiento de señales, la electrónica, la estadística y la IA. Algunas de las tareas más comunes en este campo son:
La clasificación de imágenes en categorías prefijadas.
La descripción en lenguaje natural del contenido de una imagen (image tagging).
La búsqueda de imágenes por contenido.
El reconocimiento facial.
La detección de objetos y su localización en el interior de una imagen.
La reconstrucción de imágenes 3D a partir de imágenes 2D.
El reconocimiento óptico de caracteres escritos (OCR).
El análisis de movimiento en vídeo.
Las aplicaciones de estas técnicas son innumerables, incluyendo el control de calidad en procesos industriales, el desarrollo de apps que proporcionan descripciones sonoras para ayuda a invidentes, la provisión de técnicas para imagen médica y ayuda al diagnóstico en medicina, el procesamiento automático de vídeo en cámaras CCTV, el desarrollo de sistemas de navegación en conducción autónoma, la identificación biométrica por reconocimiento del iris, la realidad aumentada, el control de cultivos en agricultura de precisión, el procesamiento de imágenes por satélite y un largo etcétera.
Procesamiento del lenguaje natural
Desde el advenimiento de los modelos de lenguaje basados en redes neuronales, uno de los campos que está experimentando mayor desarrollo en los últimos años es el procesamiento del lenguaje natural. Si en el origen de esta disciplina tuvieron más peso los modelos formales de lenguaje, como las gramáticas libres de contexto de Chomsky, cuyo objetivo era capturar la generación de lenguaje mediante un conjunto de reglas, en la actualidad se están imponiendo modelos estadísticos y de ML. En ellos, la representación de la estructura del lenguaje es menos interpretable, pero son capaces de realizar tareas cada vez más complejas, entrenando modelos de redes profundas sobre millones de textos. Esta transición está resumida en la famosa frase atribuida a Jelinek, director del grupo de investigación en lenguaje del Thomas J. Watson IBM Research Center y uno de los pioneros en procesamiento del lenguaje natural: “Cada vez que despedimos a un lingüista, mejora el rendimiento de nuestro clasificador”. Enseñar a una máquina a entender nuestro lenguaje puede ser muy diferente a cómo nosotros mismos lo entendemos. Las tareas más comunes en este campo son:
La clasificación de textos.
El reconocimiento de entidades nombradas.
La síntesis del habla (text-to-speech).
El reconocimiento del habla (speech recognition).
Los sistemas de diálogo y respuesta a preguntas (Siri, Alexa, etc.).
La traducción automática.
El resumen automático de textos.
El análisis morfológico y sintáctico (POS tagging).
Las herramientas de procesamiento del lenguaje natural se usan también para el análisis de sentimientos y opiniones en redes sociales, la indexación y la extracción de información en bases de datos jurídicas y de salud, el diseño de asistentes en servicio al cliente; y se integran como un elemento más en un número cada vez mayor de aplicaciones, como por ejemplo en los robots sociales Aisoy. Los primeros dispositivos electrónicos para traducir lenguaje hablado en conversaciones en tiempo real empiezan a verse ya en el mercado.
Inteligencia de negocio
Dentro de la inteligencia de negocio se engloban todas las estrategias, los productos, las tecnologías y los datos que una empresa utiliza para mejorar su visión sobre los procesos que intervienen en sus áreas de negocio. En sus modelos confluyen, además de la ciencia de datos y la IA, conocimientos sobre economía, teoría de juegos, investigación operativa, psicología, mercadotecnia o sociología, entre muchos otros.
Uno de los ejemplos más famosos fue la competición lanzada por Netflix en 2006 (por entonces apenas conocida en España) para predecir las evaluaciones de sus usuarios sobre algunas películas, conociendo las evaluaciones que habían realizado sobre otras. El concurso otorgaba un suculento premio de un millón de dólares para el algoritmo con mejor eficiencia en su predicción, si conseguía superar al empleado por la compañía. Este tipo de algoritmos, llamados “sistemas de recomendación”, están en la base del negocio de grandes corporaciones como Amazon, Netflix o Spotify. En la actualidad están siendo adoptados por la mayoría de comercios para afinar los productos que ofrecen a cada uno de sus clientes.
La experiencia de la competición de Netflix tuvo un éxito considerable y motivó la creación de Kaggle, el portal web más frecuentado por los científicos de datos. En Kaggle se reproduce la experiencia de Netflix y compañías, organismos de investigación y diversas entidades publican sus datos en competiciones para mejorar sus algoritmos predictivos. El efecto que estas competiciones han tenido sobre el desarrollo de los algoritmos de aprendizaje supervisado es difícilmente exagerable11.
Las grandes compañías de telecomunicaciones, de seguros o de banca disponen también de sistemas predictivos para estudiar el comportamiento de sus clientes y anticipar cuándo tienen intención de darse de baja de sus servicios. Los denominados sistemas anti-churn elaboran ofertas especializadas para retener clientes que manifiestan síntomas de descontento con el servicio. La mayor parte de estos sistemas están basados en algoritmos de aprendizaje supervisado sobre datos estructurados; es decir, aprenden sobre el comportamiento de los clientes para elaborar estrategias comerciales adecuadas a sus objetivos.
El conocimiento detallado de las preferencias de consumo y hábitos de vida de las personas, captados a través de su interacción con dispositivos electrónicos, supone una información muy valiosa para el desarrollo de todo tipo de aplicaciones comerciales. Se podría decir que hoy en día el gigante Amazon ya no es una empresa de logística sino, más bien, una empresa de información cuyo principal valor son los datos recopilados sobre sus clientes y sus algoritmos de IA para extraer valor de ellos.
Como se comentará en capítulos posteriores, la industria de la publicidad online, a través del llamado “marketing de precisión”, es uno de los principales motores del desarrollo de algoritmos de IA y ciencia de datos, como se manifiesta a través del complejo ecosistema de empresas que intervienen en el mercado de medios.
Para saber más
Hemos proporcionado una breve introducción a los conceptos algorítmicos y metodológicos básicos de la estadística y el aprendizaje automático relevantes para predicción y aprendizaje en problemas big data. Existe cierto debate sobre la esencia de ambas disciplinas y su rol en la era de la ciencia de datos y la IA (véanse Dunson, 2018; Donoho, 2015, para más información) que hemos soslayado aquí adoptando una postura pragmática. Además nos hemos centrado en métodos basados en maximización de la verosimilitud (tal vez junto a un regularizador) sin hacer referencia a métodos bayesianos descritos en Gelman et al. (2013) y French y Ríos Insua (2000), pues aún no están suficientemente desarrollados para problemas de gran dimensión, salvo a través de las aproximaciones variacionales.
Pueden verse detalles completos sobre los métodos introducidos en Hastie et al. (2009), Bishop (2006) y Goodfellow et al. (2018). Además, son numerosos los cursos disponibles en sistemas como Coursera, Udacity o Udemy. También hay excelente documentación en la librería Scikit-learn de ML de Python, donde muchos de estos métodos están implementados. Los aspectos de visualización pueden verse en textos comoel de Cairo (2012).
Es evidente el valor que la recopilación, el tratamiento y el análisis de datos puede aportar a la actividad empresarial y política, y por este motivo existe una fuerte demanda para incorporar personal con perfil de científico de datos a las plantillas de las empresas. Pero también es cierto que algunas prácticas pueden vulnerar la privacidad y plantean problemas éticos y legales, como discutiremos en el capítulo 7. En este punto, cerramos este capítulo con una breve reflexión sobre la IA: ¿es su objetivo aprender y reproducir el comportamiento racional o el comportamiento humano? Esta cuestión va más allá de los temas que podemos tratar en este libro, pero animamos al lector interesado a reflexionar sobre ella.